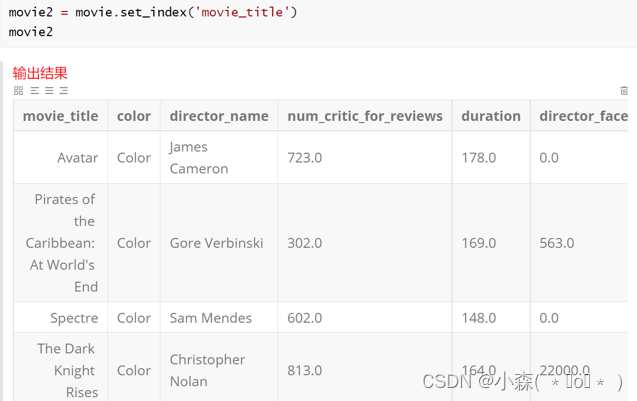
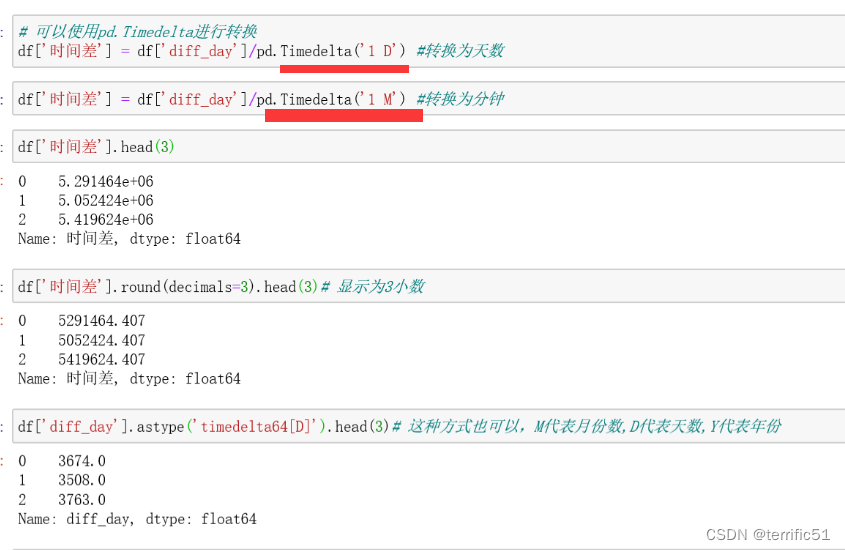
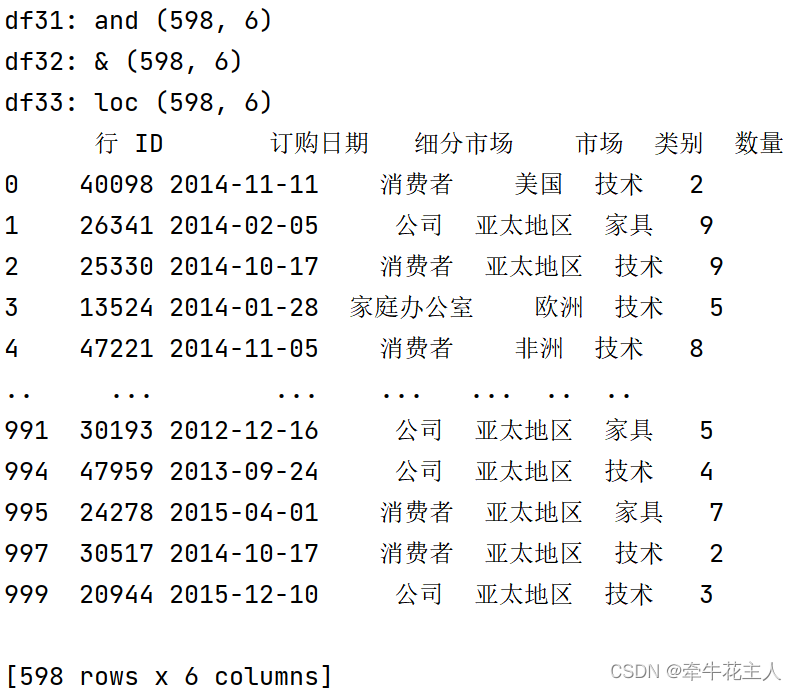
postman
机制与策略
驱动程序
kmeans
应届生就业
概率论
类型转换
批量
Java并发
医学统计学
程序
CLIP
pyqt
程序员40
机顶盒ROM
自由工作
前置++和后置++
光照度传感器
IDEA 常用插件
因果AI
pandas
2024/4/11 12:44:19

使用 dateutil.parser将时间字符串解析出时间对象datetime
假设以下数据集robbery: 对incidentdatetime列进行转换
from dateutil.parser import *
robbery[incidentdatetime] robbery.incidentdatetime.apply(lambda x:parse(x))
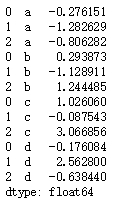
pandas层级索引
pandas层级索引
import pandas as pd
import numpy as npser_obj pd.Series(np.random.randn(12),index[[a, a, a, b, b, b, c, c, c, d, d, d],[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]])
print(ser_obj)运行结果: multiindex对象 print(type(ser_obj.index))
pri…
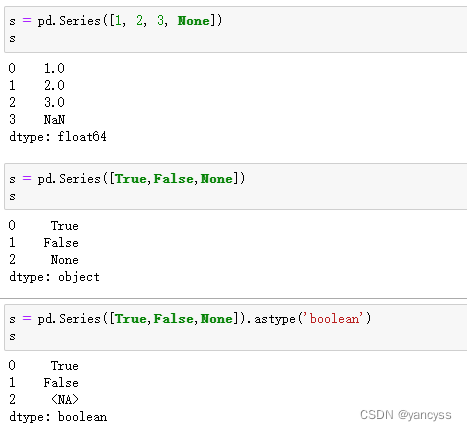
Pandas数据分析教程-数据清洗-扩展数据类型
pandas-02-数据清洗&预处理 扩展数据类型1. 传统数据类型缺点2. 扩展的数据类型3. 如何转换类型文中用S代指Series,用Df代指DataFrame 数据清洗是处理大型复杂情况数据必不可少的步骤,这里总结一些数据清洗的常用方法:包括缺失值、重复值、异常值处理,数据类型统计,分…
Python pandas dataframe 日期时间列中提取月份和年份
创建于:20210716 修改于:20210716 文章目录1、pandas.Series.dt.year 和 pandas.Series.dt.month 方法提取月份和年份2、strftime() 方法提取年份和月份3、pandas.DatetimeIndex.month 和 pandas.DatetimeIndex.year 提取年份和月份4、参考资料1、pandas…
pd.to_datetime
crime.Year int64
pd.to_datetime(crime.Year,format %y%m%d)crime.Year datetime64
Pandas resample重采样及freq用法
DataFrame.resample(rule, howNone, axis0, fill_methodNone, closedNone, labelNone, conventionstart,kindNone, loffsetNone, limitNone, base0)参数 说明
freq 表示重采样频率,例如‘M’、‘5min’,Second(15)
how‘mean’ 用于产生聚合值的函数名或…
Pandas模块之DataFrame:01-基本概念及创建
"二维数组"Dataframe:是一个表格型的数据结构,包含一组有序的列,其列的值类型可以是数值、字符串、布尔值等。Dataframe中的数据以一个或多个二维块存放,不是列表、字典或一维数组结构。
DataFrame带有index࿰…
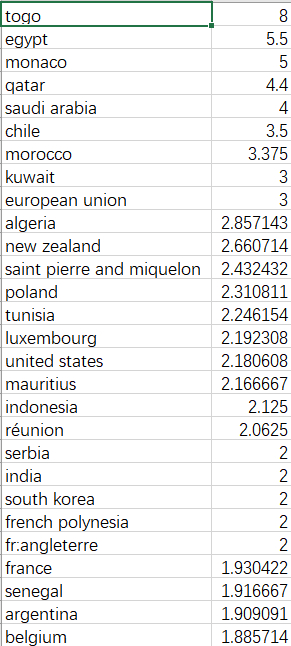
Python数据分析:pandas数据操作和分析案例
Python数据分析:pandas数据操作和分析案例
项目介绍:
https://www.kaggle.com/openfoodfacts/world-food-facts
项目任务:
统计各个国家食物中的食品添加剂种类个数
import zipfile
import os
import pandas as pd
import matplotlib.py…
pandas分组与聚合
pandas分组与聚合
分组(groupby): 对数据集进行分组,然后对每组进行统计分析 SQL能够对数据进行过滤,分组聚合 pandas能利用groupby进行更加复杂的分组运算 分组运算过程 split(拆分)&#…
pandas教程:Time Zone Handling 时区处理
文章目录 11.4 Time Zone Handling(时区处理)1 Time Zone Localization and Conversion(时区定位和转换)2 Operations with Time Zone−Aware Timestamp Objects(时区的操作-意识到时间戳对象)3 Operations…

【Pandas与SQL系列】Pandas实现分布函数percent_rank、cume_dist
目录 1,分布函数,1.1,percent_rank()1.2,cume_dist()1.3 SQL例子 2,Pandas 实现3,补充Pandas实现排序 1,分布函数,
应用场景:快速查看某个记录所归属的组内的比例 分布函数分类及基础语法&…

pandas 获取一段时间内每个月的最后一个工作日和日历日
获取一段时间内每个月的最后一个工作日
endlistpd.date_range(start‘2023-01-01’, end‘2023-09-30’, freq‘BM’).strftime(“%Y-%m-%d”).to_list() 获取一段时间内每个月的最后一个日历日
endlistpd.date_range(start‘2023-01-01’, end‘2023-09-30’, freq‘M’).st…
两步实现Pandas合并相同索引行的秘籍
在Pandas处理数据的过程中,我们常常会遇到需要对相同索引行进行汇总和统计的情况。那么如何高效地实现DataFrame相同索引行的合并呢?
在Pandas中,可以使用.groupby()和.agg()方法合并相同索引行。 例如,有这样一张DataFrame: da…

python 读写csv文件方法
csv是一种结构化文件,可以将文本转化成矩阵的形式,方便程序读取和处理。下面来介绍一下使用 python读写 csv文件的方法: 1.首先需要使用 pip安装 python包,然后将 csv文件解压到一个文件夹下 2.使用 pip安装 python包,…

【pandas读入数据报错】OSError: Initializing from file failed
问题描述:
pandas载入csv格式数据报错
B pd.read_csv("C:/Users/hp/Desktop/动手学数据分析/第一单元项目集合/train.csv")
B.head(3)报错:
OSError: Initializing from file failed原因分析:
调用pandas的read_csv()方法时&a…
数据挖掘基础知识储备——Pandas
Python之所以对处理数据非常方便,不得不说Numpy与Pdndas功不可没~ 本篇博客将总结所有关于数据挖掘中常用到的pandas的使用方法,阅读好的代码往往有利于代码的书写和方便他人阅读,这是一个很好的习惯呀~ 推荐Pandas中文…
Pandas 数据分析系列1--SeriesDataFrame数据结构详解
Pandas 概述 Pandas 是一个开源的数据分析和数据处理库,是基于 NumPy 开发的。它提供了灵活且高效的数据结构,使得处理和分析结构化、缺失和时间序列数据变得更加容易。其在数据分析和数据处理领域广泛应用,在金融、社交媒体、科学研究等领域都有很高的使用率和广泛的应用场…
【Python】pandas获取全省人口数据并作可视化分析
前言
今天我们看看自己所在的省份的人口人数,使用pandas并作可视化分析。
环境使用
python 3.9pycharm
模块使用
pandasPandas 是基于NumPy的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供…

利用python中的pandas和matplotlib进行电影数据分析
项目案例
数据集介绍
电影数据集百度云链接 提取码: 4anq 这是一份好莱坞电影数据,有28个特征,五千多个样本,特征有电影时长、导演、票房、语言、评分等,样本中有缺失值,需要进行处理。 项目任务
查看票房收入统计 …
如何使用python的 Pyecharts库 制作 GDP 动态柱状图?
部分数据来源:ChatGPT
引言 如果你正在寻找一种可视化大规模数据集的方法,那么 Pyecharts 库可能是你的不二选择之一。Pyecharts 封装了常用的 Echarts 模板,并提供了一些简单易用的 API 来绘制各种类型的图表。
本文将介绍如何使用 Pyecharts 生成一个 GDP 动态柱状图。我…
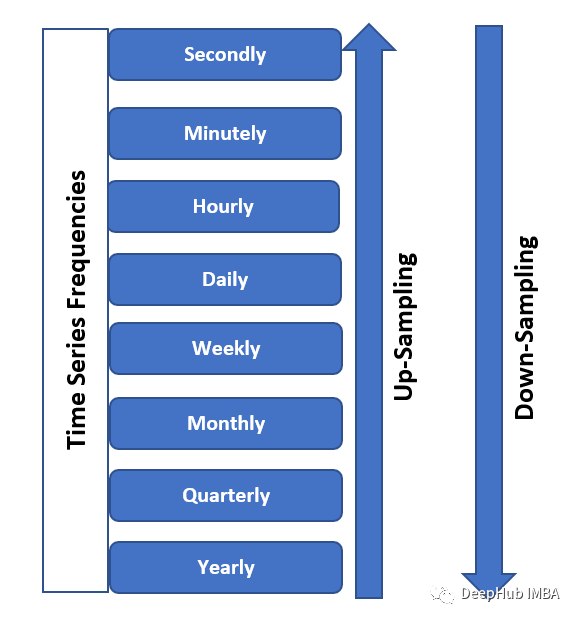
时间序列的重采样和pandas的resample方法介绍
重采样是时间序列分析中处理时序数据的一项基本技术。它是关于将时间序列数据从一个频率转换到另一个频率,它可以更改数据的时间间隔,通过上采样增加粒度,或通过下采样减少粒度。在本文中,我们将深入研究Pandas中重新采样的关键问…
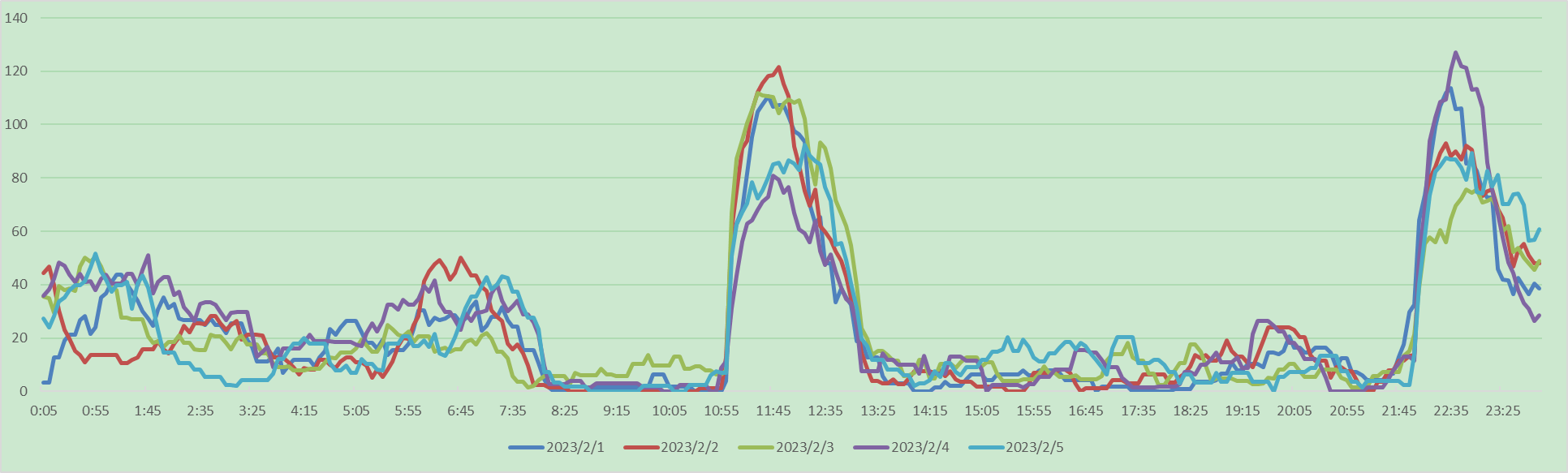
Python和Pandas对事件数据的处理:以电动汽车充电数据为例
1、数据
电动汽车的充电数据形式如下
订单号充电开始时间充电完成时间订单/时段总充电量(KWh)尖时电量峰时电量平时电量谷时电量2023020105000026122023-02-01 00:03:262023-02-01 00:40:5228.4410.0000.0000.00028.4412023020105000045702023-02-01 …
Pandas DataFrame: groupby agg的使用
创建于:2022.07.01 修改于:2022.07.01,2022.07.09 文章目录1、构建样例数据(无Null值和有Null值)2、agg常见聚合函数3、agg匿名聚合函数4、agg内的自定义方法5、transform应用6、apply应用7、参考链接1、构建样例数据&…
按照五个实验分数计算期末成绩分数
从五个实验分数出发,计算出最终的实验分数
目前设置:
有1,2个优秀的为优
有2,3个中的为中
其余为良0 45
1 14
2 13
4 5
3 3
5 1
优>=2的为优,且签到次数=2
----
0 60
2 7
5 6
1 4
4 2
3 2
Name: 中, dtype: int64
中>=2的为…
校园供水系统智能管理
import pandas as pd
data1pd.read_excel("C://Users//JJH//Desktop//E//附件_一季度.xlsx")
data2pd.read_excel("C://Users//JJH//Desktop//E//附件_二季度.xlsx")
data3pd.read_excel("C://Users//JJH//Desktop//E//附件_三季度.xlsx")
data4…
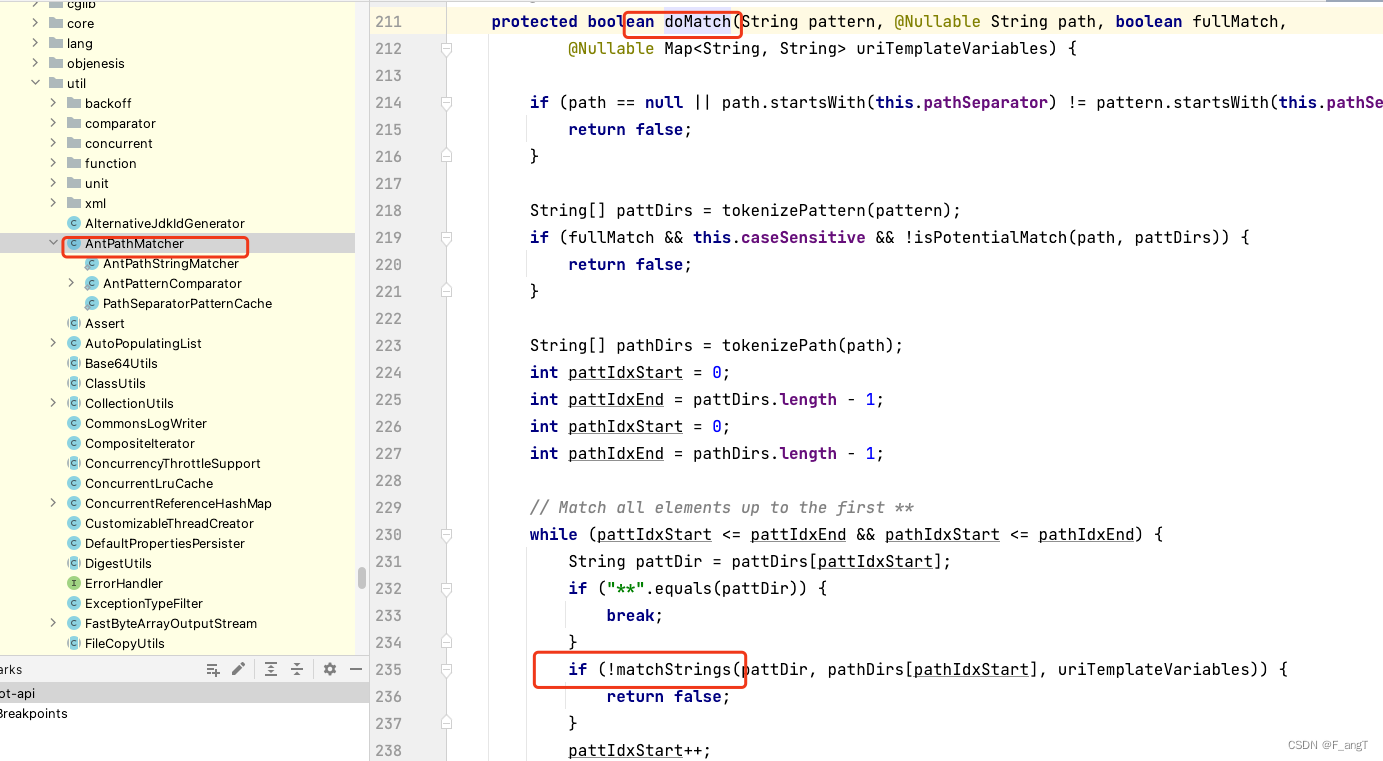
spring security权限路由匹配restful格式的详情id设计
解决方案:
先直接说下解决方案,权限点设计成如下:
/api/books/{id:\d*}问题描述:
获取书本详情的标准restful路由,一般是这样的/api/books/12, 12即该book的id,如果需要拥有访问该路由的权限…
pandas计算过去某个时间与今天的时间差
import datetime
start datetime.datetime(2015,1,1).date()
end datetime.date.today()
print(end-start)
pandas3 DataFrame数据的查询编辑
文章目录3.DataFrame数据的查询和编辑查询【一般都是通过索引来操作的】1.选取列2.选取行3.读取行和列4.布尔选择编辑【提取需要编辑的数据,重新赋值】1.增加数据2.删除数据3.修改数据3.DataFrame数据的查询和编辑
查询【一般都是通过索引来操作的】
1.选取列
通…

Python—Pandas学习之【DataFrame和Series之间的操作】
DataFrame和Series的维度不同,在线性代数中是无法进行乘积运算的,但在pandas中是可以进行运算的。,但需要注意的是,pandas中是将Series缺失的维度进行广播(将缺失的维度用原数据进行补齐,然后运算ÿ…

Python—Pandas学习之【DataFrame的apply函数、applymap函数】以及【Series的map函数】
直接运用函数,是对DataFrame整体进行操作如果使用apply()函数,则是对DataFrame进行逐列或者逐行操作。 其中,**默认是axis ’index‘,即固定其他轴,沿着0轴进行运算,得到的是每一列的计算结果 ** 如果想得…

