文章声明:本内容为个人的业余研究,和任何单位,机构没有关系,文章出现的股票代码,全部只是测试例子,不做投资参考,投资有风险,代码学习使用,不做商业用途
本文利用全球动量模型策略回测,设置原理,选择几个相关性特别低的标的建立组合
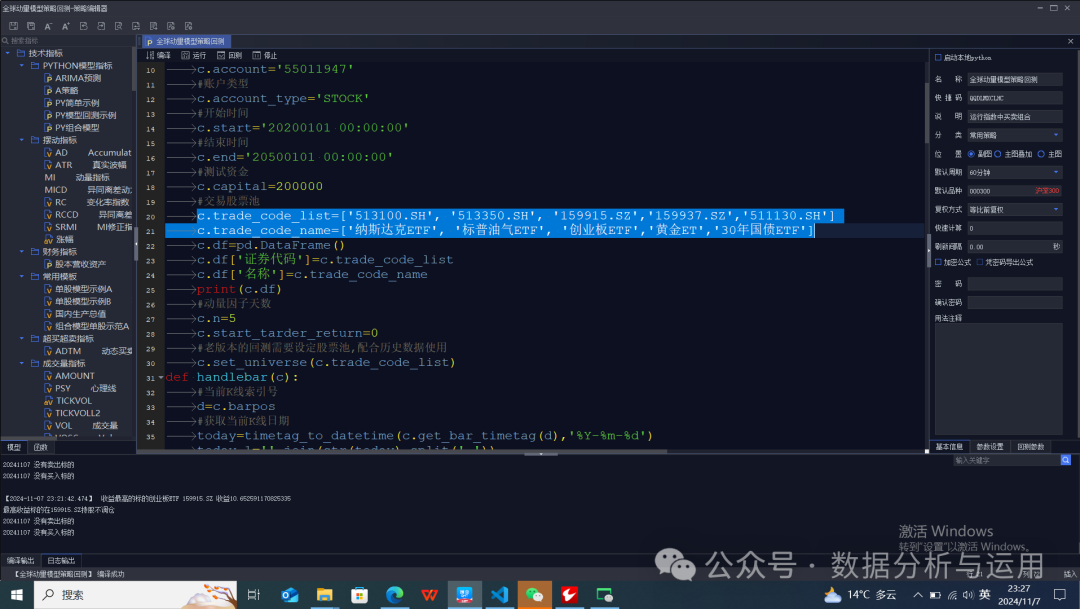
c.trade_code_list=['513100.SH', '513350.SH', '159915.SZ','159937.SZ','511130.SH']c.trade_code_name=['纳斯达克ETF', '标普油气ETF', '创业板ETF','黄金ET','30年国债ETF']
利用5日动量收益做为排序因子
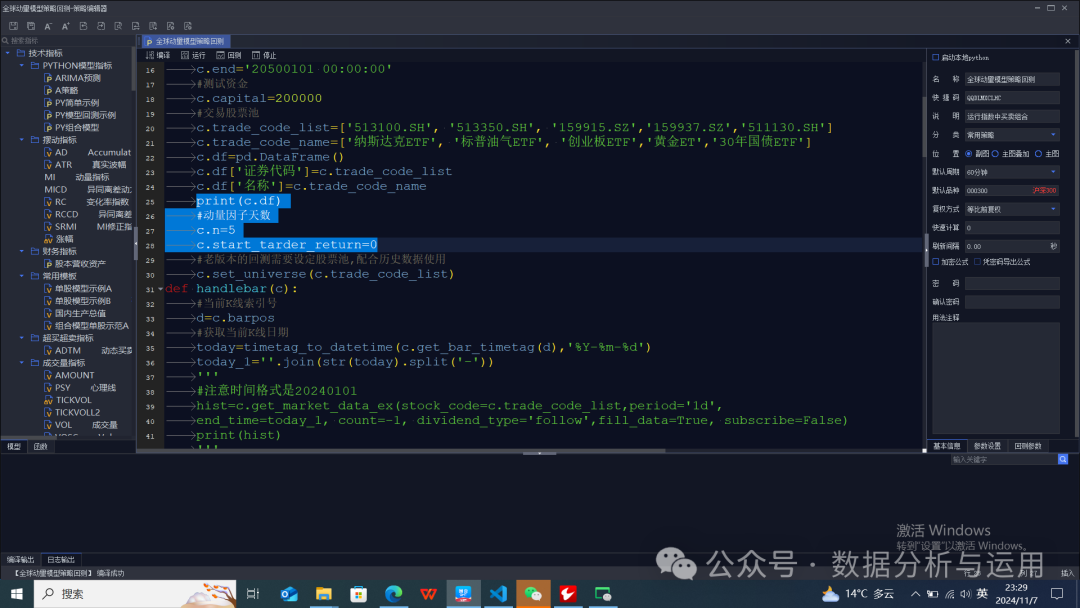
交易原理如果股票池最高的,开仓的条件收益大于0就开仓,不然就全部卖出,空仓
调仓的原理,如果最高收益的标的在持股里面就持股,不然就是卖出全部标的,买入收益最高的标的
点击回测开始回测,可以设置回测参数
点击回测按钮
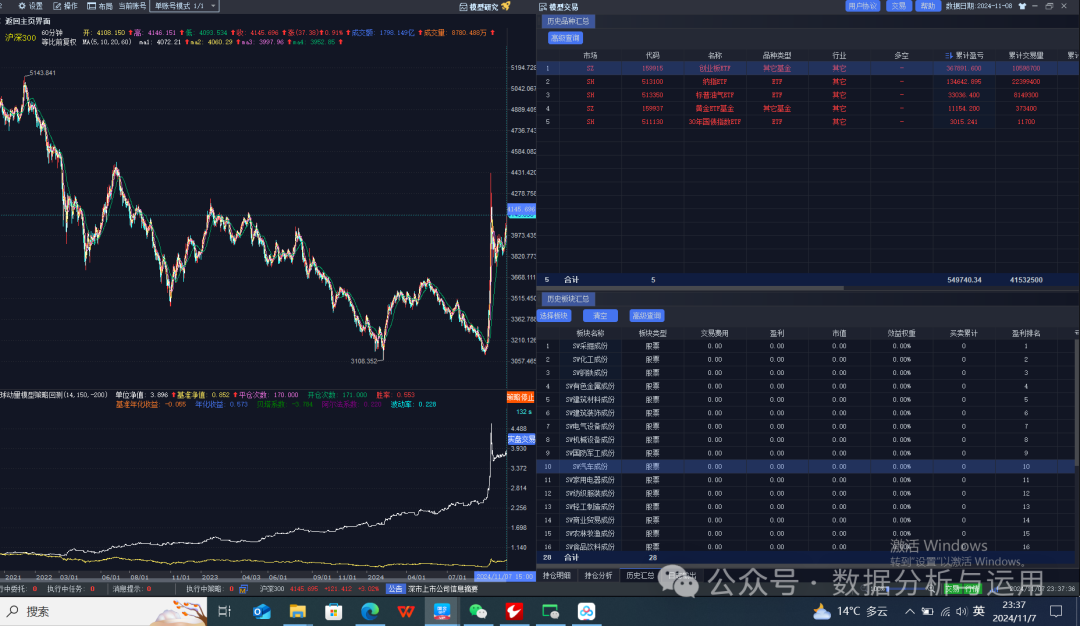
回测的结果
年化57%
全部的回测代码,当然我也有实盘的代码
#encoding:gbk'''全球动量模型策略回测作者:小果'''import pandas as pdimport numpy as npimport talibdef init(c):#账户c.account='55011947'#账户类型c.account_type='STOCK'#开始时间c.start='20200101 00:00:00'#结束时间c.end='20500101 00:00:00'#测试资金c.capital=200000#交易股票池c.trade_code_list=['513100.SH', '513350.SH', '159915.SZ','159937.SZ','511130.SH']c.trade_code_name=['纳斯达克ETF', '标普油气ETF', '创业板ETF','黄金ET','30年国债ETF']c.df=pd.DataFrame()c.df['证券代码']=c.trade_code_listc.df['名称']=c.trade_code_nameprint(c.df)#动量因子天数c.n=5c.start_tarder_return=0#老版本的回测需要设定股票池,配合历史数据使用c.set_universe(c.trade_code_list)def handlebar(c):#当前K线索引号d=c.barpos#获取当前K线日期today=timetag_to_datetime(c.get_bar_timetag(d),'%Y-%m-%d')today_1=''.join(str(today).split('-'))'''#注意时间格式是20240101hist=c.get_market_data_ex(stock_code=c.trade_code_list,period='1d',end_time=today_1, count=-1, dividend_type='follow',fill_data=True, subscribe=False)print(hist)''''''get_history_data(len, period, field, dividend_type = 0,skip_paused = True)'''#'''默认参数,除复权,默认不复权,可选值包括:0:不复权1:向前复权2:向后复权3:等比向前复权4:等比向后复权'''#必须使用前复权#hist=c.get_history_data(100,'1d',['open','close','low','high'],1)df=c.dfreturn_list=[]hold_stock=get_position(c,c.account,c.account_type)if hold_stock.shape[0]>0:hold_stock_list=hold_stock['证券代码'].tolist()else:hold_stock_list=[]for stock,name in zip(c.trade_code_list,c.trade_code_name):try:hist=c.get_market_data_ex(fields=[],stock_code=[stock],period='1d',start_time=str(c.start)[:8],end_time=today_1,count=-1,fill_data=True,subscribe=True)hist=hist[stock]close_list=hist['close'].tolist()[-c.n:]zdf=((close_list[-1]-close_list[0])/close_list[0])*100return_list.append(zdf)except:passreturn_list.append(-1)df['收益']=return_listdf['时间']=today_1df=df.sort_values(by='收益',ascending=True)max_stock=df['证券代码'].tolist()[-1]stock=max_stockmax_name=df['名称'].tolist()[-1]max_return=df['收益'].tolist()[-1]print('收益最高的标的{} {} 收益{}'.format(max_name,max_stock,max_return))if max_return>c.start_tarder_return:if max_stock in hold_stock_list:print('最高收益标的在{}持股不调仓'.format(stock))buy_df=pd.DataFrame()sell_df=pd.DataFrame()else:print('最高收益标的不在{}持股调仓,卖出全部持股,买入最高收益'.format(stock))buy_df=pd.DataFrame()buy_df['证券代码']=[max_stock]buy_df['名称']=[max_stock]buy_df['收益']=[max_return]sell_df=hold_stockelse:print('收益最高的标的{} {} 收益{}小于0 