Pandas DataFrame: 行列转换、一行生成多行,多行合并一行
创建于:2022.07.01 修改于:2022.07.01
1、构建一个样例数据
import pandas as pd
import numpy as np
df pd.DataFrame({姓名: [name_A, name_B, name_C],班级: [c1, c2, c2],语文: [90, 60, 70],数学: [80, 98, 80],英语: [85, 90, 75],物理: [92, 6…
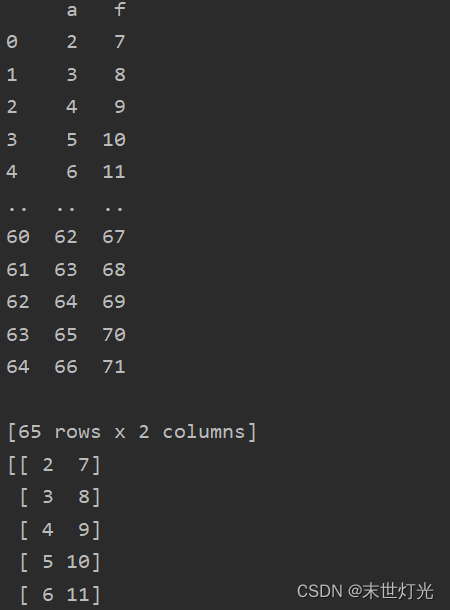
根据指定csv文件列名读取数据
准备csv文件: import pandas as pd
df pd.read_csv(data.csv)
print(df[[a,f]])
x df[[a,f]]
print(x.values)
结果展示:

pandas DataFra,学习笔记大全
读取数据
数据预处理
import pandas as pdheader [歌名,歌手,专辑,标签]
df pd.read_csv(name.csv,na_values无,index_col0,names header)
#读取时会把‘无’替换为nan,index_col0以文本索引为索引,names指定列名
#
#content [json.loads(line) for line in o…
Pandas模块之Series:01-基本创建
基本概念
Series 是带有标签的一维数组,可以保存任何数据类型(整数,字符串,浮点数,Python对象等),轴标签统称为索引。
import numpy as np
import pandas as pds pd.Series(np.random.randint(5,size 5…
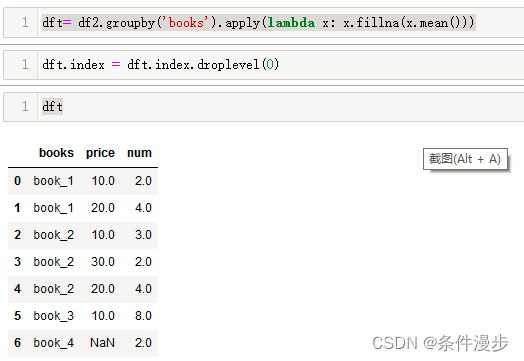
Pandas DataFrame: groupby filter/query的使用
创建于:2022.07.02 修改于:2022.07.02 文章目录1、构建样例数据2、filter,可以对分组进行操作3、query,不能对分组操作4、参考链接1、构建样例数据
import pandas as pd
import numpy as np
df pd.DataFrame({books:[book_1, bo…
Python数据分析技术入门
Python数据分析技术入门 数据分析入门指南一、前言二、Python基础知识1. Python环境配置2. Python基础语法3. Python常用库的导入和安装 三、数据处理基础1. 数据类型及数据结构2. 数据读取与写入3. 数据清洗4. 数据预处理 四、数据分析基础1. 统计分析基础2. 可视化基础3. 数据…
使用Pandas进行时间重采样,充分挖掘数据价值
大家好,时间序列数据蕴含着很大价值,通过重采样技术可以提升原始数据的表现形式。本文将介绍数据重采样方法和工具,提升数据可视化技巧。
在进行时间数据可视化时,数据重采样是至关重要且非常有用的,它支持控制数据的…
Pandas速查手册
原文:https://cloud.tencent.com/developer/article/1094110
对于数据科学家,无论是数据分析还是数据挖掘来说,Pandas是一个非常重要的Python包。它不仅提供了很多方法,使得数据处理非常简单,同时在数据处理速度上也做…
python学习——pandas统计分析基础
目录 pandas统计分析基础1. Series数据2.文件读取csv文件Excel文件 3.DataFrame连接数据库读取数据库存入数据库DataFrame的属性访问DataFrame中的数据【实例1】info详细信息和describe描述统计分析【实例2】 排序【实例3】 布尔索引,条件索引【案例】修改数据 3.描…
大数据(七):Pandas的基础应用详解(四)
专栏介绍
结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来!
全部文章请访问专栏:《Python全栈教程(0基础)》 再推荐一下最近热更的:《大厂测试高频面试题详解》 该专栏对…
pyhive的离线安装及使用示例
pyhive离线安装
pyhive下载离线安装包 下载方式一:直接把jieba包下载到/download/pip/目录下 pip download -d /download/pip/ pyhive[hive_pure_sasl]下载方式二:建一个requirement.txt文件里面一行一行写需要的包,/usr/local/download/pip/是下载目录 pip download -d /d…

pandas中时间序列的处理(获得时间特征:年月日周分秒等时间)
关于描述:在项目中遇到了特征的提取,因为数据的变化和时间有直接的关系,就考虑这个时间能提取出那些特征?
我的数据示例:200101010100。年月日时分秒的这个里面提取数据,我很明显可以看出来需要尝试提取&a…
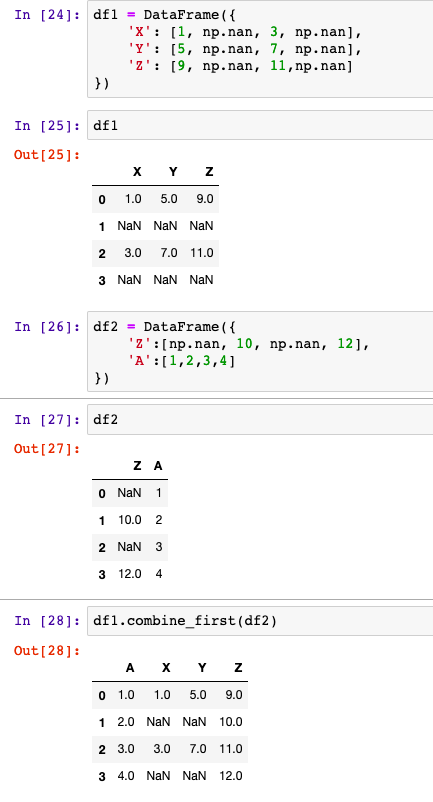
pandas9 合并数据
文章目录2.合并数据2.1 merge合并数据2.2concat数据连接2.3combine_first合并数据2.合并数据
2.1 merge合并数据
python中的merge函数是通过一个或多个键将两个DataFrame按行合并起来,与SQL中的join用法类似。
merge(left, right, howinner, onNone, left_onNone…
numpy和pandas简单快速入门
由于部分代码需要和数据文件配合,将项目和文件个人的GitHub——地址:https://github.com/1769172502/machine-learning 关于numpy参考菜鸟地址:http://www.runoob.com/numpy/numpy-tutorial.html
关于pandas参考地址:https://blo…
一行代码生成Tableau可视化图表
今天给大家介绍一个十分好用的Python模块,用来给数据集做一个初步的探索性数据分析(EDA),有着类似Tableau的可视化界面,我们通过对于字段的拖拽就可以实现想要的可视化图表,使用起来十分的简单且容易上手,学习成本低&a…
Pandas模块之DataFrame:03-基本操作
本文主要介绍DataFrame结构数据的基本操作,包括以下几个方面:
数据查看数据增删改数据对齐数据排序
数据查看
df pd.DataFrame(np.random.randint(100,size 16).reshape(8,2),columns [a,b])
print(df)
a b
0 89 41
1 36 8
2 15 41
3 16…
linux shell 和python3 pandas 对csv文件进行合并和关键字检索
1、csv的头格式一共有四项,clientip,clientlocation,serverip,serverlocation,分别表示客户端ip地址,客户端位置信息,服务端ip地址,服务端位置信息,第三方程序定期在指定目录下生成csv文件,需求是对该目录下…
pandas.factorize
官网地址https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.factorize.html
pandas.factorize
将Series中的相同的标称型映射为相同的index
pandas.factorize(values, sortFalse, na_sentinel- 1, size_hintNone, dropnaTrue)[source]
Encode the object…
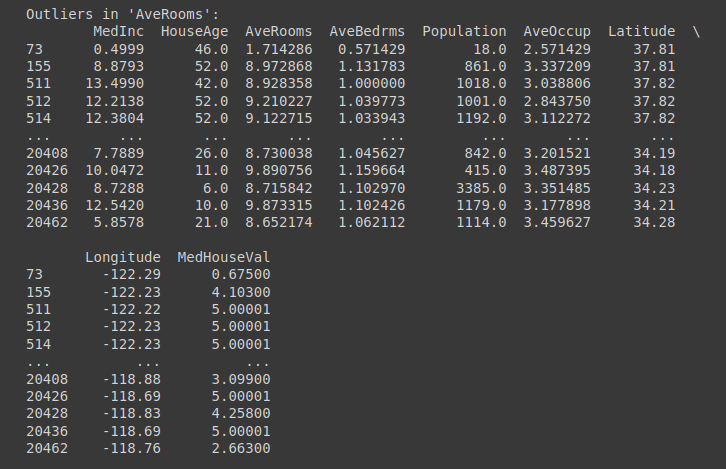
用Pandas轻松进行7项基本数据检查
大家好,作为一名数据工程师,面对糟糕的数据质量,可以使用Pandas执行快捷的数据质量检查。本文使用scikit-learn提供的California Housing数据集,进行基本数据检查。
一、California Housing数据集概述
【数据集】:
…
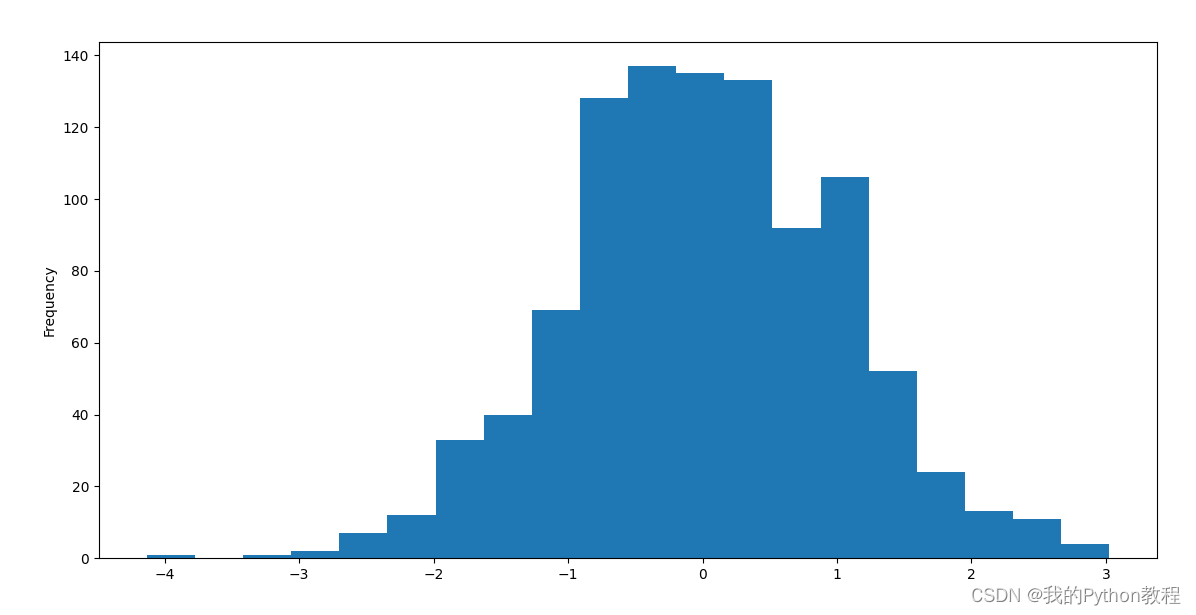
Pandas教程09:DataFrame数据可视化绘制折线图、柱状图、散点图、直方图等
pandas.plot() 是 pandas 库中的一个非常方便的函数,用于绘制各种图形,例如线图、柱状图、散点图等。以下是一些示例用法: 1.绘制一个简单的线图:
# Author : 小红牛
# 微信公众号:wdPython
import pandas as pd
impo…

python读写json文件方法详解
在我们日常使用 Python时,经常会使用到 json文件。那么在平时写一些小程序时,如何使用 json文件呢?今天我将介绍如何读取和写入 Json文件。 json是一种数据结构,它是将字符串转换成数据的一种技术。使用 json可以非常方便的将一组…
Pandas玩转数据
Pandas玩转数据
一、排序功能
0x1 Series的排序
s1 Series(np.random.randn(10))
s2 s1.sort_values(ascendingFalse) # 按照值降序排列
s2.sort_index() # 按照索引升序排列0x2 Dataframe的排序
df1 DataFrame(np.random.randn(40).reshape(8,5), columns[A,B,C,…

新书推荐之《Python数据分析实战》(手把手教你学Python系列视频配套教材)
书名:Python数据分析实战
ISBN:978-7-302-57235-0
作者:朱文强 钟元生 主编 高成珍 周璐喆 徐军 副主编
出版社:清华大学出版社
出版日期:2021年3月第1版
清华大学出版社官网链接
当当网、京东商城等均有售
本书…
数据分析系列 之pandas用例分析2
1 前言 本专题参考学习视频和网上其他大神的资料,推出pandas用例分析2,需要分析的主题是男女生电影评分差异分析。
2 原理 2.1 python pandas 中 loc & iloc 用法区别 loc:基于行标签和列标签(x_label、y_label)进…

力扣:184. 部门工资最高的员工(Python3)
题目: 表: Employee -----------------------
| 列名 | 类型 |
-----------------------
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
-----------------------
在 SQL …
Python数据分析script必备知识(二)
Python数据分析script必备知识(二)
1.二分钟快速给项目添加日志信息
"""
给项目添加日志信息
"""
# 导Python内置包
import logging
import time # 方便用日期命名日志# 创建一个日志器logger
logger = logging.getLogger(__name__)# 给日志…
pandas.read_csv报 ParserError: Error tokenizing data. C error: Expected 2 fields in line 134, saw 3
用pandas的read_csv读取 “\t” 分割的文件,报如下错误。 ParserError: Error tokenizing data. C error: Expected 2 fields in line 134, saw 3 网上有人提供的解决方案是:padans.csv_read函数加上一个参数delimiter,如下:
…

google play store的app数据分析
google play store app数据源 提取码: 38jk
google play store的app数据分析
1. 加载数据
加载数据分析使用的库加载数据前,先用文本编辑器简单浏览一下数据加载好数据之后,第一步先分别使用shape、head、count、describe和info方法看下数据
import …
Pandas模块之Series:03-操作技巧
本文主要介绍Series结构数据的基本操作,包括以下几个方面:
数据查看重新索引数据对齐数据增删改
数据查看
.head()方法和.tail()方法可以默认查看Series中的前、后5组数据,括号内也可以指定具体数据量。
s pd.Series(np.random.rand(50)…

四十岁入门 python pandas 处理 Excel 报表
都说 python 很强大,又容易学,有的省份已经将 python 纳入小学课程,于是我也想看看 python 有多容易学,断断续续看了差不多多半年的时间,有一种相见恨晚的感觉,为了不让更多的人错过这个强大又简单的编程工…

Linux常用的26条指令
文章目录 前言
1.ls指令
1.1功能
1.2常用选项 2.pwd指令
2.1功能
3.cd指令
3.1 功能
3.2常用选项
4.touch指令
4.1功能
4.2常用选项 5.mkdir指令
5.1mkdir功能
5.2mkdir常用选项
6.rmdir指令 和rm指令
6.1功能
6.2常用选项
7.man指令
7.1功能
7.2常用选项
7…
NLP-D57-nlp比赛D26刷题D13读论文找了一个多小时bug
——早上扫完三篇论文,下意识打开微信读书,又加了几本好书。现在总是觉得读书的时间是宝贵的、温暖的,希望能给自己的心灵留一块空地,也许是一片绿荫。现在开始刷题了!
2816双指针 803区间合并
n int(input())
a […
python+geopandas之分布和密度图
导入各种包,关键的是处理空间数据的相关包:
#-- coding : utf-8 --
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import geopandas
import os
from shapely.geometry import Point
import libpysal as ps
import mapcla…

Datawhale动手学数据分析打卡
1.1 第一章:数据载入及初步观察
1.1.1 任务一:导入numpy和pandas
import numpy as np
import pandas as pd1.1.2 任务二:载入数据
(1) 使用相对路径载入数据 (2) 使用绝对路径载入数据
import os
print(os.getcwd())
os.chdir(d:\\user\\…
用python画带有正负值的条形图
常见的条形图只能表现数据的大小,却不能表现值的正负关系。但是其实仅仅使用pandas和matplotlib两个包就可以实现y轴负轴的添加以及负值的显示,并且可以为正负值分别设置不同的颜色,让条形图看上去更加清晰,易于我们分析。
import pandas as pd
import matplotlib.pyplot …
pandas常用数据处理函数整理
pandas数据处理常用函数整理
参考:《joyfulpandas》
数据下载:https://www.heywhale.com/mw/dataset/625d2653e22b670017093353/file
分组
# 分组
# 1.分组模式及其对象
# 1.1分组的一般模式
# 想要实现分组操作,必须明确三个要素&#x…
Python:读写 excel
欢迎访问我的博客首页。 读写 excel1. xlrd 和 xlwt1.1 xlrd 读1.2 xlwt 写2. openpyxl2.1 openpyxl 读2.2 openpyxl 写3. pandas3.1 pandas 读3.2 pandas 写4. 参考Python 有三种常用的 excel 处理库 xlrd/xlwt、openpyxl、pandas。xlrd/xlwt 只能处理 xls,下标从 …
Python Pandas 筛选包含某字符串的行数据 过滤含某字符串的数据
筛选包含某字符串的数据
import pandas as pd
data pd.read_csv(path)
datats_code symbol name area industry list_date
0 000001.SZ 1 平安银行 深圳 银行 19910403
1 000002.SZ 2 万科A 深圳 全国地产 19910129
2 000004.SZ …
Pandas模块之DataFrame:02-索引与切片
Dataframe既有行索引也有列索引,可以被看做由Series组成的字典。
df pd.DataFrame(np.random.randint(100,size 12).reshape(3,4),index [one,two,three],columns [a,b,c,d])
print(df)
a b c d
one 35 35 17 50
two 53 4 51 23
three 82 …
Python pandas 空值缺失值(NaN)处理填充替换判断删除含缺失空值数据行
缺失值处理 判断
datats_code symbol name area industry list_date
0 000001.SZ 1.0 平安银行 深圳 银行 19910403
1 000002.SZ NaN 万科A 深圳 全国地产 19910129
2 000004.SZ 4.0 ST国华 NaN 软件服务 19910114
3 000005.…
【学习笔记】Pandas数据分析库基础学习
Series,DataFrame
Series可以看成一个定长的有序字典
一下默认import pandas as pd pd.Series([x,x,x,x])# 创建Series,索引未指定的话,为默认值 pd.Series([x,x,x,x],index[a,b,c,d])创建Series,指定索引值 Series.values查看…

5行Python代码采集3000+上市公司信息,很爽
嗨害大家好鸭!我是爱摸鱼的芝士❤
毕业季也到了找工作的季节了, 很多小伙伴都会一家一家的公司去看, 这得多浪费时间啊。
今天用Python教大家怎么采集公司的信息, 相信大家会很喜欢这个教程的,nice! pyth…
Pandas数据操作_Python数据分析与可视化
Pandas数据操作 排序操作对索引进行排序按行排序按值排序 删除操作算数运算去重duplicated()drop_duplicates() 数据重塑层次化索引索引方式内层选取数据重塑 排序操作
对索引进行排序
Series 用 sort_index() 按索引排序,sort_values() 按值排序; Dat…

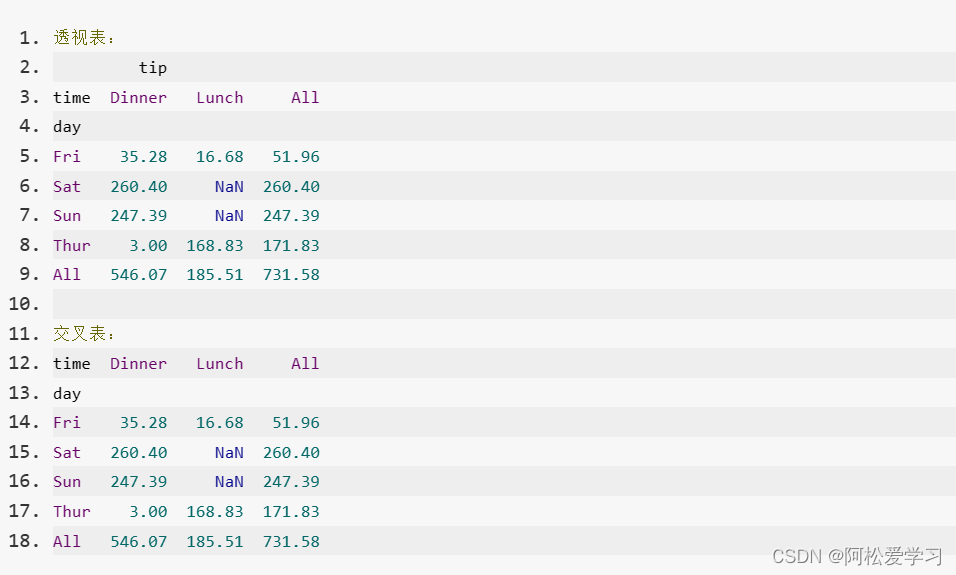
pandas6 数据透视表
文章目录6.数据透视表透视表交叉表:是一种特殊的透视表,主要用于计算分组频率。使用Pandas提供的crosstab函数可以制作。6.数据透视表
数据透视表(Pivot Table)是数据分析中常见的工具之一,根据一个或多个键值对对数据进行聚合&a…

pandas7 Pandas可视化
文章目录7.Pandas可视化线形图柱状图直方图和密度图散点图7.Pandas可视化
Pandas中集成了Matplotlib中的基础组件,绘图便捷。
线形图
线形图一般用于描述两组数据之间的趋势。Pandas库中的Series和DataFrame中都有绘制各类图表的plot方法,默认绘制线形…

python中的NumPy和Pandas往往都是同时使用,NumPy和Pandas的在数据分析中的联合使用
文章目录 前言一、numpy的介绍与用法二、pandas的介绍与用法三、numpy与pandas的联合使用说明四、numpy与pandas的联合使用程序代码4.1 读取CSV文件并进行数据清洗,如去除NaN值4.2 矩阵操作和特征工程,如标准化处理4.3 使用Pandas进行数据筛选和分组聚合…
pandas 统计函数
01 nunique number of unique,用于统计各列数据的唯一值个数,相当于SQL语句中的count(distinct **)用法。nunique()既适用于一维的Series也适用于二维的DataFrame,但一般用于Series较多,此时返回一个标量数值,表示该se…
学习Python的NumPy、pandas、matplotlib笔记
关于Numpy、Pandas、matplotlib笔记 关于Numpy的学习Numpy的代码练习 关于Pandas的学习Pandas代码的练习 关于Matplotlib的学习Matplotlib代码练习 关于Numpy的学习
Numpy的代码练习 import numpy as np
anp.array([[1,2],[3,4]])
print(a)
print(a.dtype)
a.astype(np.float1…
python画立方体(魔方)
目录 立方体每列颜色不同立方体各面颜色不同彩色透视立方体立方体每列颜色不同
# Import libraries
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np# Create axis
axes = [5,5,
PyPackage01---Pandas16_apply返回多个值时的索引问题
Intro pandas使用apply函数或者groupby函数返回多个值时,会出现返回多个索引的问题,介绍下解决方法
复现
import pandas as pd
import numpy as npdf pd.DataFrame({"name": [a, b, c],"sex": [男, 女, 男],"age": [10…
pandas沿着列方向进行统计计算
也就是对每一行求值 假设存在数据集data: RPT VAL ROS KIL SHA BIR DUB CLA MUL
Yr_Mo_Dy
1961-01-01 15.04 14.96 13.17 9.29 NaN 9.87 13.67 10.25 10.83
1961-01-02 14.71 NaN 10.83 6.50 12.62 7.67 11.50 10.04 9.79
1961-01-…

python数据处理----Pandas入门
Pandas的两种数据结构以及创建方式
DataFrame和Series是Pandas最基本的两种数据结构DataFrame用来处理结构化数据(SQL数据表,CSV文件)Series用来处理单列数据,也可以把DataFrame当作Series对象组成的字典
1. 创建Series对象
Pa…

利用Python将一个Excel拆分为多个Excel
原始文档如下图所示 将销售部门一、二、三科分别存为三个Excel
代码如下
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 9 20:25:31 2018author: Lenovo
"""import pandas as pddata pd.read_excel("E:\data1.xls")
rows data…

用python处理时间序列数据,检验平稳性跟纯随机性
用python处理时间序列数据,检验平稳性跟纯随机性
from statsmodels.tsa.stattools import adfuller as adf
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import pandas as pd
import numpy as np!pip install statsmodelsRequirement already …
python读parquet文件 pandas读parquet文件
如何使用gzip压缩后的parquet文件
今天我们来学习使用python读取parquet文件
背景
有一个parquet文件,而且还用gzip压缩了。
那该如何读取呢?
准备工作
安装
pandas和pyarrow
# 安装 pandas and pyarrow:
pip3 install pandas pyarrow
读取
# …
Series计算和DataFrame常用属性方法
Series的布尔索引
从Series中获取满足某些条件的数据,可以使用布尔索引 然后可以手动创建布尔值列表
bool_index [True,False,False,False,True]
scientists[bool_index] # 查询行索引,列索引是用列名 筛选年龄大于平均年龄的科学家
age_mean sci[Age].mean()…

python数据分析三大神器基本操作1
python数据分析三大神器基本操作1
今天我带大家感受一下数据分析三大神器到底强大再哪里,这里我将用原生python代码和三大神器(numpy,pandas,matplotlib)来实现相同的功能做出比较,看看它到底独特在哪里。…
python数据清洗1
数据获取——》数据清洗——》数据转换——》数据分析
通过设置步长,有间隔的取元素通过设置步长为-1,将元素颠倒 数据清洗工具
目前在Python中, numpy和pandas是最主流的工具。
Numpy中的向量化运算使得数据处理变得高效;Pandas提供了大量…

DataFrame.query()--Pandas
1. 函数功能
Pandas 中的一个函数,用于在 DataFrame 中执行查询操作。这个方法会返回一个新的 DataFrame,其中包含符合查询条件的数据行。请注意,query 方法只能用于筛选行,而不能用于筛选列。
2. 函数语法
DataFrame.query(ex…
Python数据攻略-Pandas常用数据操作与数据清洗
在数据分析的旅程中,数据操作和数据清洗通常是最费时间和精力的步骤,但也是最重要的。无论在分析三国志游戏的玩家行为,还是在研究历史战役,数据质量都是关键。
本文使用Pandas库进行数据操作和清洗,确保数据准确、完整和易于分析。 文章目录 数据选择与筛选使用条件语句…
pandas数据结构(python数据分析活用pandas库)
目录 1创建数据 1.1创建series
1.2创建dataframe 2.Series 2.1 类似于ndarray的Series
2.2布尔子集:series 2.3 操作自动对齐和向量化 2.3.1同长度向量 2.3.2向量和整数运算
2.3.3不同长度向量间的运算
2.3.4带有常见索引标签的向量 3.dataframe
3.1布尔子集 …

Python:Pandas学习笔记(一)Series和DataFrame、相关性及NaN处理
目录
pandas核心数据结构
Series
DataFrame
Index对象
算数和数据对齐
numpy函数应用与自定义函数
Series和DataFrame的排序和排位
相关性和协方差
NaN的数据处理 pandas核心数据结构
pandas是以numpy为基础的,还提供了一些额外的方法
Series
series用来…
Seaborn.load_dataset()加载数据集失败最佳解决方法
load_dataset() 是 Seaborn 库中提供的一个函数,用于加载一些原始数据集。这些数据集包含了许多经典的数据集,比如鸢尾花数据集、小费数据集等,这些数据集在数据可视化和机器学习中非常常见。
使用 load_dataset() 函数可以方便地获取这些数…
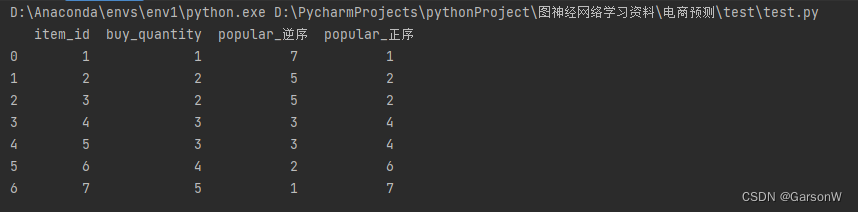
pandas根据列正逆序排序
题目:根据 buy_quantity 列进行排名,相同值分配相同的最低排名。
import pandas as pd# 创建一个示例 DataFrame
data {item_id: [1, 2, 3, 4, 5, 6, 7], buy_quantity: [1, 2, 2, 3, 3, 4, 5]}
df pd.DataFrame(data)# 使用 rank() 函数为 buy_quant…
护士排班问题:Nurse Rostering Problem(NRP)实战并可视化页面
文章目录 护士排班NRP问题问题示例模型求解排班表可视化护士排班NRP问题
基于计算机的自动化排班有助于提高排班的效率和质量,从而使得人力资源得到有效的利用。护士排班问题并不专指对于医院护士的排班,实际上泛指这种限制条件较多的排班问题。护士排班NRP问题是一个典型的…
pandas groupy和agg一起使用,as_index = False不生效?
确实不生效
尤其是agg里有一组聚合函数时,设置as_index False可能还出错
那该怎么办
不再设置as_index False
而是对结果进行reset_index()
# 这样符合预期:end_result test_df.groupby(shouldnt be index,as_indexFalse).agg(min) # 但这样,会得…
阿里巴巴股票行情分析
友情提示:投资有风险,入股需谨慎
阿里巴巴股票数据集 提取码: spyv
简单分析
上代码
import numpy as np
from dateutil.parser import parse
# 指定打开的文件名
# 不需要的行需要skip掉
# 默认没有分隔符,所以需要指定delimiter
# 不加…
Apache POI表格无法使用pandas打开Excel报错Workbook contains no default style, apply openpyxl‘s default
打不开产生原因
是因为xlsx文件是由Apache POI创建,并不是Microsoft Excel创建,从文件属性里面程序名称是Apache POI可以看到。 解决办法一 手动打开excel,并重新保存或者另存为即可,然后就可以使用pandas打开了。 解决办法二 使…
pandas的get_dummies进行one-hot编码
pandas.get_dummies(data, prefixNone, prefix_sep’_’, dummy_naFalse, columnsNone, sparseFalse, drop_firstFalse, dtypeNone) 说下常用参数 data:的话就是我们要处理的数据 prefix:就是我们制定的前缀, columns:这是我们直接在原数据集上使用
eg:
datapd.Da…
根据excel的列下每个名称出现了几次,计算对应数量
import pandas as pd# 读取 Excel 文件
df pd.read_excel(your_excel_file.xlsx)# 计算每个智库名称出现的次数,并形成对应名称的报告数量
result df[think_tank_name].value_counts()# 创建新的数据框
new_df pd.DataFrame({智库名称: result.index.tolist(),报…
Python pandas 读取csv/txt数据文件 python读取csv/txt文件
导读 主要利用pandas.read_csv接口对csv格式文件或txt文件进行读取,由于CSV格式文件使用非常频繁,功能强大,参数众多,因此在这里专门做详细介绍 使用示例 # 基础用法
import pandas as pd
pd.read_csv(path)ts_code symbol name…
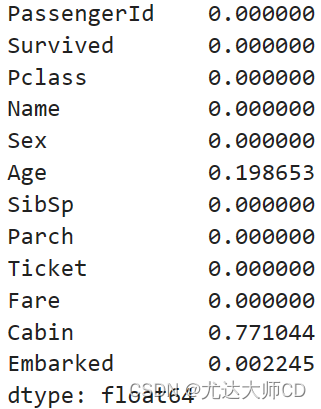
2.Pandas数据预处理
2.1 数据清洗
以titanic数据为例。
df pd.read_csv(titanic.csv)
2.1.1 缺失值
(1)缺失判断
df.isnull() (2)缺失统计
# 列缺失统计
df.isnull().sum(axis0) # 行缺失统计
df.isnull().sum(axis1) # 统计缺失率
df.isnu…
pandas教程:Resampling and Frequency Conversion 重采样和频度转换
文章目录 11.6 Resampling and Frequency Conversion(重采样和频度转换)1 Downsampling(降采样)Open-High-Low-Close (OHLC) resampling(股价图重取样) 2 Upsampling and Interpolation(增采样和…
Microsoft Power Automate部署方案
目录
前言
一、Microsoft Power Automate是什么?
二、Microsoft Power Automate的介绍
2.1 Microsoft Power Automate的概述
【错误笔记】Pandas:DataFram.append 没有添加新数据行
在 pandas 中,可以采用 dataframe.append() 函数来向数据帧中添加新的数据行,直接使用 dataframe.append(data)是错误的,再查看dataframe,还是不会显示新增加的内容……
正确的使用方式是赋值操作:
dataframe dataf…
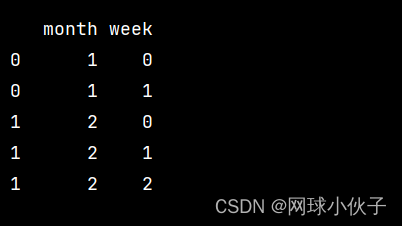
Pandas 将DataFrame中单元格内的列表拆分成单独的行
使用 explode 函数
import pandas as pddata {month: [1, 2],week: [[i for i in range(2)], [i for i in range(3)]]}
df pd.DataFrame(data)
print(df)df df.explode(week)
print(df)
pandas dataframe 基础知识(python数据分析活用pandas库)
目录 1.加载数据集
2.查看列,行和单元格 2.1获取列子集
2.2获取行子集
2.2.1通过索引标签获取行子集:loc
2.2.2 通过行号获取行:iloc
2.3 混合
2.3.1获取列子集
2.3.2通过范围选择列子集
2.3.3使用切片语法获取列子集
2.3.4获取行和列的子集
2.3.5获取多…
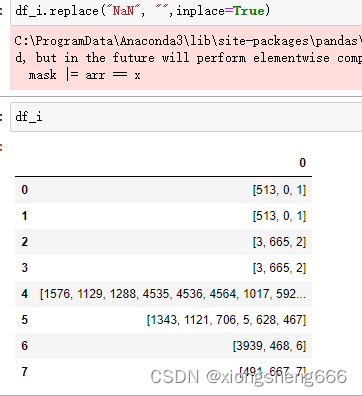
pandas 将单元格是列表的DataFrame拆成多列
方法:
pd.DataFrame(df[col].values.tolist()) 将单元格元素是列表的列拆成多列
如果要与原来的其他列合并
pd.concat([pd.DataFrame(df[col].values.tolist()), df[其他列]], axis1)
示例: points数组如下: 生成DataFrame如下 处理结…
报错File pandas/_libs/hashtable_class_helper.pxi, line 1218, in pandas._libs.hashtable.PyObjectHashT
问题:
今天用pandas按列索引名称取某一列的值的时候,报错如下: File “pandas/_libs/hashtable_class_helper.pxi”, line 1218, in pandas._libs.hashtable.PyObjectHashTable.get_item (pandas/_libs/hashtable.c:20477) 原因:…
pandas dataframe 删除列中 有空值的行
目标df
df pd.DataFrame({“name”: [‘A’,‘B’,‘C’,np.nan], “age”: [np.nan,22,25,np.nan], “gender”: [‘male’,‘female’,‘male’,‘female’], })
删除name、age列中,【任意一列】的值为空的行;
df.dropna(subset[‘name’, ‘age’], axis0, #…
【error 踩坑】AttributeError: ‘DataFrame‘ object has no attribute ‘iteritems‘
新建了虚拟环境py38,安装pandas
pip install pandas接着使用spark向hive表中写数据 发现出现了error:
AttributeError: DataFrame object has no attribute iteritemsgoogle后找到答案: Looks like iteritems was removed in pandas 2.0 - try using pandas versi…
力扣:197. 上升的温度(Python3)
题目: 表: Weather ------------------------
| Column Name | Type |
------------------------
| id | int |
| recordDate | date |
| temperature | int |
------------------------
id 是该表具有唯一值的列。
该表…

4. Pandas行列操作
4.1 新增列
4.1.1 assign
Pandas中的assign()函数不仅可以实现不改变原数据情况下新增列,而且可以同时新增多列,还可以配合链式操作使用一行代码完成多个新增列创建,使得代码非常整洁。
(1)函…
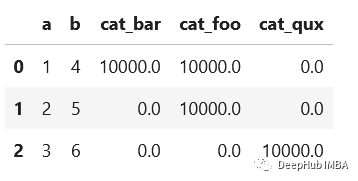
![[数据挖掘02] pandas的分配和聚合函数(1)](https://img-blog.csdnimg.cn/86d3e0a69b9a45018f7d0f34d72d0fe9.png)
[数据挖掘02] pandas的分配和聚合函数(1)
一 说明 窗口函数是什么?窗口函数是时间序列的局部属性处理函数,比如,一维卷积滤波、移动平均、指数平均本篇我们将针对pandas对象的窗口函数展开讨论,并以示例展示他们的概念实质。 二 窗口函数、分组函数( GroupBy …
pandas notes 30
1. What is pandas?
pandas main page
pandas installation instructions
Anaconda distribution of Python (includes pandas)
How to use the IPython/Jupyter notebook 2. How do I read a tabular data file into pandas?
user_cols [user_id, age, gender, occupa…
30 天 Pandas 挑战 Day16:reset_index()将结果从 Series转为DataFrame
题目:1741. 查找每个员工花费的总时间
输入
Employees table:
---------------------------------------
| emp_id | event_day | in_time | out_time |
---------------------------------------
| 1 | 2020-11-28 | 4 | 32 |
| 1 | 2020…

【Python数据处理】-Pandas笔记
Python数据处理-Pandas笔记
📝 基本概念
Pandas是一个强大的Python数据处理库,它提供了高效的数据结构和数据分析工具,使数据处理变得简单而快速。本篇笔记将介绍Pandas中最常用的数据结构——Series和DataFrame,以及数据处理的…
Python+Pandas数据清洗的步骤
一、导语二、常见步骤1. 导入 Pandas:2. 加载数据:3. 观察数据:4. 处理缺失值:5. 处理重复值:6. 数据类型转换:7. 处理异常值:8. 数据重塑:9. 数据归一化/标准化:10. 保存…

机器学习基本模型与算法在线实验闯关
机器学习基本模型与算法在线实验闯关 文章目录 机器学习基本模型与算法在线实验闯关一、缺失值填充二、数据标准化三、支持向量机分类模型及其应用四、逻辑回归模型及其应用五、神经网络分类模型及其应用六、线性回归模型及其应用七、神经网络回归模型及其应用八、支持向量机回…
如何使用 Python 脚本提高数据录入员效率
部分数据来源:ChatGPT
引言 作为数据录入员,每天都需要处理大量的数据。随着日子的推移,数据量会不断增加,使得记录和处理更加麻烦。为了提高工作效率和减轻工作负担,你可以使用 Python 编写一些实用的脚本,以帮助处理数据并快速完成任务。
本文将向您展示如何使用 Py…
Pandas基础内容
Pandas基础内容
Pandas是Python第三方库,提供高性能易用数据类型和分析工具,Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用。
Pandas的理解
NumPyPandas基础数据类型扩展数据类型关注数据的结构表达关注数据的应用表达维度ÿ…

GeoDataFrame 应用:公园分布映射至subzone
0 问题描述
我们知道新加坡的monument分布:Monuments-Data.gov.sg 我们又知道新加坡的subzone信息: Master Plan 2019 Subzone Boundary (No Sea) - Datasets - Dataportal.asia 我们希望生成一个 dataframe,表示每一个subzone有几个monumen…
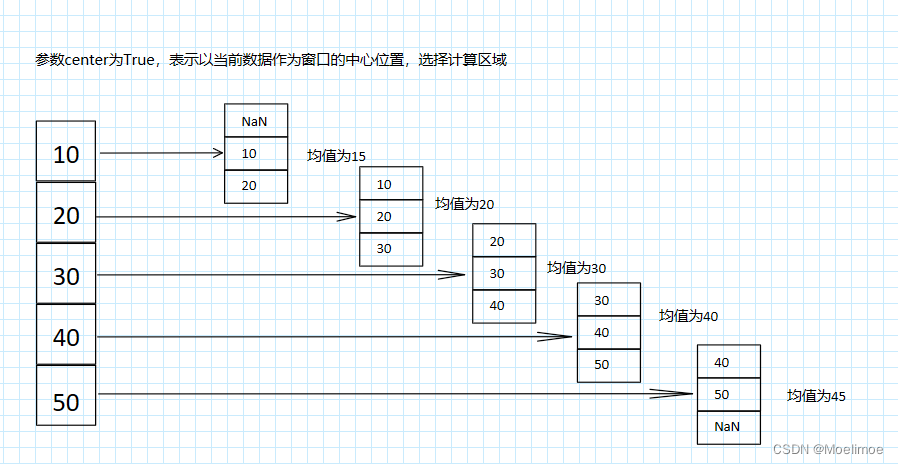
使用pands.rolling方法实现移动窗口的聚合计算
一个问题举例
假设有一个5天的收益数据,需要每3天求出一次平均值来达成某个需求:
daterevenue2023-05-01102023-05-02202023-05-03302023-05-04402023-05-0550
1号、2号和3号的数据求一次平均值,2号、3号和4号的数据求一次平均值ÿ…
pandas pct_change 计算间隔行的变化
在pandas中,可以使用.pct_change()方法计算DataFrame或Series中相邻两行的百分比变化。
.pct_change()方法的基本语法是:
df.pct_change(periods1) 1 periods:计算相邻几行的变化,默认为1,表示相邻两行
数据量大,分析困难?试试pandas随机抽样
前言
在数据分析和机器学习领域,随机抽样是一个非常重要的技术。它可以帮助我们从大量的数据中获取一部分样本,以进行统计分析、建模和预测。而在Python中,pandas是一个非常强大的数据分析库,它提供了许多方便的函数和方法来处理…
pandas使用[]单中括号和[[]]双中括号的区别
close_px pd.read_csv(uhttps://gitee.com/pan19/data-source/raw/master/stock_px_2.csv, parse_datesTrue,index_col0)
close_px.info()
close_px.head(10)type(close_px[‘SPX’]) 返回 pandas.core.series.Series
type(close_px[[‘SPX’]]) 返回 pandas.core.frame.Data…
Pandas之Series(一)
Hi😊😊~大家好呀~最近两天釉色酱在学习python中的数据分析的一个基本库——pandas。今天就先学习pandas中最基本的数据结构Series。下面我们一起进入Series的世界吧!😝 Pandas简介:
Pandas是一种基于Python语言的快速…
pandas.loc详解?
loc是Pandas中用于标签基于定位的索引方法,主要用于选择DataFrame或Series中的行和列。 loc除了逐行指定元素的位置外,还能一次选择多行(列),同时指定多种条件。 具体用法如下: 1. 选择列:df.lo…
Pandas2.0它来了,这些新功能你知道多少?
前言 本文是该专栏的第29篇,后面会持续分享python的数据分析知识,记得关注。
做过数据分析的同学,都知道pandas是开源数据分析工具,广泛用于数据清洗,数据处理,数据分析等相关领域。而随着现在行业的数据量越来越多,pandas的部分局限性也开始凸显,特别是在处理大数据业…
空值让数据分析头疼?Pandas空值处理全攻略来了!
在进行数据分析和建模时,空值的存在会给结果带来很大影响,甚至导致错误。所以在预处理数据时,我们必须对空值进行妥善处理。
在Pandas中,常见的空值表示有:
NaN:表示数值型的空值None:表示对象…
Pandas学习笔记 Series DataFrame
Series
import numpy as np
import pandas as pd
import sys
from pandas import Series,DataFrameobjSeries([4,7,-5,3],index[d,b,a,c])
objobj[[d,c]]obj[b]6
obj
obj*2obj[obj>2]np.exp(obj)sdata{hi:35,mi:49,ji:59,ki:89} #由字典创建序列
obj1Series(sdata)
obj1sta…
Pandas数据统计的基本使用
1. 安装pandas
pip install pandas2. 使用pandas (这里我们jupyter lab 交互笔记)
黑窗口下 启动: jupyter lab3.导入 pandas 包
import pandas as pddata pd.read_csv(文件路径,编码)查看数据类型
print(type(data))
#pandas有两种类型: DataFrame类型(处理二维,常用)…
pandas read_sql 读取数据库
1. 连接sqlalchemy
pandas.read_sql 可以在数据库中执行指定的SQL语句查询,以DataFrame 的类型返回查询结果。
import sqlalchemy
import pandas as pd# 创建数据库连接,这里使用的是pymysql
engine sqlalchemy.create_engine("mysqlpymysql://u…
pandas的索引问题(iloc和loc)
关于loc和iloc
loc指的是定位索引,英文意思是loction iloc指的是数字定位索引,int location表示这个只能通过整数索引来取出元素
先定义数据 iloc索引用法
取出指定的某几行,或某几列
这个方法是在需要取出特定的行或者列的时候用&#x…

Pandas 常用操作整理(持续更新)
Pandas 常用操作整理
1、数据定义
import pandas as pd
import numpy as np#定义dataframe
# 数据是元组,索引是list
df pd.DataFrame({no:[1,2,3,4,5],score:[66,85,88,95,75]},index[a,b,c,d,e])df.index.nameindex
print(df)#通过元组定义dataframe
dic {ke…

Pandas中的Series(第1讲)
Pandas中的Series(第1讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔…
pandas写入MySQL
安装好pandas、mysql
pip install pandas
pip install pymysql
导入pandas、mysql
import pymysql as mysql
import pandas as pd
建立连接
conmysql.connect(host10.10.0.221,userroot,passwordroot,databasepandas,port3306,charsetutf8)
创建游标
curcon.cursor()
读…
Pandas数据的排序与统计
Pandas数据的排序与统计
索引排序
.sort_index()方法在指定轴上根据索引进行排序,默认升序
格式:.sort_index(axis0, ascendingTrue)其中ascending为递增排序
import pandas as pd
import numpy as np
b pd.DataFrame(np.arange(20).reshape(4,5), …
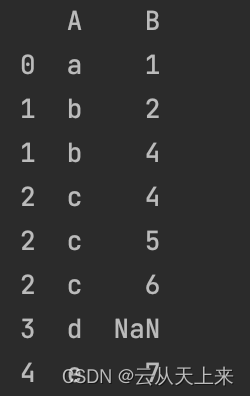
pandas dataframe 中 explode()函数用法及效果
最近在使用pyspark处理数据,需要连接各种各样的表和字段,因此记录相关函数的使用情况。今天介绍explode().
1. explode()函数简介 explode 函数是 pandas.DataFrame 类的一个方法,能够通过pyspark间接调用。 它可以将一个包含list或者其它可…
pandas读取excel文件,如果excel文件太大内存存不下怎么办?
在数据分析任务中,我们常常需要读取Excel文件中的数据。但是,如果Excel文件特别大,内存无法加载整个文件,这时候pandas读取Excel文件会出现内存溢出的错误。本文介绍几种优化方法,可以有效解决这个问题。
1. 分块读取…

python之Pandas
1.Pandas简介
Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集…
pandas.DataFrame.sample
pandas.DataFrame.sample
1、api DataFrame.sample(self, nNone, fracNone, replaceFalse, weightsNone, random_stateNone, axisNone) 2、参数和返回值
参数:
n从数据中抽n个样本,不能和frac同时使用frac从数据中抽取的比例(例如frac0.5&…
如何用 pandas 对数据进行预处理?
在数据分析和机器学习的过程中,将数据进行预处理是一个非常重要的步骤。Pandas 是一个流行的 Python 数据分析库,它提供了许多功能来帮助数据预处理。下面是一些常见的数据预处理技巧,可以用 Pandas 实现: 1. 导入数据
使用 Pand…
Pandas-用一个dataframe去更新另一个dateframe
两个dataframe更新,可以用update来进行,update是使用index来匹配的。
>>> dfa pd.DataFrame([(chr(65x),x) for x in range(5)],columns[LETTER,NUMBER]) >>> dfa LETTER NUMBER 0 A 0 1 B 1 2 C …
pandas读取Excel文档数据
演示视频
python读取Excel表格数据pandas读取表格read_excel函数使用_哔哩哔哩_bilibili
read_excel函数 实现功能
调用python多个Excel表格数据处理引擎,读入后返回pandas.Dataframe对象,是目前数据处理中比较主流的一种方式,需要先安装p…

pandas按某列降序
升序
import pandas as pd
import numpy as npdata np.random.randint(low2,high10,size(5,3))
data2 np.random.randint(low2,high10,size(5,3))df1 pd.DataFrame(data,columns["a","b","c"],indexrange(5))
df2 pd.DataFrame(data2,col…
Python pandas 读取字符串数据StringIO字符串流数据read_csv读字符流
导读
pandas.read_csv接口不仅可以读取如x.csv和x.txt格式的文件,也可对字符串数据进行读入 实现
利用StringIO将字符串转IO流,昨晚read_csv参数读取
import pandas as pd
from io import StringIO
import requestsurl http://quotes.money.163.com/…

Pandas-DataFrame构造
一. DataFrame的构造方式
1. 通过list或numpy数组构造DF # -*- coding:utf-8 -*-
import pandas as pddf pd.DataFrame([data [a, b, c], [d, e, f],[g, h, i]],columns [field1, field2, field3]) 这是最简单的创建形式,传入的list一般是多维度的,且…
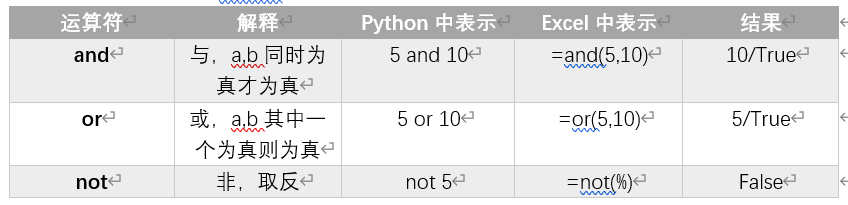
从Excel的数据类型说Python
写在前面
这节内容是python基础知识中的数据类型和运算符,可以回顾一下前两篇文章来复习一下: 利用Excel学习Python:变量 利用Excel学习Python:准备篇
本来想分开写的,但发现好像分不开,所幸内容也不多,废…
Pandas学习笔记(DataFrame基本操作)
对于生成的dDataFrame,下一步进行的是对他的基本操作,增、减、改、查。
一. 数据选取 从已有的DataFrame中取出其中一列或几列,并对其进行操作。 Pandas取出DataFrame的列有两种方式,两个方式没有好与坏之分,还是看个…
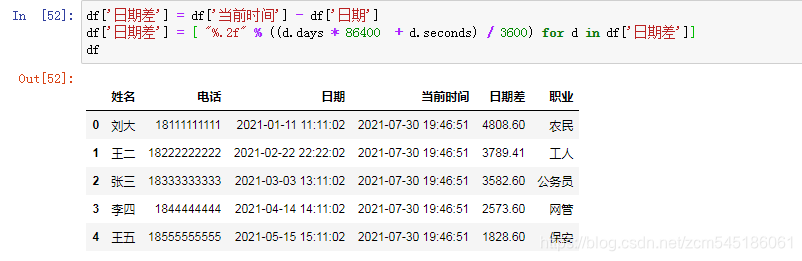
pandas计算excel两列的日期差
原始Excel数据 诉求:往Excel中追加两列"当前时间"、“时间差”,计算日期和当前时间相差的天数、小时、秒, 注:一天等于86400秒
插入两列数据到表格
# codingutf-8
import pandas as pd
import datetimedf pd.read_ex…
python学习笔记(2):变量
变量,从名称就可以理解,变化的量,与之相对的是常量,就是不会改变的量。 1.变量
变量有两个要素,变量名和值,变量一般这样表示:变量名 值,我们把变量名叫做标识符,变量名…
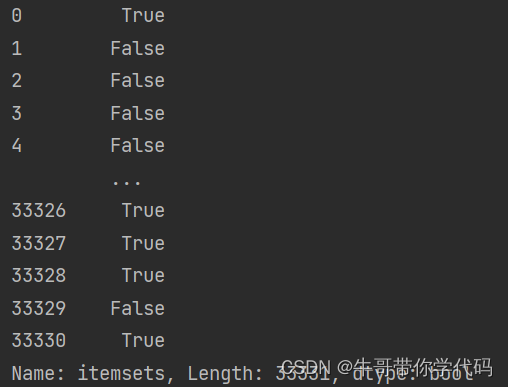
数据挖掘复盘——apriori
read_csv函数返回的数据类型是Dataframe类型
对于Dataframe类型使用条件表达式
dfdf.loc[df.loc[:,0]2]df: 这是一个DataFrame对象的变量名,表示一个二维的表格型数据结构,类似于电子表格或SQL表。 df.loc[:, 0]: 这是使用DataFrame的.loc属性来进行…
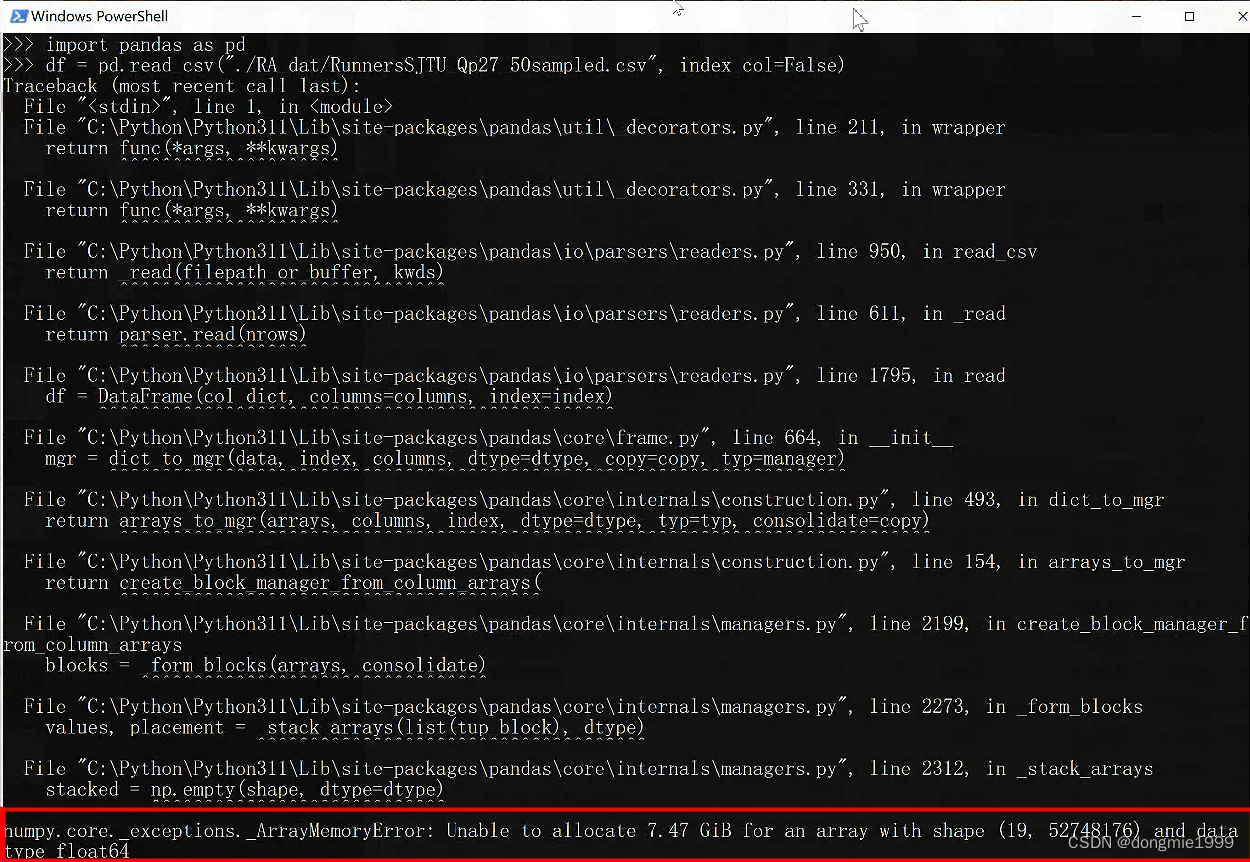
pandas 处大 csv 文件:chunk
用 pandas 读取 csv 的常见方法:
import pandas as pddf pd.read_csv("your_csv_file.csv")
但对于大型的 csv 文件,直接读取可能会报错 numpy.core._exceptions._ArrayMemoryError 我的机器是 24G 内存,直接读大概只允许单个最…

numpy_两数组拼接与数学函数
知识点: 1. 拼接的两个数组的形状必须一致,否则报错 2. np.round(a,decimals)四舍五入 import numpy as np
arr1 np.random.randint(0,100,size(2,4))
arr1 arr2 np.random.randint(0,100,size(2,4))
arr2 # 横向拼接 - 拼接的两者形状必须一致
h_two…
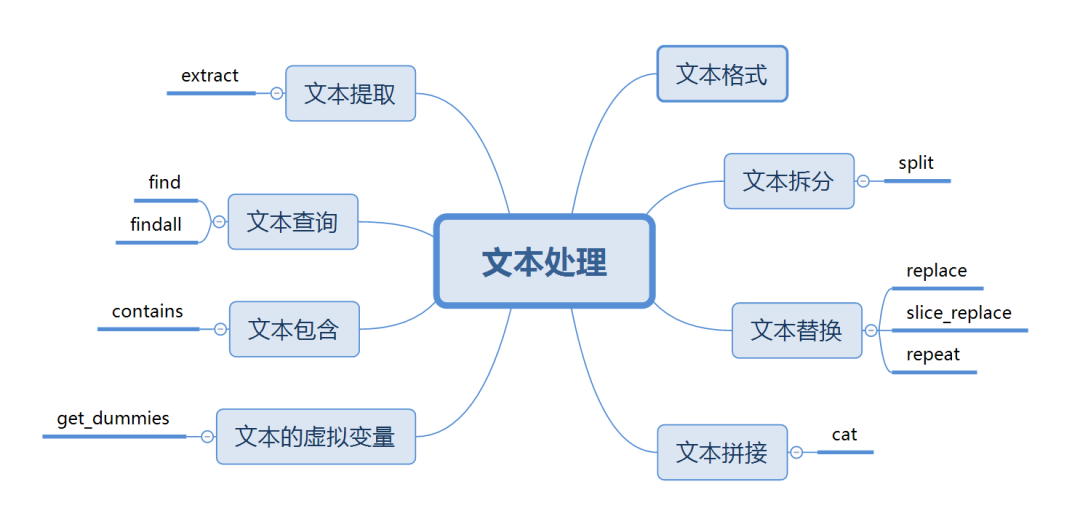
Pandas进阶:文本处理
引言
文本的主要两个类型是string和object。如果不特殊指定类型为string,文本类型一般为object。
文本的操作主要是通过访问器str 来实现的,功能十分强大,但使用前需要注意以下几点。 访问器只能对Series数据结构使用。 除了常规列变量df.c…