卖出全部空仓'.format(max_name,max_stock,max_return))buy_df=pd.DataFrame()sell_df=hold_stockif sell_df.shape[0]>0:for stock in sell_df['证券代码'].tolist():order_target_percent(stock, 0, c, c.account)print('{} 卖出标的{}'.format(today_1,stock))else:print('{} 没有卖出标的'.format(today_1))if buy_df.shape[0]>0:for stock in buy_df['证券代码'].tolist():order_target_percent(stock, 1, c, c.account)print('{} 买入收益最高的标的{}'.format(today_1,stock))else:print('{} 没有买入标的'.format(today_1))#获取账户总权益m_dBalancedef get_account(c,accountid,datatype):'''获取账户数据'''accounts = get_trade_detail_data(accountid, datatype, 'account')result={}for dt in accounts:result['总资产']=dt.m_dBalanceresult['净资产']=dt.m_dAssureAssetresult['总市值']=dt.m_dInstrumentValueresult['总负债']=dt.m_dTotalDebitresult['可用金额']=dt.m_dAvailableresult['盈亏']=dt.m_dPositionProfitreturn result#获取持仓信息{code.market:手数}def get_position(c,accountid,datatype):'''获取持股数据'''positions = get_trade_detail_data(accountid,datatype, 'position')data=pd.DataFrame()if len(positions)>0:df=pd.DataFrame()for dt in positions:df['股票代码']=[dt.m_strInstrumentID]df['市场类型']=[dt.m_strExchangeID]df['证券代码']=df['股票代码']+'.'+df['市场类型']df['证券名称']=[dt.m_strInstrumentName]df['持仓量']=[dt.m_nVolume]df['可用数量']=[dt.m_nCanUseVolume]df['成本价']=[dt.m_dOpenPrice]df['市值']=[dt.m_dInstrumentValue]df['持仓成本']=[dt.m_dPositionCost]df['盈亏']=[dt.m_dPositionProfit]data=pd.concat([data,df],ignore_index=True)else:data=pd.DataFrame()return data