我不情愿的用了20多分钟,满足了学姐的要求,可是...
一、叙述(故事开端)
前某天,学姐约我偷偷的出去玩,说请我看电影emmm。。。。这没什么,那就去呗嘿嘿嘿~ 去??
去了我就后悔了,原来是找了一个公园,坐着看手机…
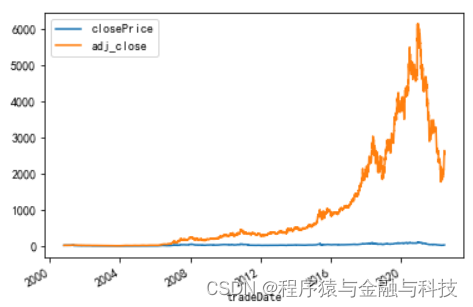
pandas_计算前复权收盘价和后复权收盘价
目录
已知条件:
概念描述: 开始计算: 读入数据 计算复权因子 计算前复权因子 计算后复权因子 计算前复权收盘价
计算后复权收盘价 数据: 本文以恒瑞医药上市以来至2022-07-06的数据作为讲解素材,数据在本文最后会提…
python通过索引更改dataframe中的列名
第一种方法:
pricedata.loc[:, price] pricedata.loc[:, 30%利润].rename(price)
这种方法首先使用loc方法选择"30%利润"列,然后使用rename方法将其重命名为"price"。但这只是创建了一个新的Series对象,并没有真正改变…
python的pandas模块使用总结
python的pandas模块 内容目录python的pandas模块一、创建二、基础属性信息三、数值信息四、数据过滤五、数据计算六、数据分析七、数据输出八、注意事项九、补充说明pandas是一个提供了数据操作和数据分析工具的模块。它支持两种主要数据结构:Series和DataFrame。 S…

chatgpt赋能python:Python怎么写表格:介绍与结论
Python怎么写表格:介绍与结论
在数据分析或者开发领域,表格是非常常见的数据展示形式。Python作为一门流行的编程语言,在表格的处理上也有很好的支持。今天我们来介绍一下Python怎么写表格。
1. Pandas库的使用
Pandas是Python中非常流行的…
第九章 数据可视化—pyecharts
9.1 pyecharts概述
pyecharts是一个针对Python用户开发的,用于生成ECharts图表的库,与matplotlib相比,pyecharts具有以下优势: 简洁的API使开发者使用起来非常便捷,且支持链式调用 程序可以轻松的集成至Flask,Sanic,Django等主流的Web框架中 程序可在主流的Jupyter Note…
Pandas分组函数groupby、聚合函数agg和转换函数transform
pandas中的分组函数groupby()可以完成各种分组操作,聚合函数agg()可以将多个函数的执行结果聚合到一起,这两类函数经常在一起使用。
groupby用法和参数介绍
groupby(self, byNone, axis0, levelNone, as_indexTrue, sortTrue, group_keysTrue, squeeze…

Pandas+Matplotlib 数据分析
利用可视化探索图表
一、数据可视化与探索图
数据可视化是指用图形或表格的方式来呈现数据。图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义。用户通过探索图(Exploratory Graph)可以了解数据的…
Pandas实战100例 | 案例 31: 转换为分类数据
案例 31: 转换为分类数据
知识点讲解
在处理包含文本数据的 DataFrame 时,将文本列转换为分类数据类型通常是一个好主意。这可以提高性能并节省内存。Pandas 允许将列转换为 category 类型。
分类数据类型: category 类型适用于那些只包含有限数量不同值的列&…
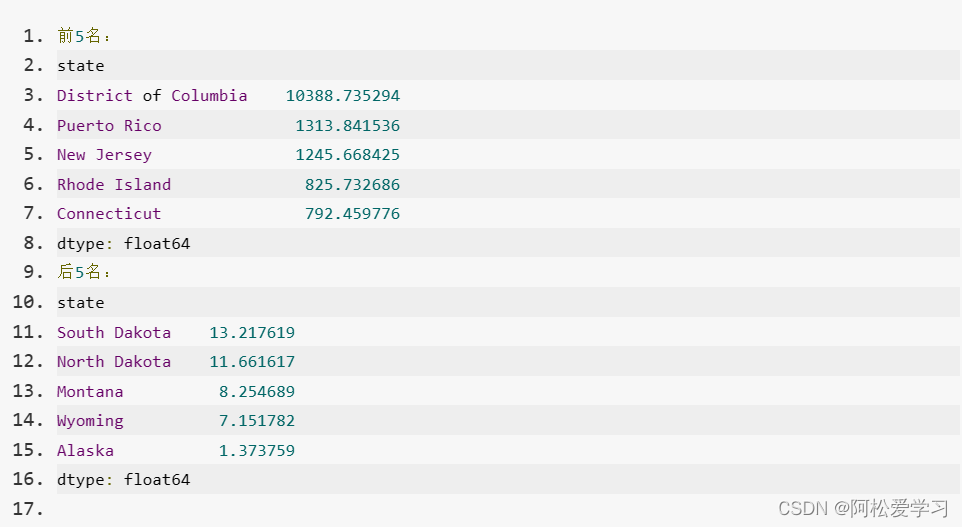
Pandas数据预处理Pandas合并数据集在线闯关_头歌实践教学平台
这里写目录标题 第1关 Concat与Append操作第2关 合并与连接第3关 案例:美国各州的统计数据 第1关 Concat与Append操作
任务描述 本关任务:使用read_csv()读取两个csv文件中的数据,将两个数据集合并,将索引设为Ladder列࿰…
pandas dataframe 怎么保留重复的行
要保留Pandas DataFrame 中的重复行,可以使用duplicated()方法和布尔索引。
下面是一个示例,演示如何实现这个功能:
import pandas as pd# 创建一个DataFrame对象
df pd.DataFrame({A: [apple, banana, apple, orange, banana, banana]})#…
Python常用Dataframe语句
删除列S# 方法1
df df.drop(S, axis1)
# 方法2
df.drop(S, axis1, inplaceTrue)删除列K中包含字符a的行df df[~df[K].str.contains(a)]删除列S中值不为1的行df df[df[S] ! 1]删除列S中值不为1,2,3的行df df[(df[S] ! 1) & (df[S] ! 2) & (df…
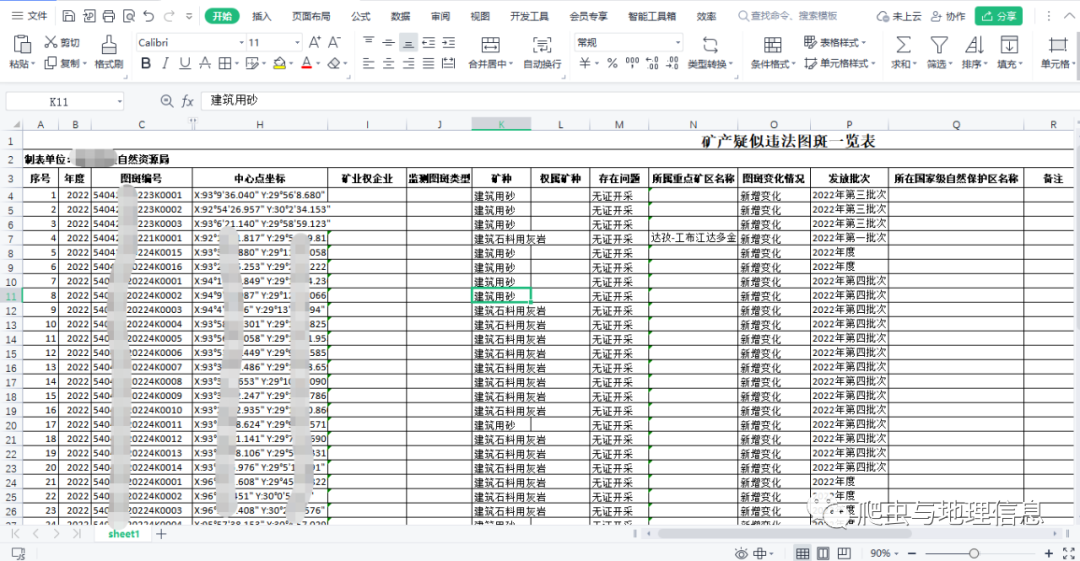
Python|矿产卫片Excel经纬度坐标数据转换为shp点数据——OGR库实现
1.实验需求
基于Excel表格里面的经纬度坐标数据,自动生成点shp矢量文件,并添加属性信息。 2.编程思路详解
①使用Pandas库读取原始矿产图斑列表表格;
xlsx_path = uC:\\Users\\YaoJun\\Desktop\\矿产图斑列表.xlsx
#sheet_name默认为0,即读取第一个sheet的数据
df = pd.…
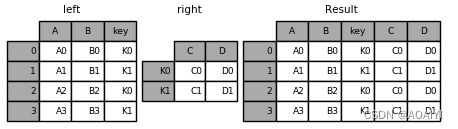
8. 比较concat, append, merge, join
8. 比较concat, append, merge, join 连接DataFrame
8.1 比较
连接方向 concat可以横向纵向连接对象;appned是纵向连接对象;merge和join是横向连接对象。 连接对象 concat,append一次可以连接多个对象,可以是多个Series、DataFr…
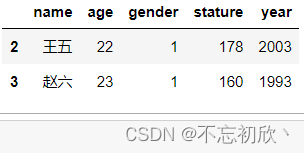
Pandas 常用按照查询条件筛选数据
文章目录1. 筛选指定的列2. 按照条件筛选3.1 单条件筛选3.2 多条件组合筛选创建一个DataFrame
import pandas as pd
data {name:[张三, 李四, 王五, 赵六],age:[20, 21, 22, 23], gender: [0, 1, 1, 1], stature: [165, 189, 178, 160], year: [2000, 2002, 2003, 1993]}
df …
pandas——DataFrame基本操作(二)【建议收藏】
pandas——DataFrame基本操作(二) 文章目录pandas——DataFrame基本操作(二)一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤1.修改数据2.缺失值3.合并1.concat合并2.使用append方法合并3.使用merge进行合并4.使用…
Pandas替换元素、字符串
替换元素
Pandas有多种方法替换元素,可以使用loc、numpy.where、mask、apply等。
loc
df = pandas.DataFrame({A: [1, 2, 2],B: [one, &
pandas数据分析(一)
一般而言,数据分析工作的目标非常明确,即从特定的角度对数据进行分析,提取有用
信息,分析的结果可作为后期决策的参考。
扩展库pandas是基于扩展库numpy和matplotlib的数据分析模块,是一个开源项目,提
供了大量标准数据模型,具有高效操作大型数据集所需要的功能,可以说pandas是…
chatgpt赋能Python-numpy转化为pandas
从Numpy到Pandas: 如何将数组转换为数据框
如果您正在使用Python进行数据分析,那么您一定会听说过Numpy和Pandas。他们是Python中最受欢迎的数据科学库之一,可以极大地简化数据处理的流程。但是,当您想从numpy数组转换为pandas数据框时&…
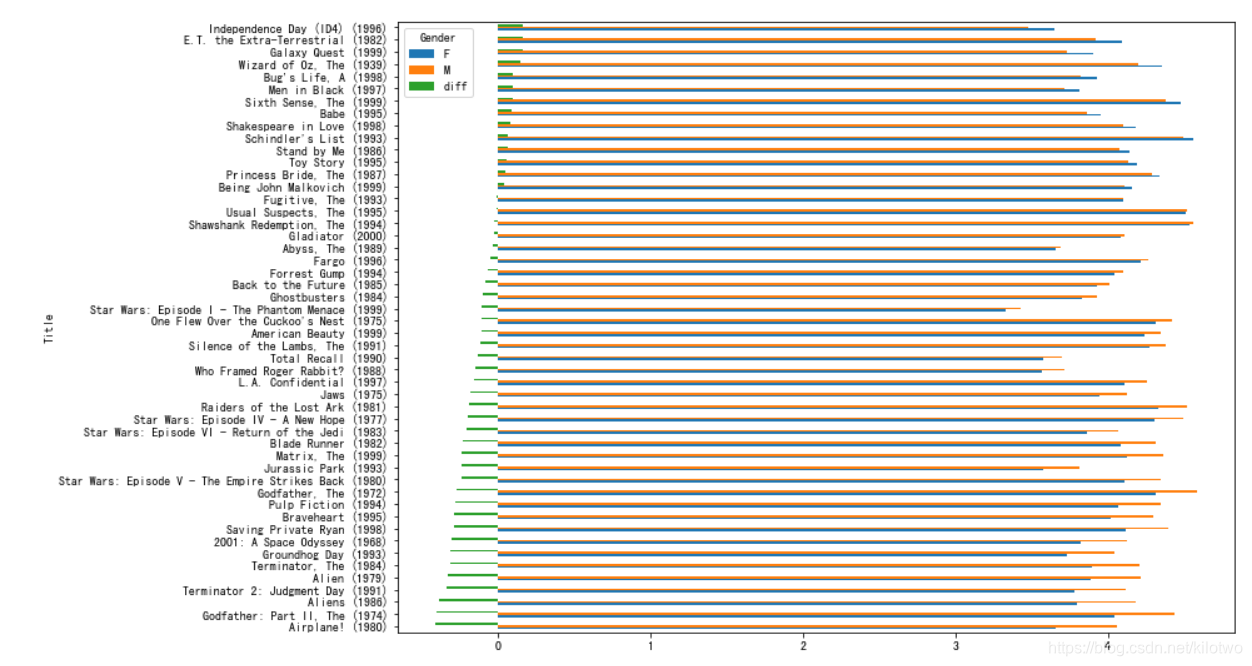
Pandas项目实战1——好莱坞百万级电影评论数据分析
文章目录好莱坞百万级电影评论数据分析Pandas 知识点任务需求1.导入所需库2.导入数据读取user读取Movie读取RATINGS3. 数据合并4.平均分较高电影5. 不同性别对电影评分6.不同性别争议最大的电影7.评论次数最多热门的电影8.查看不同年龄段争议最大电影9.每个年龄段用户评分人数和…
是时候告别 pd.read_csv() 和 pd.to_csv()
Pandas 到 CSV 的输入输出操作是序列化的,这使得它们极其低效且耗时。当我在这里看到足够的并行化范围时,我感到很沮丧,但不幸的是,Pandas 还没有提供此功能。尽管我一开始就不赞成使用 Pandas 创建 CSV(请阅读下面的文章了解原因),但我知道在某些情况下,人们别无选择,…
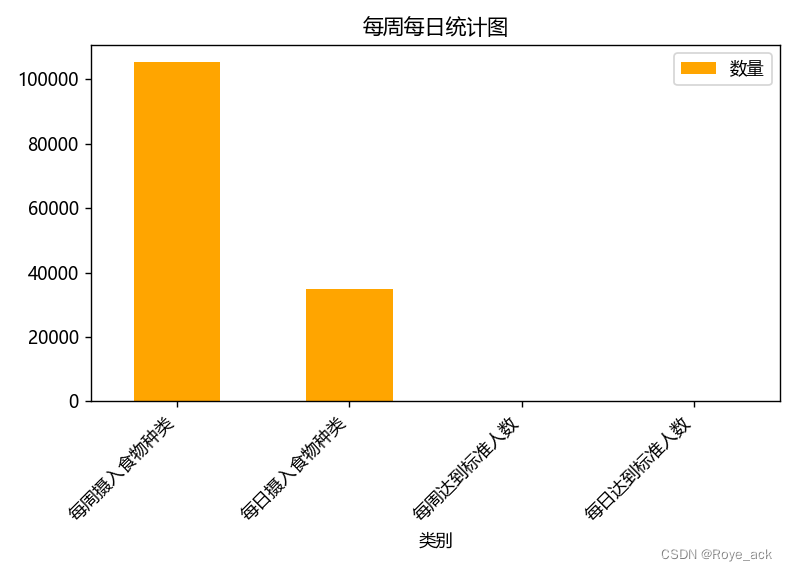
Python Pandas 处理Excel数据 制图
目录
1、饼状图
2、条形统计图 1、饼状图
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#from matplotlib.ticker import MaxNLocator
# 解决中文乱码
plt.rcParams[font.sans-serif][SimHei]
plt.rcParams[font.sans-serif]Microsoft YaHei …
pandas由入门到精通-数据清洗-分类数据
pandas-02-数据清洗&预处理 E. 分类数据1. 适用情况2. Categorical 扩展数据类型2.1 通过astype将一个Series转化为Categorical类2.2 通过pd.Categorical 生成Categorical类2.3 通过pd.Categorical.from_codes 将标签列表和整数列表转化为Categorical类2.4 Categorical类的…
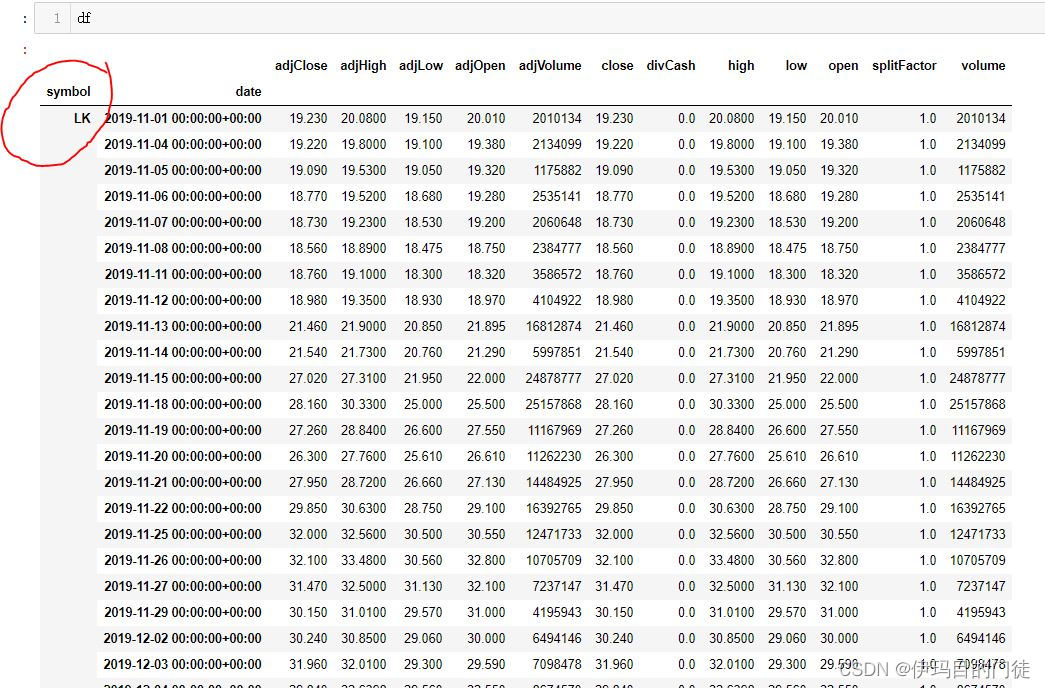
Pandas DataFrame的多重索引 MultiIndex 切片取单个df
#轴向转化函数 解决分组索引问题df1df.stack(0)
df1df1[LK].unstack()
找了好久的资料,也没有发现相关办法,我想要从一个多重索引下取到需要单独的小dataframe。就用这个土办法可以实现。
我大概浪费了一个半小时在这上面,希望把知识传递在…
python对多个csv文件进行合并(表头需一致)
之前写过python对【多个Excel文件】中的【单个sheet】进行合并,参考:点我
之前也写过python对【多个Excel文件】中的【多个sheet】进行合并,参考:点我
今天再写一个python对多个csv格式的文件进行合并的小工具
但是大家切记&am…
Python与数据分析--Pandas-1
目录 1.Pandas简介
2.Series的创建
1.通过数组列表来创建
2.通过传入标量创建
3.通过字典类型来创建 4.通过numpy来创建
3.Series的索引和应用
1. 通过index和values信息
2. 通过切片方法获取信息
4.DataFrame的创建
1.直接创建
2.矩阵方式创建
3.字典类型创建
5.…
![Python的pandas模块apply函数报KeyError: None of [['xxx', 'yyy','zzz']] are in the [index]](https://img-blog.csdnimg.cn/20181213193246358.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RhZXJ6ZWk=,size_16,color_FFFFFF,t_70)
Python的pandas模块apply函数报KeyError: None of [['xxx', 'yyy','zzz']] are in the [index]
问题重现
在用:Logistic算法做鸢尾花分类预测的时候遇见这么一个错误:
Traceback (most recent call last):File "/home/dong/.local/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 3267, in run_codeexec(code_obj, self.user_global_ns,…

数据分析与展示Pandas库复习
常用方法
官网: https://pandas.pydata.org/pandasdocs/stable/reference/api/pandas.DataFrame.to_excel.html
基础概念
引用:import pandas as pd Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用
与numpy区别
Numpy关注数据结构表…

pandas统计计算和描述
pandas统计计算和描述
常用统计计算: sum, mean, max, min axis0表示按列统计,axis1按行统计 skipna 排除缺失值,默认为True idmax, idmin, cumsum import numpy as np
import pandas as pddf_obj pd.DataFrame(np.random.randn(5,4), c…
pythonPandas四:数据操作与转换
当涉及到数据操作和转换时,Pandas提供了许多有用的功能。以下是一些示例说明: 数据选择和操作: import pandas as pd# 创建一个示例DataFrame
data {Name: [Alice, Bob, Charlie],Age: [25, 30, 35],City: [New York, London, Paris]}
df p…
Pandas JSON
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML。
JSON 比 XML 更小、更快,更易解析,更多 JSON 内容可以参考 JSON 教程。
Pandas 可以很方便…
Pandas数据分析Pandas进阶在线闯关_头歌实践教学平台
Pandas数据分析进阶 第1关 Pandas 分组聚合第2关 Pandas 创建透视表和交叉表 第1关 Pandas 分组聚合
任务描述 本关任务:使用 Pandas 加载 drinks.csv 文件中的数据,根据数据信息求每个大洲红酒消耗量的最大值与最小值的差以及啤酒消耗量的和。 编程要求…
pyqt5:pandas 读取 Excel文件或 .etx 电子表格文件,并显示
pip install pandas ;
pip install pyqt5; pip install pyqt5-tools;
编写 pyqt5_read_etx.py 如下
# -*- coding: utf-8 -*-
""" pandas 读取 Excel文件或 .etx 电子表格文件,显示在 QTableWidget 中 """
import os
import sys…
pandas读取tsv大文件(GB)方法
TSV文件和CSV的文件的区别是:前者使用\t作为分隔符,后者使用,作为分隔符。
使用pandas读取tsv文件的代码如下:
trainpd.read_csv(test.tsv, sep\t)如果已有表头,则可使用header参数:
trainpd.read_csv(test.tsv, se…

python数据处理----Pandas的数据类型
Numpy介绍
Numpy是一个开源的Python科学计算库,用于快速处理任意维度的数组。Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。 通过python的list嵌套也可以实现多维数组,为什么还要使用ndarray?
对比…
Python数据分析课程笔记·嵩天
Python数据分析课程笔记MatplotlibNumpyPandasMatplotlib
import matplotlib.pyplot as plt
plt.savefig(‘test’, dpi500) 存储图片默认为PNG格式 plt.plot([1,2,3]) plt.plot([1,2,3],[3,5,7]) plt.ylable(“Grade”) plt.axis([-1,10,0,6])横纵坐标尺度 plt.show()展示图…
pandas报错SettingWithCopyWarning
df2[user_cnt2] df2[user_id].apply(lambda x: user_cnt.get(x, 0))
df2[item_cnt2] df2[item_id].apply(lambda x: item_cnt.get(x, 0))
df2[shop_cnt2] df2[shop_id].apply(lambda x: shop_cnt.get(x, 0))报错位置如上。
报错信息:
A value is trying to be se…
Pandas:DataFrame对象的基础操作
DataFrame对象的创建,修改,合并 import pandas as pd
import numpy as np
创建DataFrame对象
# 创建DataFrame对象
df pd.DataFrame([1, 2, 3, 4, 5], columns[cols], index[a,b,c,d,e])
print df cols
a 1
b 2
c 3
d 4
e 5df2 …
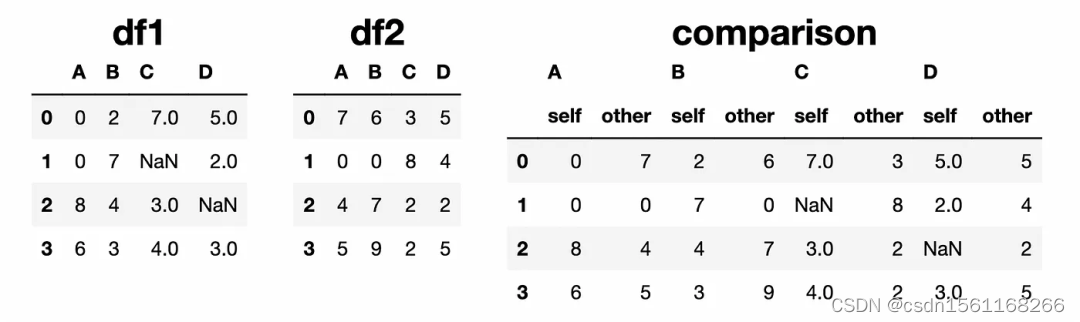
4个在Pandas DataFrame中进行元素比较的函数
大家好,Pandas DataFrame是具有标记行和列的二维数据结构。
有时我们需要对两个DataFrame进行逐个元素的比较。例如: 使用另一个DataFrame的值来更新其中的值。 比较数值,并选择较大或较小的值。
本文将介绍四个不同的Pandas函数…
60_Pandas中是否包含判断缺失值NaN并统计个数
60_Pandas中是否包含判断缺失值NaN并统计个数
下面介绍如何判断pandas.DataFrame、Series是否包含缺失值NaN以及如何统计缺失值NaN的个数。
使用 isnull()、isna() 确定每个元素的缺失值判断每一行/列的所有元素是否缺失值判断每一行/列是否至少包含一个缺失值计算每行/列的缺…
Python中Pandas中pd.DataFrame().loc()方法的使用
Pandas中pd.DataFrame().loc()方法的使用
pd.DataFrame().loc[] 是pandas中用于基于标签选择数据的方法。这个方法接受一个单一的标签,或者一个标签列表、切片对象、布尔型数组等作为输入,并返回一个符合条件的新DataFrame。
下面是一个简单的例子&…
Python数据科学常用库——Pandas
Python数据科学常用库——Pandas
一、数据格式Series
0x1 创建Series
import numpy as np
import pandas as pds1 pd.Series([1,2,3,4]) # 通过Python list创建s2 pd.Series(np.arange(10)) # 通过numpy array创建s3 pd.Series({1:1,2:2}) # 通过字典创建s4 Seri…

Pandas中DataFrame和array相互转化(DataFrame数据直接水平合并)
Pandas中DataFrame和array相互转化(DataFrame数据合并,非concat)
最近在写一个案例处理数据的时候,总是遇到DataFrame和array相互转化的问题,特此记录下来!
先说好本文章不是指DataFrame中的merge、join、…
pandas获取年月第一天、最后一天,加一秒、加一天、午夜时间
Timestamp对象
# ts = pandas.Timestamp(year=2023, month=10, day=15,
# hour=15, minute=5, second=50, tz="Asia/Shanghai")
ts = pandas.Timestamp("2023-10-15 15:05:50", tz="Asia/Shanghai")
# 2023-10-15 15:05…
【Python基础-Pandas】解决Pandas会自动把None转成NaN的问题
1. 背景
目前dataframe中的数据如下,power字段表示功率值,第一个值为20.0,第二个值为None。需要计算电量值,电量 功率 * 0.25,并保存到energy字段中,如果功率值为None,则电量值也为None。 pow…

pytest数据驱动 pandas
pytest数据驱动 pandas
主要过程:用pandas读取excel里面的数据,然后进行百度查询,并断言 pf pd.read_excel(data_py.xlsx, usecols[1,2])print(pf.values)输出:[[‘听妈妈的话’ ‘周杰伦’]
[‘遇见’ ‘孙燕姿’]
[‘伤心太平…
ERROR: Could not install packages due to an OSError: [Errno 13] Permission denied
报错内容: ImportError: C extension: DLL load failed: 拒绝访问。 not built. If you want to import pandas from the source directory, you may need to run ‘python setup.py build_ext --inplace --force’ to build the C extensions first.
报错原因&…

Python科学计算:Pandas
今天我来给你介绍Python的另一个工具Pandas。
在数据分析工作中,Pandas的使用频率是很高的,一方面是因为Pandas提供的基础数据结构DataFrame与json的契合度很高,转换起来就很方便。另一方面,如果我们日常的数据清理工作不是很复杂…
Python数据攻略-Pandas与统计数据分析
统计学在数据分析中到底有多重要?在数据分析的世界里,统计学扮演着一角色。想象一下你是《三国志》游戏的数据分析师,任务是找出哪个武将最受玩家欢迎,哪些战役最具挑战性等。
你怎么做呢?这就需要统计学的力量了。 文章目录 基础统计方法描述性统计方差和标准差相关性和…
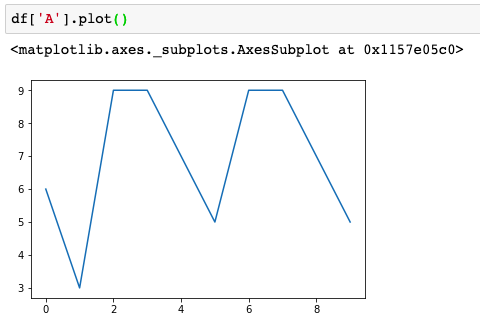
Pandas绘图之Series和Dataframe
Pandas绘图之Series和Dataframe
一、Series绘图
0x1生成数据并画图
首先生成一个series数据:
import numpy as np
import pandas as pd
from pandas import Series
import matplotlib.pyplot as plt
s1 Series(np.random.randn(10)).cumsum()直接绘制s1的图像&…
chatgpt赋能Python-pandas_归一化
Pandas归一化是什么?
数据归一化是数据预处理中的一个重要步骤,它能够将不同范围的数值转化为相同的数值范围。Pandas是一种数据处理工具,因此它提供了许多函数来实现数据归一化。其中最常用的函数是Normalization。
Normalization函数的使…

Python—Pandas学习之【排序sort】
Series
对于Series,排序的话有两种,沿着索引index或者沿着数值values,因此排序的时候要指明是按照哪种方式进行排序。 如果想要降序排列的话,使用ascending参数
DataFrame
1. 索引排序
对于DataFrame,沿着索引排…
pandas 笔记:get_dummies分类变量one-hot化
1 函数介绍
pandas.get_dummies 是 pandas 库中的一个函数,它用于将分类变量转换为哑变量/指示变量。所谓的哑变量,就是将分类变量的每一个不同的值转换为一个新的0/1变量。在输出的DataFrame中,每一列都以该值的名称命名
pandas.get_dummi…
Python数据攻略-Pandas时间序列数据处理
时间序列数据是一种特殊类型的数据,它按照时间的顺序排列。可以把时间序列数据想象成一个简单的日记或者时间线。在这种数据中记录了某个或多个变量随时间的变化。时间序列数据在很多领域都有应用,比如金融(股票价格、汇率)、气象(气温、降雨量)、医疗(患者心跳、血压)…
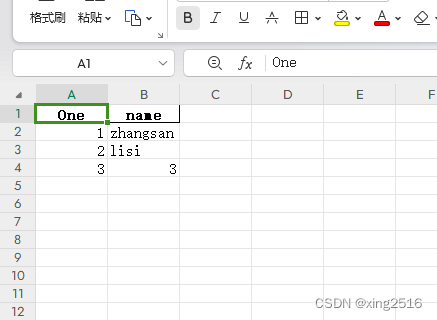
pandas.DataFrame() 数据自动写入Excel
DataFrame 表格数据格式 ; to_excel 写入Excel数据; read_excel 阅读 Excel数据函数
import pandas as pd#df2 pd.DataFrame({neme: [zhangsan, lisi, 3]})
df1 pd.DataFrame({One: [1, 2, 3],name: [zhangsan, lisi, 3]})#One是列明,123是…
利用pandas取出某列无重复的值
import pandas as pd
df pd.read_csv("…/shit.csv") df[‘x’].unique()#返回对应列的不同值 df[‘x’].nunique()#返回不同值的数值
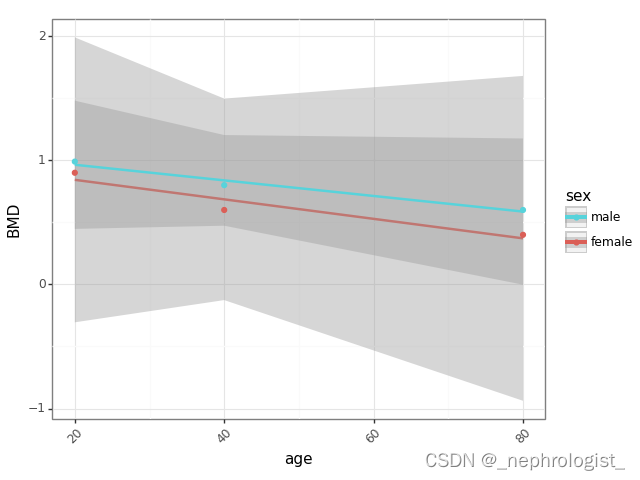
不同性别人群的股骨颈骨密度随年龄的变化趋势
增龄是发生骨质疏松的危险因素。因此,中老年人需要积极防范骨质疏松,以免发生骨折等不良事件。 为了探究不同性别人群的股骨颈骨密度随年龄的变化趋势,首先创建一个df,变量有id(编号)、age(年龄…
python-数据分析2csv
首先,我们需要导入数据并计算一些统计指标。请按照以下步骤操作:
使用pandas库的read_csv()函数导入CSV文件。 使用head()函数查看前五行。 使用info()函数查看数据类型和缺失值。 使用describe()函数查看数据统计指标。 以下是用于导入CSV文件并计算统…
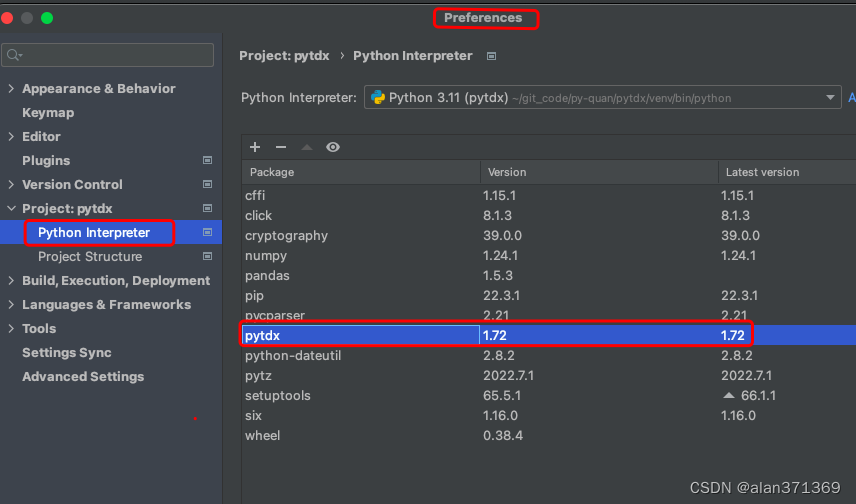
pytdx 安装 初步使用
pytdx 用户文档
Introduction pytdx
pytdx 的安装
MacBook-Air:~ xxx$ pip3 install pytdx
Collecting pytdx Downloading pytdx-1.72.tar.gz (80 kB) ━━━━━━━━━━━━━━━ 80.4/80.4 kB 215.0 kB/s eta 0:00:00 Preparing metadata (setup.py) ... done
Co…
Python Pandas 处理缺失值(第11讲)
Python Pandas 处理缺失值(第11讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔…
数据分析-Pandas如何轻松处理时间序列数据
Pandas-如何轻松处理时间序列数据
时间序列数据在数据分析建模中很常见,例如天气预报,空气状态监测,股票交易等金融场景。此处选择巴黎、伦敦欧洲城市空气质量监测 N O 2 NO_2 NO2数据作为样例。
python数据分析-数据表读写到pandas
经典…
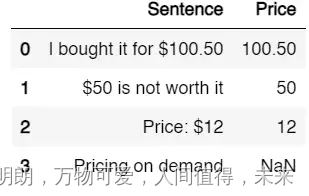
如何在 Python 和 Pandas 中使用正则表达式
什么是正则表达式
Regex 代表Regular Expression,是一种用于在文本中搜索模式的表达式。简而言之,它将匹配与模式对应的每个单词或单词组。在 Python 中,您可以使用正则表达式来搜索单词、替换单词、匹配一个单词或一组单词。基本上所有事情…
chatgpt赋能Python-pandas归一化
深入了解Pandas归一化:什么是归一化,为什么需要归一化?
Pandas是Python中最常用的数据分析库之一。Pandas提供了许多功能,使数据分析变得更加轻松。其中,归一化是数据分析中一个重要的概念,它将数据缩放到…
chatgpt赋能python:Python如何选取CSV某几列数据
Python如何选取CSV某几列数据
在数据处理过程中,CSV是一种非常常见的数据文件类型。CSV文件中的数据由逗号分隔的值(Comma-Separated Values)组成。处理CSV数据的任务之一是从CSV文件中选择特定的列数据,以进行数据分析或处理。在…

Python读取本地文件OSM文件中的路网数据结合CSV数据处理
编写一个Python程序,使它能读取本地文件OSM文件中的路网数据,并将csv文件中的时间速度和公交车设备号根据公交站点信息或者经纬度信息赋值到OSM路网数据中对应的路段上, 如果有些路段处于两个经纬度之间,赋值的时间则取前后经纬度…

数据规整:聚合、合并和重塑
目录一、层次化索引重排与分级排序根据级别汇总统计二、合并数据集数据库风格的DataFrame合并索引上的合并轴向连接合并重叠数据三、重塑和轴向旋转重塑层次化索引将“长格式”旋转为“宽格式”将“宽格式”旋转为“长格式”一、层次化索引
层次化索引(hierarchica…
Pandas.read_excel详解
文章目录基础知识语法参数详解-index_col参数详解-header参数详解-usecols参数详解-dtype其他参数多表读取顺带提一句如何用pandas写数据到excel基础知识
pandas 可以读取多种的数据格式,针对excel来说,可以使用read_excel()读取数据,如下&a…

Pandas入门实践2 -数据处理
为了准备数据进行分析,我们需要执行数据处理。在本节中,我们将学习如何清理和重新格式化数据(例如,重命名列和修复数据类型不匹配)、对其进行重构/整形,以及对其进行丰富(例如,离散化…
python os模块获取文件路径
1、# 获取当前工作目录的上一级目录 dir_path os.path.dirname(os.path.abspath(.))
2、获取当前路径:
# 获取当前脚本文件的绝对路径
script_path os.path.abspath(__file__)# 获取程序所在目录
dir_path os.path.dirname(script_path)3、获取当前路径的文件名…

IT人的晋升之路——关于人际交往能力的培养
对于咱们的程序员来说,工作往往不是最难的,更难的是人际交往和关系的维护处理。很多时候我们都宁愿加班,也不愿意是社交,认识新的朋友,拓展自己的圈子。对外的感觉就好像我们丧失了人际交往能力,是个呆子&a…
pandas中df.groupby详解?
df.groupby 是 pandas 库用于实现按照某些列进行拆分,应用函数和组合的一个功能。步骤如下: 1. 按照指定的一列或多列进行分组 (grouping) 2. 对每个分组应用一个聚合函数 (aggregation) 3. 将每个分组的聚合结果合并成一个数据结构 语法: df…

Python数据分析(3):pandas
文章目录二. pandas入门2.1 数据结构2.1.1 Series对象2.1.2 DataFrame对象2.2 读取数据2.2.1 读取Excel:read_excel()1. 读取特定工作簿:sheet_name2. 指定列标签:header3. 指定行标签:index_col4. 读取指定列:usecols…
数据导入与预处理-拓展-pandas可视化
数据导入与预处理-拓展-pandas可视化1. 折线图1.1 导入数据1.2 绘制单列折线图1.3 绘制多列折线图1.4 绘制折线图-双y轴2. 条形图2.1 单行垂直/水平条形图2.2 多行条形图3. 直方图3.1 生成数据3.2 透明度/刻度/堆叠直方图3.3 拆分子图4. 散点图4.1生成数据4.2 绘制大小不一的散…

数据分析 | Pandas 200道练习题,每日10道题,学完必成大神(6)
文章目录前期准备1. 使用绝对路径读取本地Excel数据2. 查看数据前三行3. 查看每一列数据缺失值情况4. 提取日期列含有空值的行5. 输出每列缺失值具体行的情况6. 删除所有缺失值的行7. 绘制收盘价的折线图8. 同时绘制开盘价与收盘价9. 绘制涨跌的直方图10. 让直方图给更细致本章…

晶飞FLA5000光谱仪.FlaSpec文件数据解析
引言
首先说明下晶飞上位机软件存在的问题,实验所采用的FLA5000型号光谱仪,光谱波段从280-970nm,FWHM值为2.4nm。 1、上位机软件中的光谱数据复制功能基本是废的,最多只能到599.9nm,后面的数据全部消失。 2、上位机软…
Python使用模拟退火(Simulated Annealing)算法构建优化器获取机器学习模型最优超参数组合(hyperparameter)实战+代码
Python使用模拟退火(Simulated Annealing)算法构建优化器获取机器学习模型最优超参数组合(hyperparameter)实战+代码 目录

【Pandas】18 小练习
#【Pandas】18 小练习 2023.1.16 两个pandas小练习
18.1 疫情数据分析
18.1.1 观察数据
import pandas as pd
import osdf pd.read_csv("data/covid19_day_wise.csv")
dfDateConfirmedDeathsRecoveredActiveNew casesNew deathsNew recoveredDeaths / 100 CasesR…
](https://img-blog.csdnimg.cn/9712415c3add452f943c523eadc6605a.png)
快速入门pandas进行数据挖掘数据分析[多维度排序、数据筛选、分组计算、透视表](一)
1. 快速入门python,python基本语法
Python使用缩进(tab或者空格)来组织代码,而不是像其 他语言比如R、C、Java和Perl那样用大括号。考虑使用for循 环来实现排序算法: for x in list_values:if x < 10:small.append(x)else:bigger.append(x)标量类型 …

2023年,云计算还有发展前景吗?
云计算在促进经济回暖中扮演者不可或缺的角色,疫情期间复工复产都是基于云计算的基础设施,实现远程办公、在线学习、在线看病、在线政务等等。同时由于数字技术在各个领域的渗透和发展,社会整体对于云技术人才、云服务、算力服务等的需求都在…
Numpy-如何对数组进行叠加
前言 本文是该专栏的第23篇,后面会持续分享python的数据分析知识,记得关注。
之前有详细介绍过,numpy替换元素和numpy改变数组形状的方法。本文再来详细介绍下,在数据分析项目上使用numpy如何对数组进行叠加。想了解数组元素替换和改变数组形状的方法,亦或是想了解更多nu…
学以致用——植物信息录入1.0(selenium+pandas+os+tkinter)
目的
书接上文,学以致用——植物信息录入(seleniumpandasostkinter)
更新要点:
tkinter界面:自动登录、新增(核心功能)、文件夹选择、流程台selenium自动化操作:验证码识别excel数据…
python数据处理----Apply自定义函数和向量化函数
什么是Apply自定义函数? Pandas提供了很多处理数据的API,如果自己的需求不能被这些API满足的时候,我们就需要写自定义函数使用apply函数 apply函数接收一个自定义函数,将DataFrame的 行/列 数据传递给自定义函数处理。 apply函数…

python数据处理----Pandas类型转换
转换为字符串类型
tips[sex_str] tips[sex].astype(str)转换为数值类型 转为数值类型还可以使用to_numeric()函数
DataFrame每一列的数据类型必须相同,当有些数据中有缺失,但不是NaN时(如missing,null等),会使整列数…
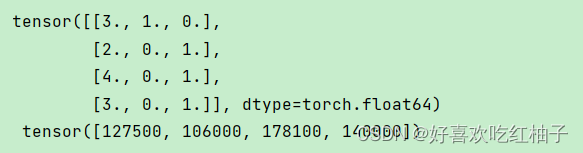
动手学深度学习v2—01数据操作+数据预处理
[TOC]此次用到的虚拟环境:pytorchmwy项目名称:limuAI所需框架和工具:pytorch,pandas一、创建CSV文件所需工具:pandas在与项目同等目录下创建一个文件夹名为data,其中文件名称为house_tiny.csv。代码如下&am…

python列表逆序排列的方法
python中的列表是可以直接进行逆序排列的,但是在 python中,逆序排列也是有一定规则的,一般是按升序排序,也就是从左到右。比如 list[1,2,3,4]; 注意:顺序相同的元素可以放在同一行; 在 python中…
python数据处理----pandas导入和导入文件
pickle文件的导入和导出:
保存为pickle文件: 读取pickle文件: csv文件的导入和导出
保存为csv文件:
Excel文件的导入和导出
保存为Excel文件:
Series数据对象不能保存为Excel,需要转成DataFrame才能保…
【python pandas】合并文件并剔除重复数据
1.背景 工作中需要处理多个文件,每个文件里面有重复的数据,剔除重复数据,保留最新的数据
2.代码:
import pandas as pd
import osdl []
#person_list是文件路径
for i in range(person_list_len):#把文件df全部集合进列表dldl.a…
【数据挖掘与商务智能决策】第二章 特征工程与数据预处理
数据预处理
非数值类型数据处理
Get_dummies哑变量处理
1. 简单示例:“男”和“女”的数值转换
import pandas as pd
df pd.DataFrame({客户编号: [1, 2, 3], 性别: [男, 女, 男]})
df客户编号性别01男12女23男
df pd.get_dummies(df, columns[性别])
df客户…
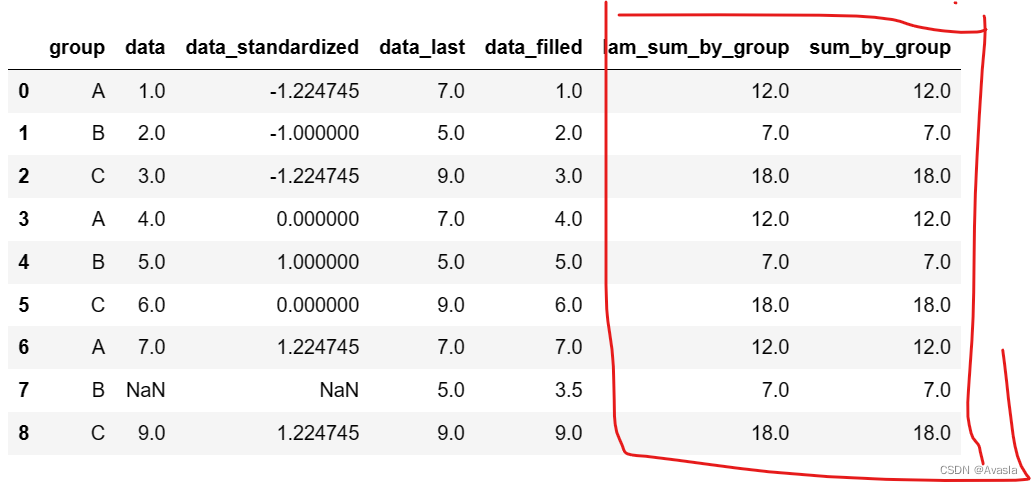
Python数据分组计算利器:Transform函数
使用Python进行数据清洗时,需要对数据进行分组计算,一般使用’goupby计算函数’,但是返回的结果并不是原来表格的格式。或者是使用遍历的方式,将每组计算的结果返回到原表格中。
Transform是Pandas中的一个函数,它用于…

用Python解决Excel问题的最佳姿势
大家好,我是毕加锁。
今天给大家带来的是用Python解决Excel问题的最佳姿势
文末送书! 文末送书! 文末送书! 「问题说明」
这次要处理的excel有两个sheet,要根据其中一个sheet的数据来计算另外一个sheet的值。造成问…
chatgpt赋能Python-python3求平均值
Python3求平均值-从基础到实践
Python3作为一种广泛使用的编程语言,被广泛应用于不同的领域。今天我们将探讨如何使用Python3求平均值。求平均值在数学和统计学中非常常见,使我们能够了解数据的中心趋势,并简化数据分析过程。让我们深入了解…
Pandas数据框、序列定义及数据处理应用在线实验闯关
Pandas数据框、序列定义及数据处理应用在线实验闯关 文章目录 Pandas数据框、序列定义及数据处理应用在线实验闯关一、序列和数据框1、任务描述2、相关知识定义列表和元组序列定义方法构造数据框3、任务实现二、外都数据文件读取1、任务描述2、相关知识读取文件分块读取数据3、…
python中pandas模块数据处理小案例
内容目录1. 添加随机日期2. 聚合求和3.聚合求和排序4. 聚合求和排序取前十5. 聚合取极值6. 重新赋值7. 按条件赋值pandas作为数据处理的得力工具,简便了数据开发过程,之前串联了pandas的使用方法,现在用几个小案例巩固一下常用的pandas方法。…

Pandas-如何对指定某列的NaN值进行替换或填充
前言 本文是该专栏的第31篇,后面会持续分享python数据分析的干货知识,记得关注。
笔者在本专栏之前有单独详细介绍过,使用Numpy对数组元素进行替换的方法,感兴趣的同学,可翻阅查看“Numpy-如何对数组的元素进行替换”。
而本文来单独介绍pandas对指定列的NaN值进行操作的…

Pandas的DataFrame的生产,DF数据查看
这篇文档介绍了 Pandas 的入门使用方法。Pandas 是 Python 的一个数据分析库,可以方便地操作数据和进行数据分析。 本节以下列方式导入 Pandas 与 NumPy:
In [1]: import numpy as npIn [2]: import pandas as pd#生成对象
用值列表生成 Seriesopen in…
Geospatial Data Science (9): Spatial networks
Geospatial Data Science (9): Spatial networks
import geopandas as gpd
import osmnx as ox
import numpy as np
import networkx as nx
import pandas as pdfrom haversine import haversine, haversine_vectorimport matplotlib.pyplot as plt
from scipy
10个Pandas的另类数据处理技巧
本文所整理的技巧与以前整理过10个Pandas的常用技巧不同,你可能并不会经常的使用它,但是有时候当你遇到一些非常棘手的问题时,这些技巧可以帮你快速解决一些不常见的问题。 1、Categorical类型
默认情况下,具有有限数量选项的列都…
pandas数据连接
pandas数据连接
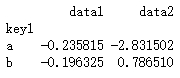
pd.merge
import pandas as pd
import numpy as npdf_obj1 pd.DataFrame({key: [b, b, a, c, a, a, b],data1 : np.random.randint(0,10,7)})
df_obj2 pd.DataFrame({key: [a, b, d],data2 : np.random.randint(0,10,3)})print(df_obj1)
print(------------…

【原创佳作】这个Python模块太厉害了,一行代码生成Tableau可视化图表
今天给大家介绍一个十分好用的Python模块,用来给数据集做一个初步的探索性数据分析(EDA),有着类似Tableau的可视化界面,我们通过对于字段的拖拽就可以实现想要的可视化图表,使用起来十分的简单且容易上手,学习成本低&a…
Pandas模块之Series:02-索引
Series结构的索引方式有以下四种:
位置下标标签索引切片索引布尔型索引
位置下标
位置下标从0开始。 输出结果为numpy的数据格式,可以通过python数据函数转换为python格式。
s pd.Series(np.random.randint(low 1,high 10,size 5))
print(s)
prin…
【Python】如何实现Cche的功能(详细教学)
文章目录介绍一、pandas是什么?二、基本 Cache 的使用1.引入库二,其他 Cache 的使用三,特殊 TTLCache 的使用四,大小计算总结—近期要实现一个小的功能:我需要在短期内对某些数据进行快速查询、修改等操作,…
59_Pandas中使用describe获取每列的汇总统计信息(平均值、标准差等)
59_Pandas中使用describe获取每列的汇总统计信息(平均值、标准差等)
使用 pandas.DataFrame 和 pandas.Series 的 describe() 方法,您可以获得汇总统计信息,例如每列的均值、标准差、最大值、最小值和众数。
在此,对…

数据分析 | Pandas 200道练习题 进阶篇(3)
文章目录DA21 大佬用户成就值比例DA22 牛客网用户最高的正确率DA23 统计牛客网用户的名字长度DA24 去掉信息不全的用户DA25 修补缺失的用户数据DA26 解决牛客网用户重复的数据总结:❤️ 作者简介:大家好我是小鱼干儿♛是一个热爱编程、热爱算法的大三学生…
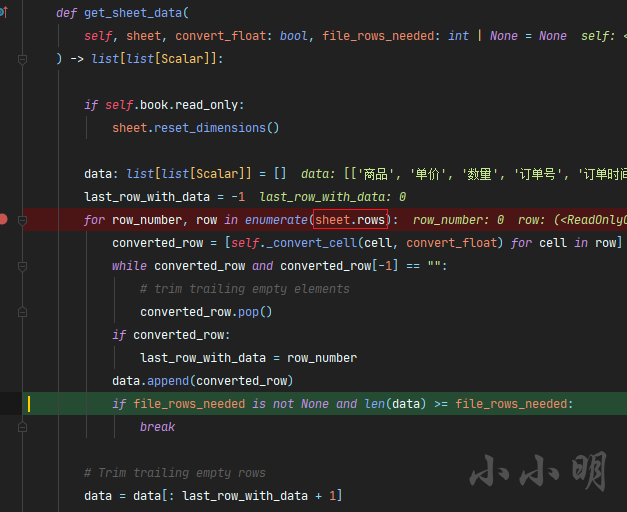
pandas读取Excel核心源码剖析,面向过程仿openpyxl源码实现Excel数据加载
📢作者: 小小明-代码实体 📢博客主页:https://blog.csdn.net/as604049322 📢欢迎点赞 👍 收藏 ⭐留言 📝 欢迎讨论! 今天我们将研究pandas如何使用openpyxl引擎读取xlsx格式的Excel的…
pandas汇总和描述性统计
本文介绍pandas中汇总和描述性统计中的基本内容,仅供参考。
目录
1描述和汇总统计
1.1sum方法
1.2idxmin和idxmax方法
1.3describe方法
1.4描述和汇总统计的常用方法
2相关系数和协方差
3唯一值、值计数以及成员资格
3.1唯一值
3.2值计数
3.3成员资格
1…
比较系统的学习 pandas (6)
pandas 数据类型转换
在开始数据分析前,有时需要为数据分配好合适的类型,这样才能 够高效地处理数据
# 对所有字段指定统一类型
data pd.DataFrame(data, dtypefloat32)
# 对每个字段分别指定
data pd.read_excel(data.xlsx, dtype{name: string, sc…

pandas数据聚合和重组
介绍pandas数据聚合和重组的相关知识,仅供参考。
目录
1GroupBy技术
1.1简介
1.2对分组进行迭代
1.3选取一个或一组列 1.4通过字典或Series进行分组
1.5利用函数进行分组
2数据聚合
2.1简介
2.1面向列的多函数应用
2.2以‘无索引’的方式返回聚合数据
1G…
Microsoft Power BI部署方案
目录
前言
一、部署环境概述
二、Azure 账户创建
三、创建虚拟机,安装 SQL Server
四、配置虚拟网络环境
五、安装 Power BI 服务端
六、创建 Power BI 环境及 Power BI 门户
七、配置数据网关
八、上传数据集、创建报表
九、发布共享内部报表
十、设置安…

如何利用TURF分析来对餐厅菜品进行组合搭配?
1.数据源说明
1.1 数据简单说明
本数据源采用的是某餐厅8月份的销售明细表。本文会主要用到一下字段值:
order_id, 产品订单号dishes_name,菜品名称counts, 消费数量amounts,消费金额
1.2 数据截图
以下是数据源的截图
1.3…

Pandas数据分析深入浅出
3.Pandas的数据查询 文章目录3.Pandas的数据查询前言一、Pandas查询数据的几种方法二、Pandas使用df.loc查询数据的方法2.1 使用单个的label值查询数据2.2 使用值列表批量查询2.3 使用数值区间进行范围查询2.4 使用条件表达式查询2.5 调用函数查询总结前言
笔者最近正在学习Pa…
【python与数据分析】Tushare库详解(1)
目录 前言
1.使用对象
2.使用前提
3.下载安装
4.版本升级
一、交易数据
1.历史行情
2.【案例应用_1】
(1)使用tushare包获取某股票的历史行情数据
(2)假如我从2010年1月1日开始,每月第一个交易日买入1手股票&…
【Python基础-Pandas】dataframe中将两个日期间的数据补全
1. 目的
目前dataframe中的数据如下,每一行数据表示的该日之前的那一周的平均价格指数,比如第一行数据为data_time2023-04-06, price_index132,表示从2023-03-29到2023-04-05之间的7天的价格指数的平均值为132。现在需要将这些间隔的日期中的…
OpenCV4入门到进阶
OpenCV4入门到进阶
第1章 介绍与学习指南 第2章 OpenCV开发环境搭建 第3章 图像&视频的加载与展示 第4章 OpenCV必知必会基础 第5章 OpenCV实现图形的绘制 第6章 OpenCV的算术与位运算 第7章 图像基本变换 第8章 OpenCV中的滤波器 第9章 OpenCV中的形态学 第10章 目标识别…

【011】pandas处理数据的作用_#py
pandas操作 1. 导入数据库2. 修改行列名2.1 修改列名2.2 修改行名 3. 按条件筛选3.1 根据条件筛选,提取所有信息3.2 根据条件筛选,提取某列或者某几列 4. 按某行某列提取信息4.1 获取信息4.2 更改具体的值 5. 合并5.1 单列并入大数据中(方法一…
Python数据分析script必备知识(三)
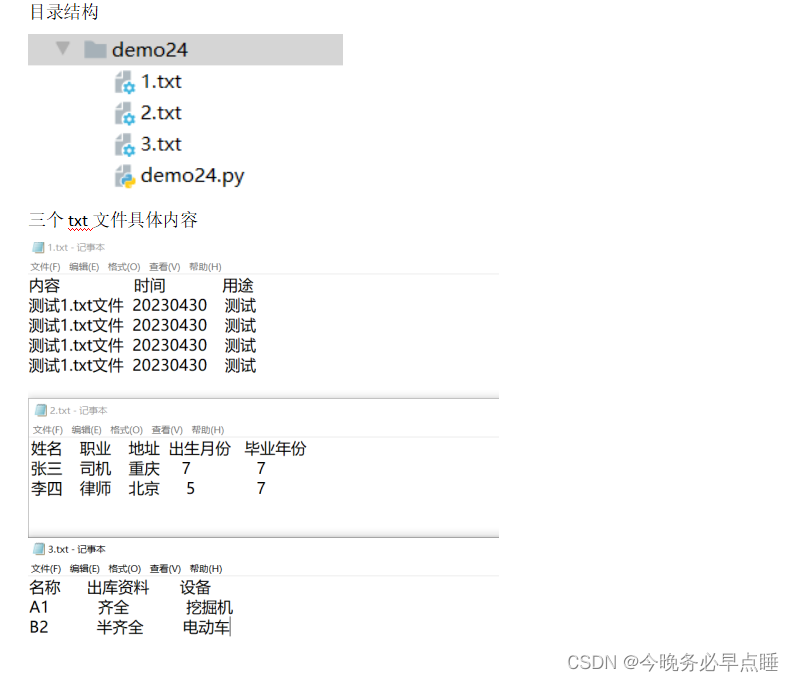
Python数据分析script必备知识(三)
1.单个文件,双个文件,三个文件的读取方式
新建1.txt文件,2.txt文件,3.txt文件,效果如下 执行代码
"""
单文件,双文件,三文件的读取方式Python的读写
file.read() ———— 一次性读取整个文件内容,推荐使用re…
Python大数据处理利器,PySpark的入门实战
PySpark极速入门
一:Pyspark简介与安装
什么是Pyspark?
PySpark是Spark的Python语言接口,通过它,可以使用Python API编写Spark应用程序,目前支持绝大多数Spark功能。目前Spark官方在其支持的所有语言中,…

python数据处理----数据合并
连接数据
加载多份数据连接
# 读取数据
df1 pd.read_csv(../data/concat_1.csv)
df2 pd.read_csv(../data/concat_2.csv)
df3 pd.read_csv(../data/concat_3.csv)
print(df1)
print(df2)
print(df3)# 连接数据 concat([数据1,数据2])方法
row_concat pd.concat([df1,df2…

python中pandas库的iloc函数用法
在 Pandas 中,.iloc 是一种用于基于整数位置进行索引的属性,可以用于获取 DataFrame 或 Series 中的数据。.iloc 支持多种索引方式,包括以下常用方式:
1. 单个整数位置索引
使用整数索引获取 DataFrame 或 Series 中的单个元素。…

python数据处理----分组和聚合计算(入门)
分组
# 读取tsv文件,分隔符为\t
df pd.read_csv(../data/gapminder.tsv,sep\t)
print(df)groupby(以xx字段分组)
以年份分组,查看所有国家年龄的平均值:
df.groupby(year)[lifeExp].mean()大洲为亚洲,以年份分组,…
事件分析法python实现分析事件对股价的冲击
我本身在做非全日制研究生的作业,于是我把研究过程用到的代码开源了,供更多的金融和经济专业的同学借鉴。
事件研究法(EventStudy)用于评估某一事件的发生或信息的发布,是否会改变投资人的决策,进而影响股…
pandas计算全部列中空值和非空值的个数
假设存在数据集data: 计算空值个数:
data.isnull().sum()计算非空值个数:
data.notnull().sum()计算NaN个数: data.notna().sum()isna()和notna()是isnull()和notnull()的别名,它们的用法是一样的
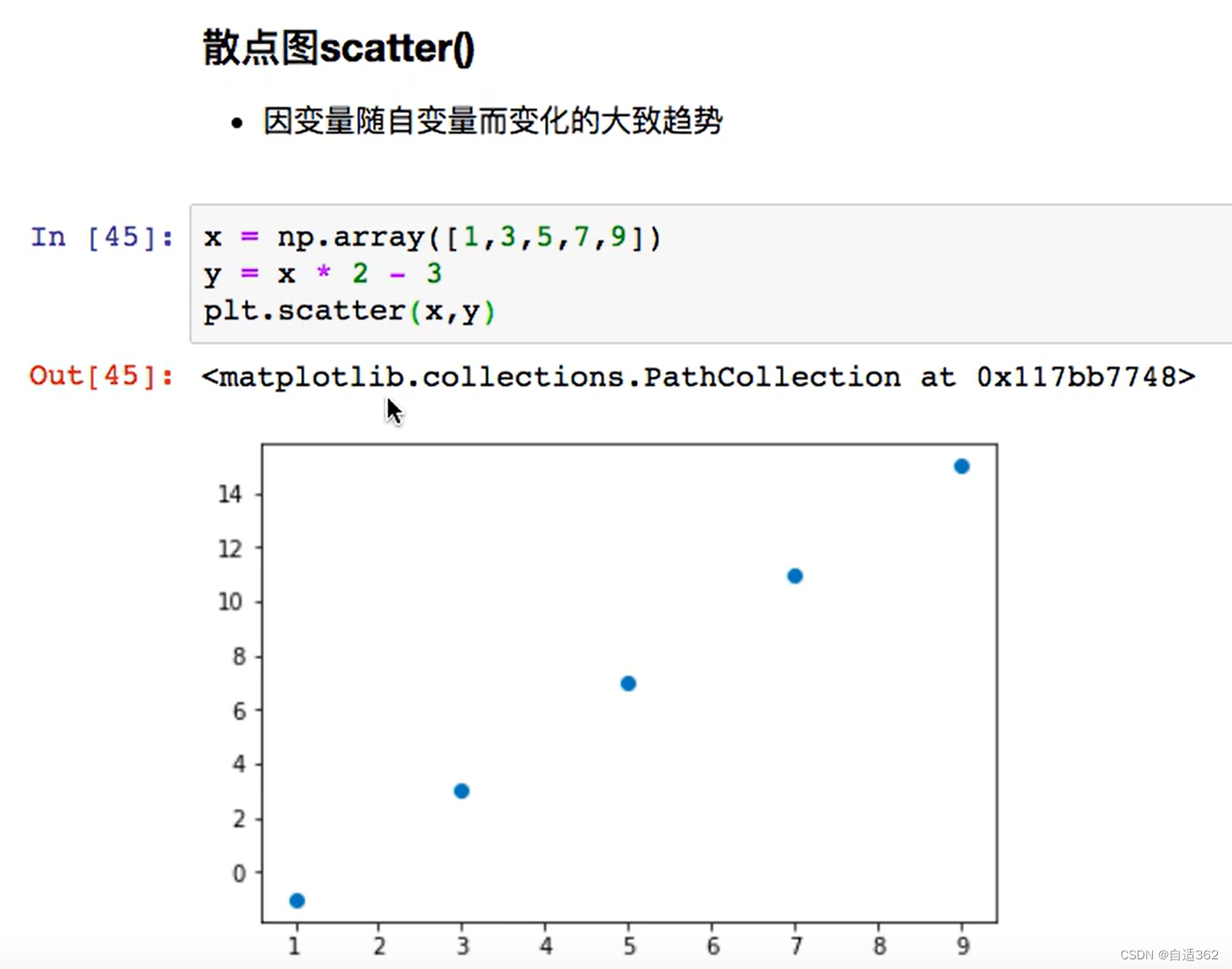
19.Pandas怎样对每个分组应用apply函数?
Pandas怎样对每个分组应用apply函数? 知识:Pandas的GroupBy遵从split、apply、combine模式
这里的split指的是pandas的groupby,我们自己实现apply函数,apply返回的结果由pandas进行combine得到结果
GroupBy.apply(function) function的第一…
Python Pandas新人必备入门教程
**
Python Pandas的使用简介
**
import pandas as pd
import numpy as np1.Series
s pd.Series([1,3,6,np.nan,44,1])
print(s) # 索引在左边,值在右边
print(s.values) # 输出值
print(s.index) # 输出索引
# 默认索引从0开始,可以自己指定索引…
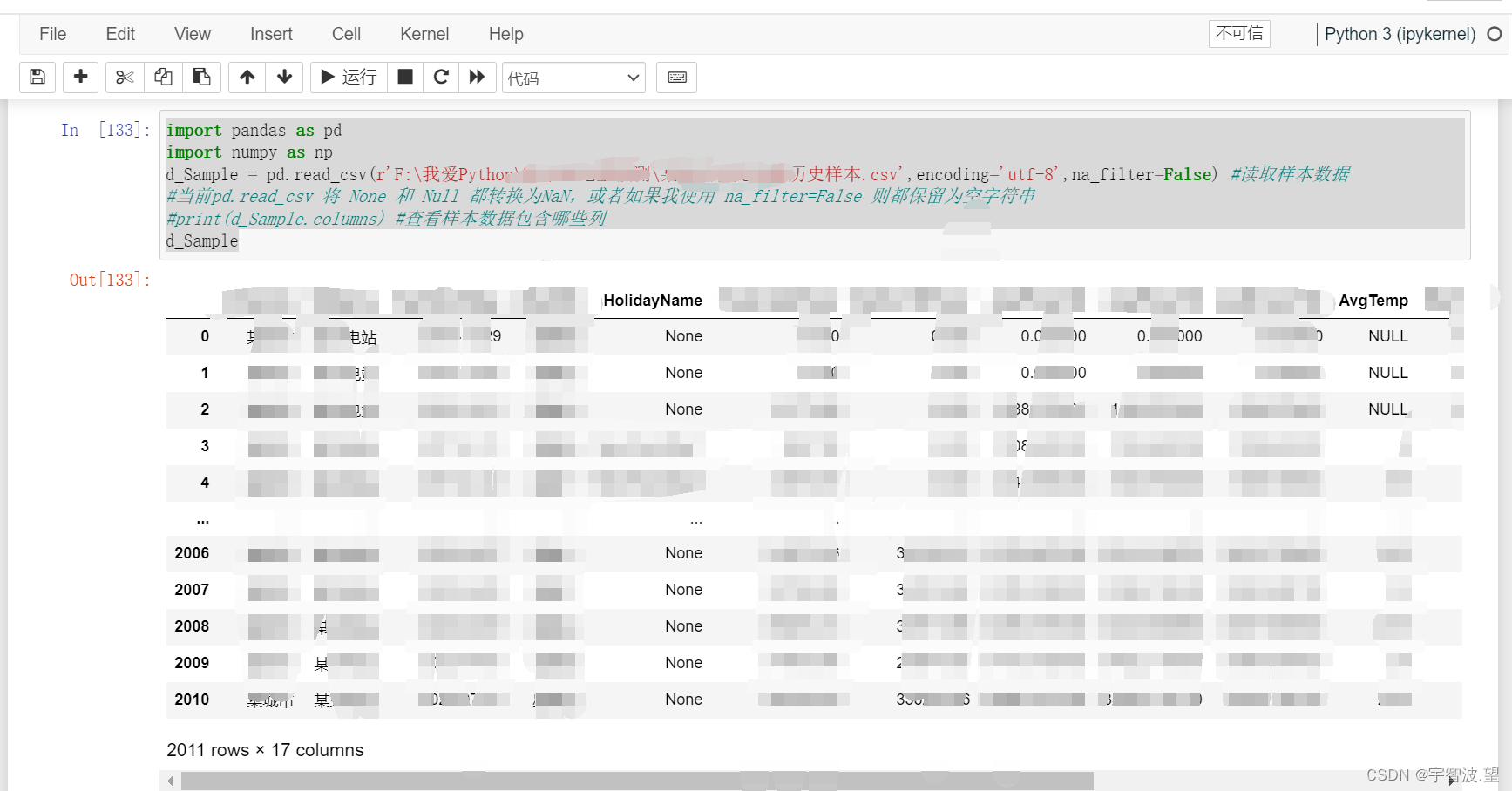
【Python】 【Pandas 】【read_csv()】Pandas库的read_csv()方法的使用,处理:None,NULL
近期,使用read_csv的时候,遇到一个问题,就是本地读取的csv文件中的数据有None和NaN 两种,如: 直接使用
pd.read_csv(rF:\我爱Python\预测\历史样本.csv,encodingutf-8)发现读取的数据是将None 和 NULL 直接处理成 NaN…
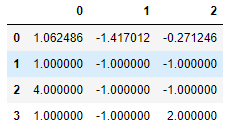
pandas数据操作
pandas数据操作
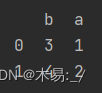
索引操作: series索引 ser_obj[‘label’] 通过索引名称访问 ser_obj[pos] 索引位置访问 import pandas as pdser_obj pd.Series(range(5), index [a, b, c, d, e])
print(ser_obj.head())
print(--------------)# 行索引
print(通过索引名称&am…
chatgpt赋能python:Python:寻找一组数中的最大值和最小值
Python:寻找一组数中的最大值和最小值
在数值计算和数据处理中,常常需要找出一组数中的最大值和最小值。Python提供了一些内置函数和库来实现这个任务。在本文中,我们将介绍如何使用Python来查找一组数的最大值和最小值,并提供一…
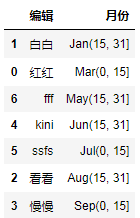
pandas自定义排序规则
from pandas.api.types import CategoricalDtypea [红红,白白,看看,慢慢,kini,ssfs,fff]
b ["Mar(0, 15]","Jan(15, 31]","Aug(15, 31]","Sep(0, 15]","Jun(15, 31]","Jul(0, 15]","May(15, 31]"]
df…
Pandas 读取,写入csv文件
读取csv文件
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import sysdfpd.read_csv(E:/python/wangyiPython/the fifth week/data/ex1.csv)
dfdf1pd.read_table(E:/python/wangyiPython/the fifth week/data/ex1.csv,sep,) #分隔符为逗号
df…

使用pandas连接数据库和输出数据库的常见问题
使用哪个包连接数据库
在使用pandas读取和写入数据库的时候,最好不要用pymssql直接去连服务器,读取数据可能不会出问题,但是在写入的时候,会出现一系列的问题。推荐使用sqlalchemy库
import pandas as pd
import pymssql
import…
chatgpt赋能python:Python个人数据合并:简单优雅地整合您的个人数据
Python个人数据合并:简单优雅地整合您的个人数据
在信息时代,我们收集了大量的个人数据,包括社交媒体、电子邮件、日历事件和其他各种来源。但是,如何以整洁的方式将这些数据整合到同一地方?Python提供了一种简单而优…

简单解决八皇后问题与n皇后问题
努力是为了不平庸~
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。
目录
一、问题描述
二、问题解决思路
1. 建立数据结构:
2. 约束条件的实现:
3. 结果展示:
4. 拓展至n皇…
chatgpt赋能python:Python将空格改为换行符
Python将空格改为换行符
在Python编程中,经常需要对字符串进行处理,其中包括将空格替换为换行符。这篇文章将会介绍如何使用Python来实现这个目标,并分享一些关于字符串处理的技巧。
为什么要将空格改为换行符
将空格改为换行符可以让文本…

数据分析三剑客:Numpy、Pandas、Matplotlib(你想看的这里都有,超详细版本)
写在前面的话:一直以来,笔者都非常想尝试将所学的知识体系化从而搭建出一名数据分析师应该具备的知识框架与数据处理能力,三剑客将是这条路的起点,本文为笔者原创,耗费近一周左右的私人时间,原创不易,希望读者盆友们多多指正,时间有限,文中出现的错误也希望大家指正,…

DataFrame的描述性统计方法
一、相关性和协方差
pct_change函数
语法:df.pct_change() 功能:表示当前元素与先前元素的相差百分比,即“(当前元素-先前元素)/ 先前元素”
corr函数
语法:df.corr() #返回整个数据表的相关系数矩阵 df.column01.corr(df.col…

Python—Pandas学习之【DataFrame.add函数】
格式:DataFrame.add(other, axis‘columns’, levelNone, fill_valueNone) 等价于dataframe other,但是支持用fill_value替换其中一个输入中缺失的数据。如果使用反向版本,即为radd。 举例说明 : add函数就是指df1df2。 对于df…

数据分析-Pandas如何重塑数据表
数据分析-Pandas如何重塑数据表
数据表,时间序列数据在数据分析建模中很常见,例如天气预报,空气状态监测,股票交易等金融场景。数据分析过程中重新调整,重塑数据表是很重要的技巧,此处选择Titanic数据&…
pandas和polars简单的对比分析
pandas
pandas是基于python写的,底层的数据结构是Numpy数据(ndarray)。pandas自身有两个核心的数据结构:DataFrame和Series,前者是二维的表格数据结构,后者是一维标签化数组。
polars
polars是用Rust(一种系统级编程…

pandas read_json时ValueError: Expected object or value的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…
安装pandas遇到No module named ‘_bz2’ 的解决方案
出现这个问题我们可以按照这篇博客去解决: https://blog.csdn.net/bf96163/article/details/128654915
如果解决不了,可以这样去做:
1.确保安装了 对应的库
// ubuntu安装命令 sudo apt-get install bzip2-devel // centos安装命令 sudo y…
chatgpt赋能Python-pandas预处理
介绍
Pandas是一个强大的Python库,专门用于数据操作和分析。在数据处理和分析的过程中,Pandas是一个不可或缺的工具。它提供了简单而灵活的数据结构,如Series和DataFrame,这些数据结构可以帮助我们快速预处理数据。
本文将介绍P…
Pandas实战100例 | 案例 12: 时间序列数据 - 创建、索引和重采样
案例 12: 时间序列数据 - 创建、索引和重采样
知识点讲解
Pandas 在时间序列数据处理上具有强大的功能。你可以创建时间序列数据,设置时间为索引,并进行时间序列的重采样和聚合操作。 创建时间序列数据: 使用 pd.to_datetime 可以将多列合并成一个 datetime 类型的列。设置…
数据科学家赚多少?数据全分析与可视化 ⛵
💡 作者:韩信子ShowMeAI 📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40 📘 AI 岗位&攻略系列:https://www.showmeai.tech/tutorials/47 📘 本文地址:https://www…
![[黑马程序员Pandas教程]——合并与变形](https://img-blog.csdnimg.cn/aafdffb9cc0a4d8a97058f5044074cbd.png)
[黑马程序员Pandas教程]——合并与变形
目录:
学习目标Dataframe合并 df.append函数纵向追加合并dfpd.concat函数纵向横向连接多个数据集df.merge合并指定关联列的多个数据集df.join横向合并索引值相同的多个数据集df合并小结Dataframe变形 df.T行列转置df.stack()和s.unstack()变形df.melt宽变长将列名变…

python中操作excel的常用库和方法
无论办公自动化或者数据分析中,我们常会用到excel表格。在python中都有哪些库处理数据表格?下面就说明一下在python中有哪些库能够处理数据表格。
xlwt库
pip install xlwtxlwt库仅仅能向excel中写入数据,流程如下:
创建一个wo…
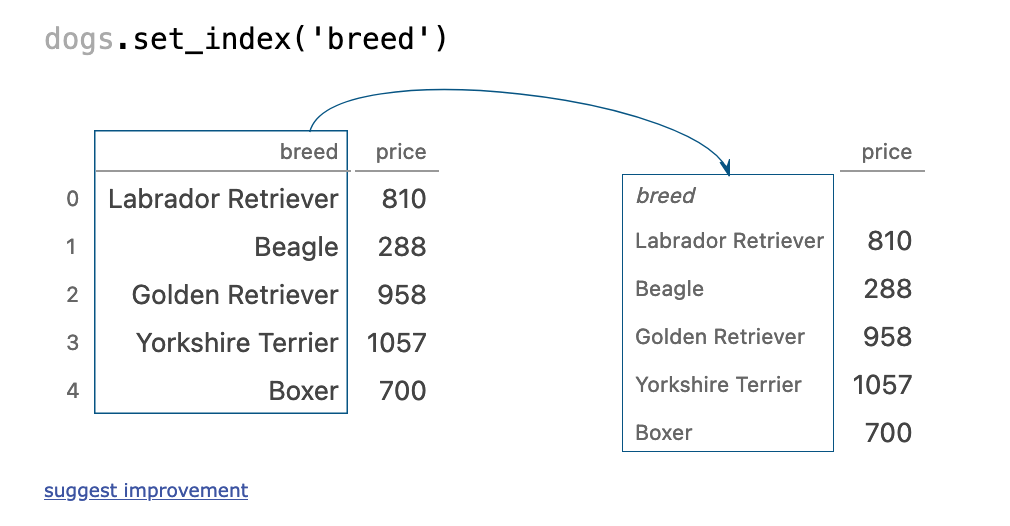
图解Pandas,这篇文章是真的强
Pandas是数据挖掘常见的工具,掌握使用过程中的函数是非常重要的。本文将借助可视化的过程,讲解Pandas的各种操作。
sort_values
(dogs[dogs[size] medium].sort_values(type).groupby(type).median()
)
执行步骤: size列筛选出部分行 然…

python数据分析与展示--Pandas库入门
一.Pandas库的引用 Pandas是python第三方库,通过了高性能易用的数据类型和分析工具;Pandas库包含了Series,DataFrame两个数据类型,基于这两个数据类型可以实现基本,运算,特征类,关联类操作 导入:…
pandas之重命名列名
假设存在如下数据集mtk: 0 1 2
0 1 3 16250
1 4 1 14501
2 3 3 27772
3 1 3 29743
4 4 3 22985mkt.rename(columns{0:first,1:second,2:third},inplace1)生成如下: first second third
0 4 1 10011
1 4 2 210…
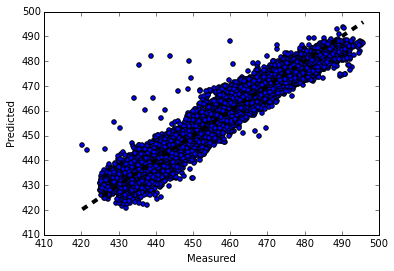
使用scikit-learn和pandas学习线性回归
对于想深入了解线性回归的童鞋,这里给出一个完整的例子,详细学完这个例子,对用scikit-learn来运行线性回归,评估模型不会有什么问题了。 1. 获取数据,定义问题 没有数据,当然没法研究机器学习啦。这里我们用…
pandas 识别并取出重复项
碰见一个七千多万行的数据,结构是这样的
idabcd233323452333345123331335123331345
第1列是标识,a,b,c,d是记录的数值,标识里面会有重复的,目的是想要找到唯一id,并且后面数值加起来最大的那一行。 开始直接做了df[i…
数据处理模块(numpy,panads)-案例
数据处理(panads与numpy)模块
#读取数据
import pandas as pd
import numpy as np
file_path open(地址)
file_date pd.read_csv(file_path)
file_date.head()##tail()#数据预处理
file_date.duplicated()#重复值检测
file_date file_date.drop_dupl…
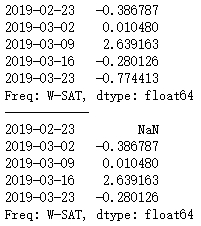
Python数据分析:pandas时间序列处理及操作
Python数据分析:pandas时间序列处理及操作 基本类型,以时间戳为索引的series–>datatimeindex 创建方法: 指定index为datatime的list from datetime import datetime
import pandas as pd
import numpy as np# 指定index为datetime的list…

实验2:Python数据预处理
实验2:Python数据预处理 文章目录实验2:Python数据预处理一、实验目的与要求二、实验任务及答案一、实验目的与要求
1、目的:
掌握数据预处理和分析的常用库Pandas的基本用法,学生能应用Pandas库实现对数据的有效查询、统计分析…
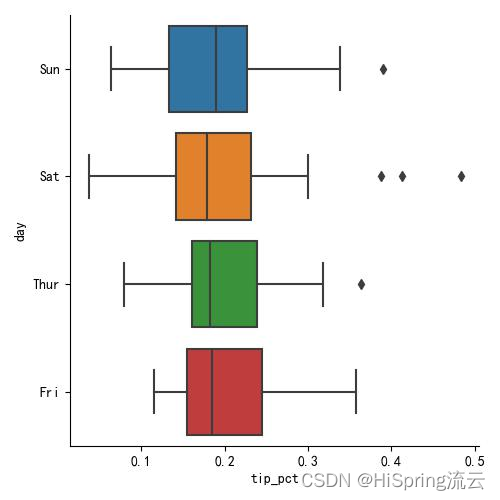
使用pandas和seaborn绘图
使用pandas和seaborn绘图 matplotlib实际上是一种比较低级的工具。要绘制一张图表,你组装一些基本组件就行:数据展示 (即图表类型:线型图、柱状图、盒形图、散布图、等值线图等)、图例、标题、刻度标签以及其他注解型信…

pandas中loc函数的返回值
图中数据框army的索引设置为origin
1.army.loc[‘Maine’]返回值 Series 类型
regiment Dragoons
company 1st
deaths 43
battles 4
size 1592
veterans 73
readiness 2
armored 0
deser…
pandas数据清洗的str属性接口的使用方法
版权声明:本文为CSDN博主「竹~松」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/weixin_52227083/article/details/120470534
import pandas as pd
df{姓名…

这十套练习,教你如何用Pandas做数据分析(02)
练习2-数据过滤与排序
探索2012欧洲杯数据 步骤1 - 导入必要的库
运行以下代码
import pandas as pd 步骤2 - 从以下地址导入数据集
运行以下代码
path2 “…/input/pandas_exercise/exercise_data/Euro2012_stats.csv” # Euro2012_stats.csv 步骤3 - 将数据集命名为eu…
pandas 读取Excel 批量转换时间戳
一、安装 pip install pandas 如果出报错,不能运行,可以安装 pip install xlrd 二、 代码如下 import pandas as pd
import time,datetimefile_path rC:\Users\Administrator\Desktop\携号转网测试\admin_log.xls
df pd.read_excel(file_path, sheet_n…
65_Pandas显示设置(小数位数、有效数字、最大行/列数等)
65_Pandas显示设置(小数位数、有效数字、最大行/列数等)
本文介绍了使用 print() 函数显示 pandas.DataFrame、pandas.Series 等时如何更改设置(小数点后位数、有效数字、最大行/列数等)。
有关如何检查、更改和重置设置值的详细…
「Python|Pandas|场景案例」如何只保留DataFrame数据集的某些列(要保留的列不固定)
本文主要介绍在使用pandas进行数据分析过程中的数据预处理时,如果希望仅保留某些列的数据需要如何操作。同时介绍一些特殊情况,比如列是用变量存储;或者列是一个全集,处理的数据集中不一定包括列出的全部列名。 文章目录 场景说明…

pandas把cvs中时间文本转换为datetime时间格式
转换前dtype
Date object
Open float64
High float64
Low float64
Close float64
Volume int64
Adj Close float64
dtype: object执行
pd.to_datetime(Date)转换后dtype
Date datetime64[ns]
Open …
Pandas Series数据结构
本篇博客将介绍Pandas中的Series数据结构,包括Series的创建、索引、切片、计算和操作等基本用法。
创建Series对象
可以使用Pandas的Series()函数创建一个Series对象。Series()函数接受一个数据序列和一个可选的索引序列作为输入。以下是创建Series对象的示例代码…
pandas中访问使用多个索引的Series
data pd.Series(np.random.randn(9),\index[[a,a,a,b,b,b,c,c,c],[1,2,3,1,2,3,1,2,3]])
dataa 1 -0.9018802 0.0832553 1.002014
b 1 2.0332842 -1.0636353 -0.415264
c 1 1.1571492 0.3607763 1.903217
dtype: float641.使用数组方式,…

numpy_图片翻转
知识点: 1. 数组的基础属性 2. 数组左右翻转和上下翻转 import numpy as np
import matplotlib.pyplot as plt
img_arr plt.imread(./111.jpeg)
img_arr.shape
# out: (505, 640, 3) # 行 列 颜色
type(img_arr)
# out: numpy.ndarray
plt.imshow(img_arr)将图片左右翻转
pl…
pandas_空值清洗
知识点:
1. None类型为NoneType, np.nan类型为float
2. 在pandas中如果遇到None形式的控制则pandas会将其转成NAN的形式
以下三种方式的目标是删除包含空值的行
目录
方式一 方式二
方式三 import pandas as pd
import numpy as np
type(None)
# out: Non…

pandas_例子2
题目(以600000为例,数据在CSDN下载资源中下载,文末会附上链接):
1. 计算股票历史数据的5日均线和30日均线
2. 分析输出所有金叉日期和死叉日期
3. 假如从2010年1月1日开始,初始资金为100000元,金叉尽量买…

数据分析 | Pandas 200道练习题 进阶篇(2)
❤️ 作者简介:大家好我是小鱼干儿♛是一个热爱编程、热爱算法的大三学生,蓝桥杯国赛二等奖获得者🐟 个人主页 :https://blog.csdn.net/qq_52007481⭐ 个人社区:【小鱼干爱编程】💯 刷题网站:数…
数据分析——快递电商
一、任务目标
1、任务
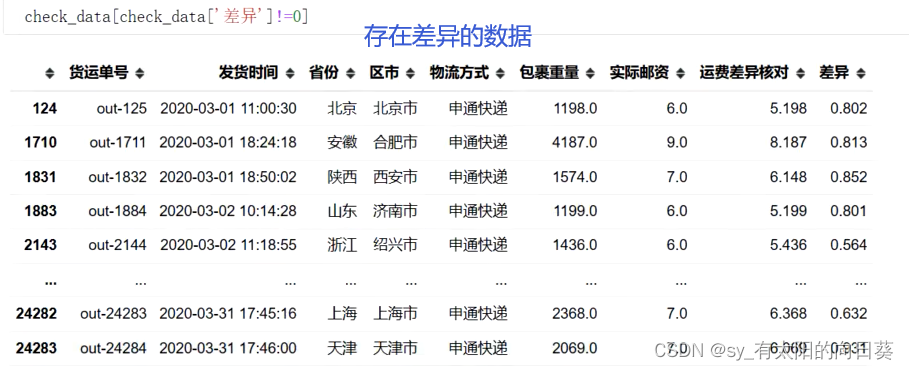
总体目的——对账
本项目解决同时使用多个快递发货,部分隔离区域出现不同程度涨价等情形下,如何快速准确核对账单的问题。
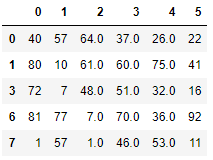
1、在订单表中新增一列【运费差异核对】来表示订单运费实际有多少差异,结果为数值。
2、将…
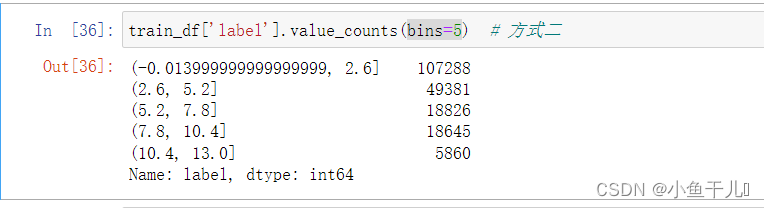
Pandas | value_counts() 的详细用法
value_counts() 函数得作用
用来统计数据表中,指定列里有多少个不同的数据值,并计算每个不同值有在该列中的个数,同时还能根据指定得参数返回排序后结果。 返回得是Series对象
value_counts(values,sortTrue, ascendingFalse, normalizeFal…
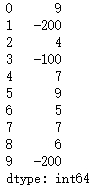
pandas数据重构与数据转换
pandas数据重构与数据转换
重构
import numpy as np
import pandas as pddf_obj pd.DataFrame(np.random.randint(0,10, (5,2)), columns[data1, data2])
df_obj运行结果: stack 将列索引旋转为行索引,完成层级索引 stacked df_obj.stack()
print(s…
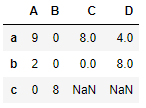
pandas数据合并
pandas数据合并
pd.concat 沿指定轴方向将多个对象合并到一起 注意指定轴的方向,默认axis0 # index 没有重复的情况
ser_obj1 pd.Series(np.random.randint(0, 10, 5), indexrange(0,5))
ser_obj2 pd.Series(np.random.randint(0, 10, 4), indexrange(5,9))
ser…

pandas计算对冲比率
前置条件:
1. 以黄金白银主力合约为例
2. 数据
AU黄金数据:
链接:https://pan.baidu.com/s/1GfSWSvygp7lrAeckXK4ypw 提取码:92l6
AG白银数据:
链接:https://pan.baidu.com/s/13RGpZmGyTQbONbOMlUnW5g 提取码&…
pandas使用cut分割区间继而用groupby对数据分组
ages np.array([1,5,10,40,36,12,2,2,67,45,90,3,6,8,23,45,12,15,17,22,4,33,28,56,58,62,77,89,100,18,20,25,30,32]) #年龄数据
quartilespd.cut(ages, [0,6,12,17,45,69,100], labels[u"婴幼儿",u"儿童",u"青少年",u"青年",u&quo…

dataframe普通切片与loc,iloc选取数据
import pandas as pd
import numpy as np
url https://raw.githubusercontent.com/HoijanLai/dataset/master/PoliceKillingsUS.csv
df pd.read_csv(url,sep,)
df.head()1.普通选择数据
要选择某一行数据,不能使用数组方式,普通切片不包括尾部 例如:d…

pandas函数isnull
一.假设有数据集df
df.isnull()返回DateFrame,元素为空或者NA就显示True,否则就是False
二.判断有空值的列
df.isnull().any()当列有为空或者NA的元素,就为True,否则False 三.显示出有空值列的列名的列表
,df.columns[iris.isnull().a…

北京法院京牌小客车司法处置数据统计(Pandas)
最近我家参加了京牌小客车的司法拍卖。即参与京牌摇号失败的人可以参加司法处置的京牌小客车的竞拍。从2011年开始实施摇号政策以来参与摇号次数越多,越有可能成功竞拍。我们参与的是 2018年7月26日拍卖的这一次。在拍卖前夕,官网放出了此次参与竞拍的所…
pandas使用记录
Series.dropna().unique()
>>> ser pd.Series([1., 2., np.nan])
>>> ser
0 1.0
1 2.0
2 NaN>>> ser.dropna()
0 1.0
1 2.0
dtype: float64serpd.Series([1,2,np.nan])
ser.dropna(inplaceTrue)##返回值是none值得注意的是datafra…
Python Pandas 使用示例
文章目录 使用Boolean 选择rows读取Excel表格里指定的sheet, 并跳过起始n行删除只有一个元素的行删除重复的合并多个csv文件到excel表格中获取csv文件的数据 使用Boolean 选择rows
import pandas as pd# Sample DataFrame
data {Name: [John, Alice, Bob, Emily],Age: [25, 3…
DataFrame object has no attribute ‘as_matrix‘
as_matrix是在老版本的pandas中,新版本已经删除了该方法,并建议使用.values方法
比如,我的代码中是这样的:
temp data.as_matrix(columnscols)
修改后:
temp data.values 下面是官网链接
https://pandas.pydat…
excel工单自动化转换工具的代码怎么写比较好?
如果你要自动化地转换 Excel 工单,可以使用 Python 编写脚本。首先,你需要安装用于读写 Excel 文件的库,例如 pandas 和 openpyxl。然后,你可以使用这些库读取 Excel 文件中的数据,进行必要的处理和转换,并…
python双色球-(一)采集双色球历史数据
多年之后,再次感受双色球的魅力,芸芸众生都为之倾倒,但是温馨提示:赌博有风险,本文仅做数据处理技术讨论,不构成任何资金投入建议!
现如今的IT行业竞争越来越激烈,一线大厂都是各种…
【Python】获得指定路径下找到所有大文件
代码如下:
import os
import math
import pandas as pddef byte_to_read(byte):num bytedic {0:B, 1:KB, 2:MB, 3:GB}# 研究了一下,在apple mac中,1KB 1000Bfor i in range(3):if num < math.pow(1000,1):return str(round(num,2)) d…
泰坦数据学习笔记-pd常用函数:读csv,read_csv()、删除列drop()、列操作loc(), iloc()...
#pandas库导入csv
#r的作用是把\变成/
data pd.read_csv(r"D:\jupterFiles\sklearnGo\data.csv")#data是从csv导入的,因此:
data #整个数据
data.info()
#下面表示891行;列
#如果有object对象,是不能直接使用的&#x…
chatgpt赋能python:使用Python操作股票软件:探索股票市场的新方式
使用Python操作股票软件:探索股票市场的新方式
在当今股票市场中,许多投资者正在寻找新的方式来更好地管理其投资组合。一种新的方式是使用Python编程语言操作股票软件。Python拥有简洁的语法和丰富的库来帮助投资者更好地理解和管理股票。在本文中&…

Numpy 对战 Pandas 之CSV文件读取效率
Numpy 对战 Pandas 之CSV文件读取效率1. Numpy.loadtxt()2. Pandas.read_csv()3. 总结4. 意外发现本文旨在分析Numpy读取CSV文件和Pandas读取CSV文件的对比。
1. Numpy.loadtxt()
官网教程-Numpy.loadtxt() 使用numpy中的loadtxt()方法可以很方便的读取文件,代码…
pandas——改写pandas源文件以实现:使用pd.DataFrame.itertuples但不自动修正列名
使用pd.DataFrame.itertuples不自动修正列名 何为pandas.DataFrame.itertuples?何为namedtuple?问题所在解决办法友情提示 何为pandas.DataFrame.itertuples?
相较于 pandas.DataFrame.iterrows而言,pandas.DataFrame.itertuples…
python二级题:计算向量积即列表元素对应相乘的四种方法
一、题目要求
参考编程模板计算两个列表 ls 和 lt 对应元素乘积的和(即向量积),完善程序。…
Python数据攻略-Pandas和NumPy的基础函数方法
当我们谈到数据分析时,我们经常会遇到各种各样的数据处理任务。这些可能包括从复杂的数据集中提取信息,转换数据格式或进行数学计算。为了更高效地完成这些任务,可以使用专门设计的函数和方法能帮助我们。
在本篇文章中将重点介绍Pandas库中的Series对象和Python中的NumPy库…

python生成excel文件的三种方式
在我们做平常工作中都会遇到操作excel,那么今天写一篇,如何通过python操作excel。当然python操作excel的库有很多,比如pandas,xlwt/xlrd,openpyxl等,每个库都有不同的区别,具体的区别࿰…
python爬虫之pandas操作csv、excel文件
在Python的数据科学和爬虫开发中,pandas是一个非常常用的库,因为它提供了各种操作数据的函数和方法。其中,pandas可以非常方便地处理CSV和Excel文件。
CSV文件操作
CSV(Comma Separated Values)是文本文件格式之一&a…

python Django web 项目 联通用户管理系统
文章目录 1框架MVC 介绍Django 框架的介绍基础命令Django处理浏览器的请求的流程 部门表部门表显示7.模板的继承部门表的添加部门表的删除request.POST.get(‘key’) 、 request.GET.get(key, )部门表的编辑filter() 得到可迭代的QuerySet对象,支持for循环取容器内的元素first(…
Pandas由入门到精通-分层索引
采集的数据存储后通常会分为多个文件或数据库,如何将这些文件按需拼接,或按键进行连接十分重要。这节将介绍数据索引的复杂操作如分层索引,stack,unstack,seet_index,reset_index等帮助重构数据,数据的拼接如merge,join,concat,combine_first等帮助连接数据,以及数据透视表…
pandas利用pd.Index和df.reindex函数提取相应列
假设存在以下数据集 realgdp realcons realinv realgovt realdpi cpi m1 tbilrate unemp pop infl realint
0 2710.349 1707.4 286.898 470.045 1886.9 28.98 139.7 2.82 5.8 177.146 0.00 0.00
1 2778.801 1733.7 310.859 481.301 1919.7 29.15 …
Python处理数据库插入和查询的一些问题及解决方案
文章目录Python连接DB2使用ibm_db和ibm_db_sa两个包使用ibm_db_sa和sqlalchemy两个包Python处理插入数据库报数据类型不一致问题Python执行SQL语句成功但是数据库没有数据Python插入大体量数据时到一定数量崩溃Python连接DB2
IBM的DB2数据库用python做连接真的不是一般的麻烦&…
pandas 新手指引
# 10 Minutes to pandas pandas入门教程,面向新手,如需高级教程,移步[pandas cookbook](http://pandas.pydata.org/pandas-docs/stable/cookbook.html#cookbook) 按照约定…

Pandas深入浅出
4.Pandas新增数据列 文章目录4.Pandas新增数据列前言一、直接赋值二、df.apply方法三、df.assign方法四、按条件选择分组分别进行赋值总结前言
不知道怎么搞的,我放在CSDN上免费下载的资源,平台竟然给附加了积分的要求。我用百度网盘分享一下࿱…
jsonpath 语法介绍
文章目录 前言 一、对jsonpath的理解 二、补充 三、哪里可以用的到呢? 总结 前言
在使用Python做接口测试中需要获取json中的字段值,因此需要使用jsonpath里面的提取规则,所以特意学习了jsonpath中的语法。 一、对jsonpath的理解 在线运…
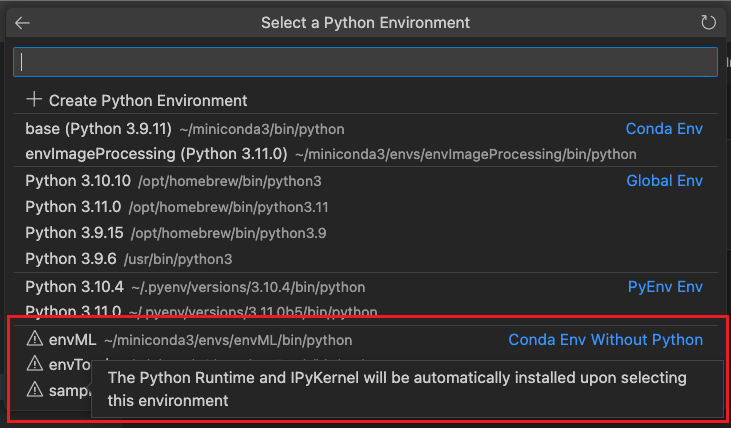
4月更新 | Visual Studio Code Python
我们很高兴地宣布2023年4月版 Visual Studio Code 的 Python 和 Jupyter 扩展现已推出!
此版本包括以下改进:
Data Wrangler 可供 Visual Studio Code Insiders 使用移动符号重构Create Environment 按钮嵌入依赖文件扩展作者的环境 APIPython 环境的内…

SqlAlchemy使用教程(六) -- ORM 表间关系的定义与CRUD操作
SqlAlchemy使用教程(一) 原理与环境搭建SqlAlchemy使用教程(二) 入门示例及编程步骤SqlAlchemy使用教程(三) CoreAPI访问与操作数据库详解SqlAlchemy使用教程(四) MetaData 与 SQL Express Language 的使用SqlAlchemy使用教程(五) ORM API 编程入门 本章内容,稍微有…
【头歌】——数据分析与实践-python-Pandas 初体验-Pandas数据取值与选择-Pandas进阶
【头歌】——数据分析与实践-python-Pandas 初体验-Pandas数据取值与选择-Pandas进阶 Pandas 初体验第1关 了解数据处理对象--Series第2关 了解数据处理对象-DataFrame第3关 读取 CSV 格式数据第4关 数据的基本操作——排序第5关 数据的基本操作——删除第6关 数据的基本操作—…
df.apply之后,dropna() got an unexpected keyword argument ‘subset‘
在使用df进行:
df.dropna(subset[keyword])
df.drop_duplicates(subset[keyword])报错:
subset not working for drop_duplicates pandas dataframe
或者 dropna() got an unexpected keyword argument subset
是因为 在此之前df经过了apply函数操作,…
Excel使用pandas拆分单元格扩展
需要:
1. anconda环境
2. excel文件,有拆分标准的单元格内容(比如我此次的:**, ***, ****,...)
以前尝试自己写公式,唉😔,不是写不出来,就是太折腾了
3. 2行code,超级…

Python3,Pandas这4种高频使用的筛选数据的方法,不得不说,确实挺好。
Pandas数据筛选方法 1、引言2、4种高频使用数据筛选方法2.1 布尔索引2.2 isin()方法2.3 query()方法2.4 loc[]方法 3、总结 1、引言
小屌丝:鱼哥,share一下 数据筛选的方法呗 小鱼:Excel就可以啊 小屌丝:我要用Pandas 小鱼&#…
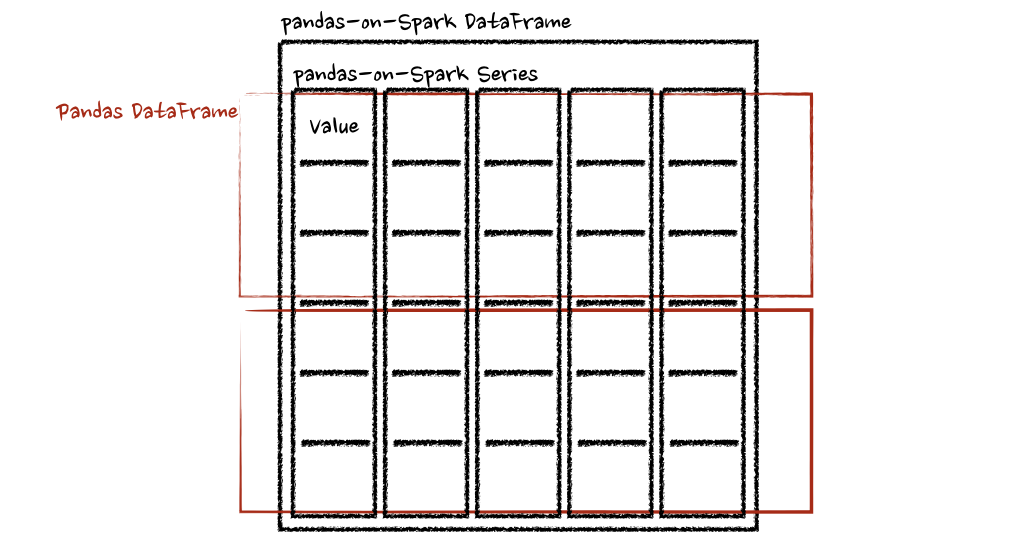
Pandas 与 PySpark 强强联手,功能与速度齐飞
Pandas做数据处理可以说是yyds!而它的缺点也是非常明显,Pandas 只能单机处理,它不能随数据量线性伸缩。例如,如果 pandas 试图读取的数据集大于一台机器的可用内存,则会因内存不足而失败。
另外 pandas 在处理大型数据…

使用pandas实现滑动窗口
滑动窗口的用处很多,比如连续3个订单中的最大值 介绍
窗口函数(Window Function)是一种在关系型数据库中使用的函数,通常用于计算某个范围内的数据。在数据分析中,窗口函数也是一种非常有用的工具,可以轻松…
已解决AttributeError: module ‘pandas‘ has no attribute ‘tslib‘异常的正确解决方法,亲测有效!!!
已解决AttributeError: module ‘pandas’ has no attribute tslib’异常的正确解决方法,亲测有效!!! 文章目录报错问题解决方法福利报错问题
粉丝群里面的一个小伙伴敲代码时发生了报错(当时他心里瞬间凉了一大截&am…

Pandas数据可视化咖啡店年、月、日、季度价格
人生苦短,我用python python 安装包资料:点击此处跳转文末名片获取 一、数据概览
咖啡是一种用烘焙过的咖啡豆、 咖啡属某些开花植物的浆果种子调制而成的饮料。
从咖啡果实中分离出种子, 生产出一种稳定的、未经烘焙的生咖啡。
然后将种子进行烘焙&a…
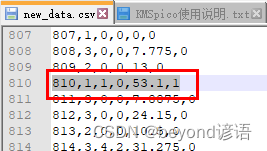
八、泰坦尼克号数据集加载训练
具体详细可参考该篇博文:七、加载数据集
①准备数据集
以泰坦尼克号数据集(titanic.csv)为例 下载完解压,将解压后得到的压缩包放到指定的路径下,我这边放到了我的jupyter里面了
里面有一些文本信息,仅使用数字信息ÿ…
Pandas数据处理分析系列6-数据特征分析
Pandas 数据特征分析 在前面章节学习了Pandas 两种数据结构Series、DataFrame,及Pandas如何读取Excel数据格式文件,数据预览、数据清洗及数据提取,接下来了解这些数据征分析。在实际工作中,财务、金融、制造业等数据,需从不同维度的指标进行分析,如合计数、最大数、最小数…

pandas中iloc和loc的用法和区别
在Pandas中,loc 和 iloc 都是用于数据选择的方法,它们是 DataFrame 和 Series 对象的索引选项。主要的区别在于它们索引数据的方式: loc loc 是基于标签的索引,意味着它使用数据的标签信息来进行数据选择。你可以使用行标签&#…
数据分析师的学习之路-pandas篇(6)
接上篇,画图告一段落,现在学习表格的各种操作。 3.8 表格操作
3.8.1 表的校验
表里有些列的数据是有一定的要求的,比如说下面这个表,Score分数列,要求成绩只能是0到100,那如果有出现错误的数据࿰…
Pandas 打开有密码的Excel
安装包 pip isntall msoffcrypto-tool msoffcrypto库的简单介绍 msoffcrypto提供了对Microsoft Office文件进行加密和解密的功能。它支持对Word、Excel和PowerPoint文件进行加密和解密操作。 msoffcrypto的原理是利用Microsoft Office文件的加密算法对文件进行加密和解密。它能…
【合并两个pandas的DataFrame】
如果你想合并两个pandas DataFrame,可以使用concat、merge或join函数。
1、 使用concat函数: 这个函数用于沿着一条轴将多个对象堆叠到一起。
import pandas as pd
# 创建两个示例的DataFrame
df1 pd.DataFrame({A: [1, 2], B: [3, 4]})
df2 pd.DataFrame({A: […
Pandas 删除数据
文章目录一、删除缺失值1.1 按照行删除数据1.1.1 删除空值对应的所有行1.1.2 删除所有列数据都为空值的行1.1.3 删除大于等于5个列中的数值为空值的行1.2 按照列删除数据1.2.1 删除所有空值对应的行,并原地替换1.2.2 删除某些列中任意列中数值为空值对应的行1.2.3 删…

数据分析 | Pandas 200道练习题,每日10道题,学完必成大神(1)
❤️ 作者简介:大家好我是小鱼干儿♛是一个热爱编程、热爱算法的大三学生,蓝桥杯国赛二等奖获得者🐟 个人主页 :https://blog.csdn.net/qq_52007481⭐ 个人社区:【小鱼干爱编程】🔥 算法专栏:算…

Python 数据挖掘 | 第3章 使用 Pandas 数据分析
Python 数据挖掘 | 第3章 使用 Pandas 数据分析前言1. Pandas 概述1.1 核心数据结构1.1.1 Series1.1.2 DataFrame1.1.3 Pannelcode1 DataFrame、Panel 和 Series 的构造与访问代码示例2. 基本数据操作2.1 索引操作2.2 赋值操作2.3 排序3. DataFrame 运算3.1 算数运算3.2 逻辑运…
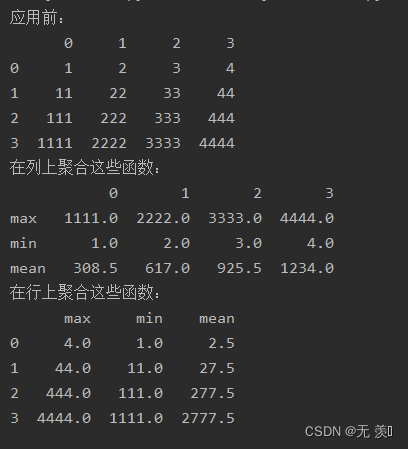
100天精通Python(数据分析篇)——第63天:Pandas使用自定义函数案例
文章目录每篇前言一、Pandas自定义函数1. pipe()2. apply()3. map()4. applymap()5. agg()二、总结每篇前言 🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6 🔥🔥本文已收…
【Python】强烈推荐的50个Pandas常用高级操作(建议收藏)
文章目录前言一、复杂查询1.逻辑运算2、逻辑筛选数据表达式与切片一致3、函数筛选4、比较函数5、查询df.query()6、筛选df.filter()7、按数据类型查询二、数据类型转换1、推断类型2、指定类型3、类型转换astype()4、转为时间类型三、数据排序1、索引排序df.sort_index()2、数值…
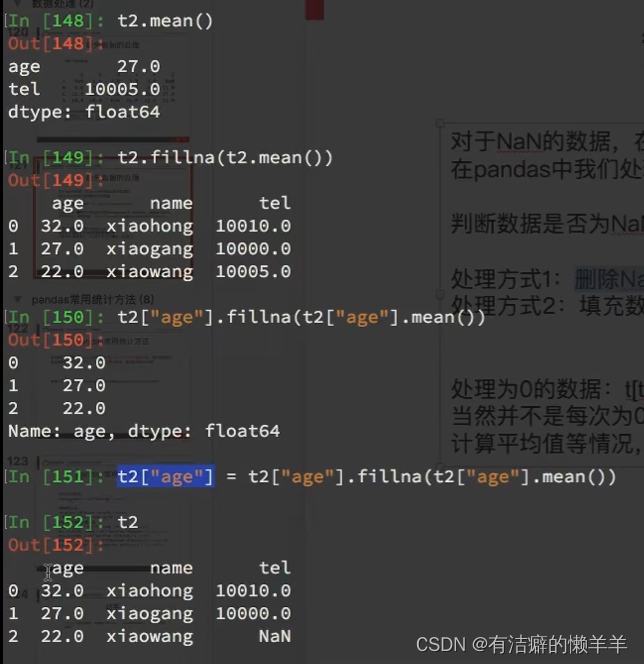
pandas基础-pandas之Series+ 读取外部数据+dataframe+dataframe的索引
目录
pandas之Series
pandas之series创建 pandas之Series切片和索引 pandas之series的索引和值编辑 pandas之读取外部数据
pandas之dataframe
pandas之dataframe的创建 传入字典创建数据
dataframe的描述信息
dataframe的索引
pandas之loc pandas之iloc pandas之布尔索…
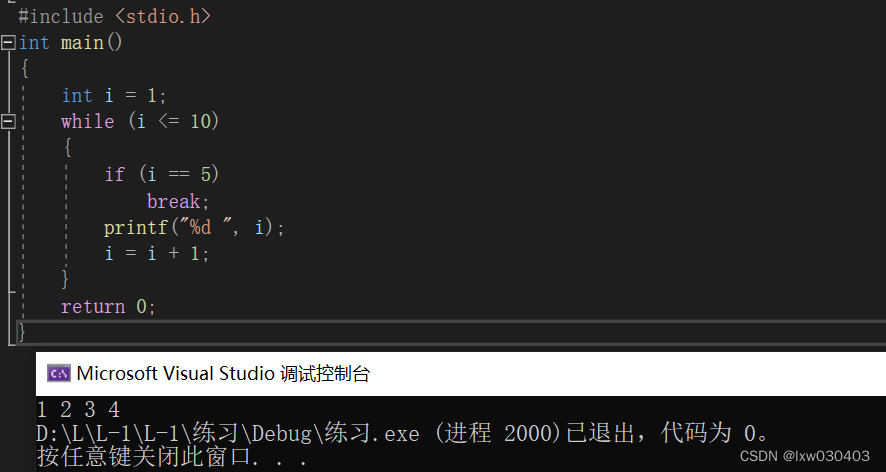
分支和循环语句——1
老铁们,这是博主初识C之后的第一篇C语言学习博客,希望可以给你们带来帮助。 文章目录 一、什么是语句?
二、分支语句
1、if语句
2、switch语句
三、while循环
一、什么是语句?
C语句可分为以下五类:
1. 表达式语句
2. 函数调用语句…
pandas的透视表pivot_table
其它参考文章:https://blog.csdn.net/mingkoukou/article/details/82870960
pandas的透视表pivot_table类似于EXCEL中的透视表
DataFrame.pivot_table(self, valuesNone, indexNone, columnsNone, aggfuncmean, fill_valueNone, marginsFalse, dropnaTrue, margin…
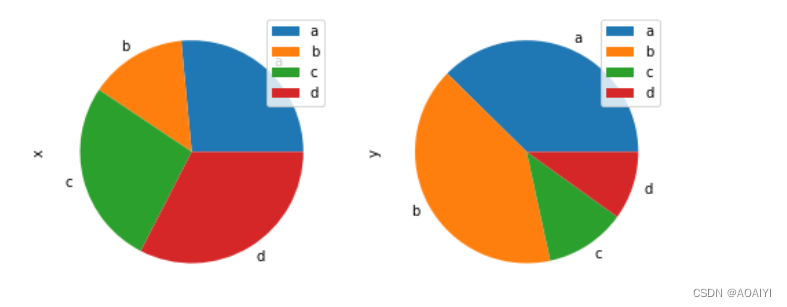
pandas——plot()方法可视化
pandas——plot()方法可视化 作者:AOAIYI 创作不易,如果觉得文章不错或能帮助到你学习,记得点赞收藏评论哦 在此,感谢你的阅读 文章目录pandas——plot()方法可视化一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤…
学以致用——植物信息录入(selenium+pandas+os+tkinter)
实现某网站植物信息录入目的整体思路核心代码实现1. 读取文件1.1遍历文件夹并yield EXCEL文件1.2.提取信息2. selenium自动化网站录入2.1 selenium配置2.2 webdriver启动2.3 身份登录2.4 核心录入代码3 tkinter调用webdriver与核心录入3.1 tkinter操作界面整体代码共勉目的
根…
Python Pandas数据重塑: `stack()`,`unstack()`和`pivot()`操作(第20讲)
Python Pandas数据重塑: stack(),unstack()和pivot()操作(第20讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔…

Python 之 Pandas DataFrame 数据类型的简介、创建的列操作
文章目录一、DataFrame 结构简介二、DataFrame 对象创建1. 使用普通列表创建2. 使用嵌套列表创建3 指定数值元素的数据类型为 float4. 字典嵌套列表创建5. 添加自定义的行标签6. 列表嵌套字典创建 DataFrame 对象7. Series 创建 DataFrame 对象三、DataFrame 列操作1. 选取数据…
比较系统的学习 pandas(5)
pandas 常见的高级操作
1、进行复杂查询
由于不好描述,就举几个栗子吧,不明白的可以私聊我
1、pnadas 支持逻辑计算与位运算
对DataFrame的一列进行逻辑计,会产生一个对应的由布尔值组成的Series,真假值由此位上的数据 是否满…
Pandas使用SQLAlchemy读写数据库及URL中特殊字符转义编码
pandas直接操作数据库
使用pandas直接对数据库进行增删改查是很方便的,这里简单的总结pandas.read_sql()和pandas.DataFrame.to_sql()使用,以及遇到的问题。
pandas.DataFrame.to_sql() 官方原文:Databases supported by SQLAlchemy [1] ar…
讲课笔记03:数据分析工具Pandas
文章目录 零、学习目标一、Pandas的数据结构分析(一)Series - 序列1、Series概念2、Series类的构造方法32、创建Series对象(1)基于列表创建Series对象(2)基于字典创建Series对象4、获取Series对象的数据5、Series对象的运算6、增删Series对象的行数据(1)增加行数据(2)…

pandas_空值填充|重复数据|异常数据
目录
空值填充 重复数据 异常数据 空值填充
import pandas as pd
import numpy as np
df pd.DataFrame(datanp.random.randint(0,100,size(8,6)))
df.iloc[0,3] np.nan
df.iloc[2,3] None
df.iloc[4,4] np.nan
df.iloc[5,2] None
df # 水平方向空值前的值用来填充
df.…

【零基础入门学习Python---Python数据处理和存储保姆级教程】
🚀 Python 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…

Python3,超大文件数据读取困难?那看完这一篇,保证完美解决你的痛点。
多种方式读取超大文件数据 1、引言2、代码实战2.1 with open2.2 mmap2.3 Dask2.4 Pandas2.5 Hadoop2.6 PySpark 3、总结 1、引言
小屌丝:鱼哥,求助,求助! 小鱼:别慌…稳住… 小屌丝:老板让我打开一个超大的…
怎么使用pandas读取较大的CSV文件
参考:python 把几个DataFrame合并成一个DataFrame——merge,append,join,conca 怎么使用pandas读取较大的CSV文件
切割CSV文件
#分割较大的CSV文件
chuck_train pd.read_csv("./train_set.csv", chunksize50000)
for i, chuck in enumerate(chuck_trai…

python进行数据分析:数据预处理
六大数据类型 见python基本功
import numpy as np
import pandas as pd数据预处理
缺失值处理
float_data pd.Series([1.2, -3.5, np.nan, 0])
float_data0 1.2
1 -3.5
2 NaN
3 0.0
dtype: float64查看缺失值
float_data.isna()0 False
1 …

解决pandas.errors.EmptyDataError: No columns to parse from file
首先确定你的程序是对的(我截取的是部分代码)
然后我的理解是它是误报错误,因为我输出我这段代码的结果看是对的,所以直接将误报给pass
这个方法我之前也用过,在我那个眼疾的报告中
改之前 改之后 改…
Python数据分析-Pandas
Pandas
个人笔迹,建议不看
import pandas as pd
import numpy as npSeries类型
spd.Series([1,3,5,np.nan,6,8],index[a,b,c,d,e])
print(s) # 默认0-n-1,否则用index数组作行标
s.index
s.value # array()
s[a] &g…

Python常用的数据文件存储格式大全(2021最新/最全版)
序言:保存数据的方式各种各样,最简单的方式是直接保存为文本文件,如TXT、JSON、CSV等,除此之外Excel也是现在比较流行的存储格式,通过这篇文章你将掌握通过一些第三方库(xlrd/xlwt/pandas/openpyxl)去操作Excel进行数据…
pandas中DataFrame使用
1、将字典中的值写入到DataFrame中,并保存到excel中
import pandas as pddata {"add": [1, 2, 3], "update": [1, 2, 3]}
data_sub pd.DataFrame(columns[interface_name, response_time], index[])
i 0
for key, value in data.items():da…
25+ Python 数据操作教程(第十一节PYTHON 中的字符串函数及示例)
常用字符串函数列表 下表显示了许多常见的字符串函数及其说明及其在 MS Excel 中的等效函数。我们在工作场所都使用MS Excel,并且熟悉MS Excel中使用的功能。MS EXCEL和Python中字符串函数的比较可以帮助你快速学习函数并在面试前做好准备。 功能描述MS Excel 函数字符串[:N]从…
【python】python将json字符串导出excel | pandas处理json字符串保存为csv
如何将json转为csv
1、通过json直接转为csv 在Python中,你可以使用pandas库来处理DataFrame(数据帧)和将JSON数据转换为CSV格式。下面是一个简单的示例代码,展示了如何使用pandas库将JSON数据转换为CSV文件: import p…
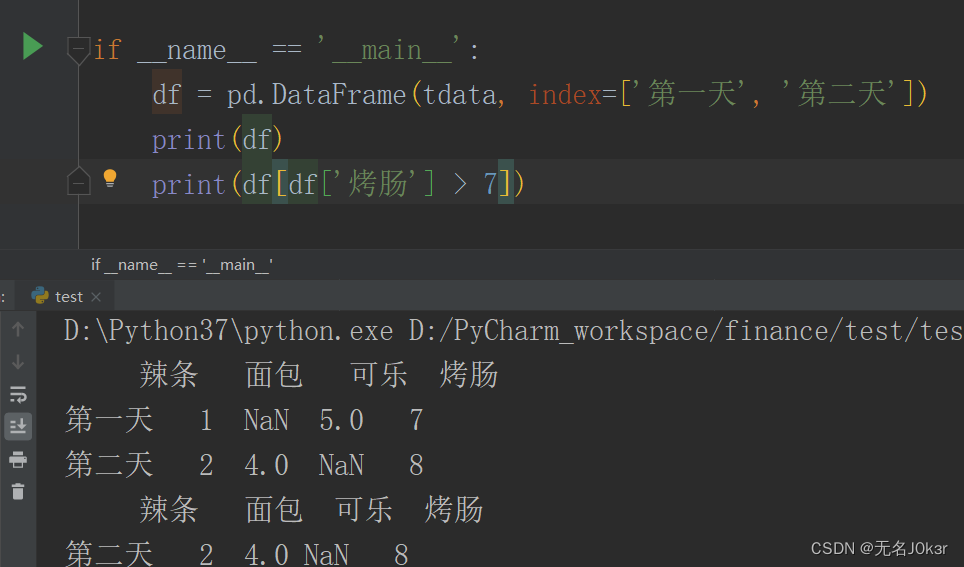
量化:pandas基础
文章目录 简介Series构造 DataFrame构造列的查改增删填充默认值用loc与iloc取数据条件选择 简介
pandas是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构。 pandas主要的两种数据结构为Series和DataFrame,分别用于处理一维和二维数据。…
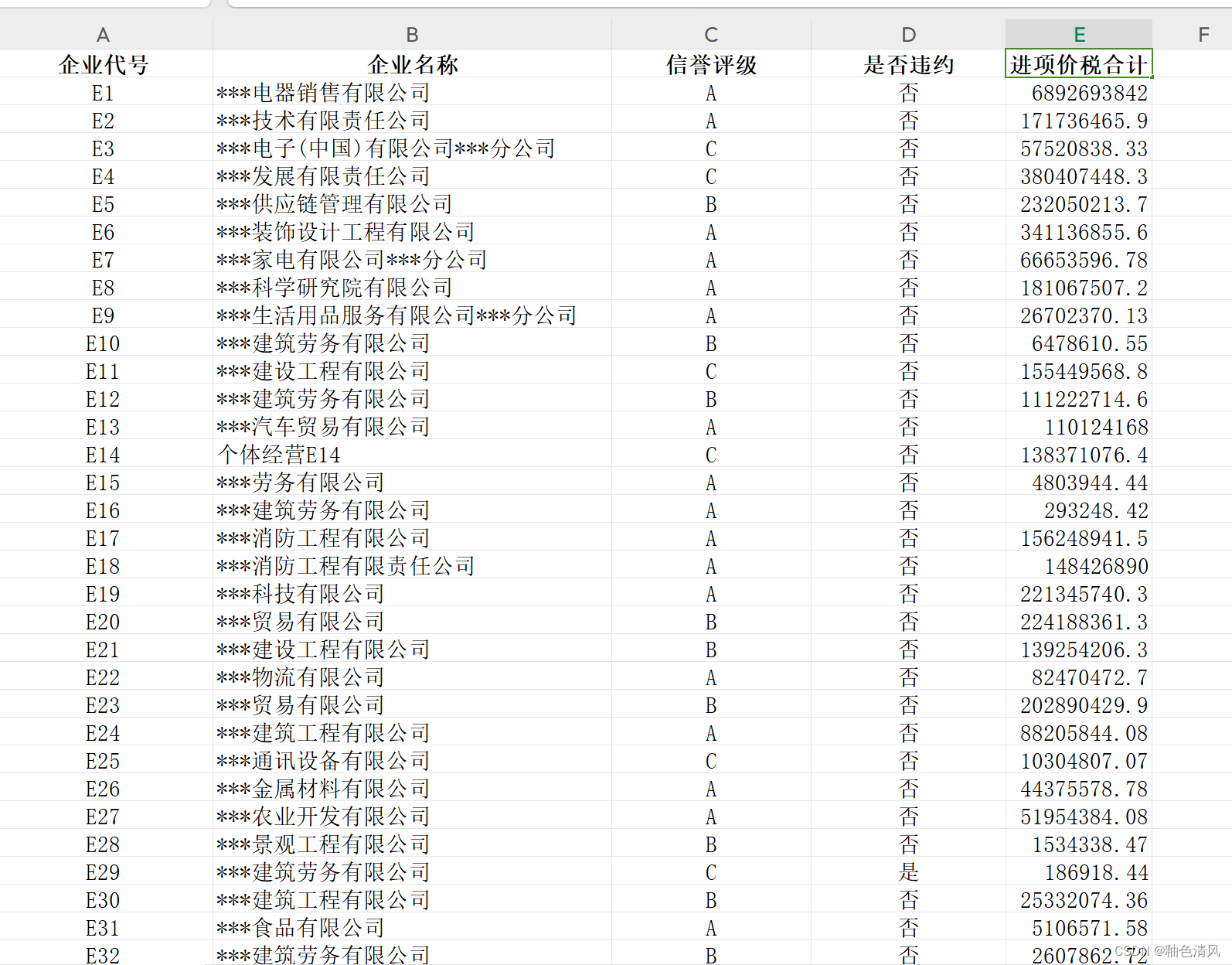
【机器学习5】数据处理(二)Pandas:表格处理
Pandas:表格处理 🌟🌟Pandas三种数据类型✨✨Series数据结构✨✨ DataFrame数据结构🌙🌙DataFrame数据的选取🌕🌕DataFrame的构建🌕🌕选取多行🌕🌕选取某一列…
【科研论文配图绘制】task1 掌握科研绘图的基本知识
【科研论文配图绘制】task1 掌握科研绘图的基本知识 写在最前 8月份Datawhale组队学习,写下该博客记录学习内容
1.科研论文配图的分类与构成
2.科研论文配图的格式和尺寸
3.科研论文配图中的字体和字号设置
4.科研论文配图的版式设计、结构布局和颜色搭配
占个…
Python数据攻略-Pandas与金融数据分析
当我们谈到金融市场,可能会想到股票、债券、货币和衍生品等各种复杂的金融产品。对这些产品进行数据分析,不仅可以更好地理解市场动态,还可以为投资决策提供有力支持。
在这篇文章里将使用Pandas库来进行金融数据分析,特别是时间序列数据的处理、金融指标的计算以及风险和…

pandas连接查询
df1数据如下 df2数据如下 连接查询代码 -1
import pandas as pddf1 pd.DataFrame({id:[1001,1002,1003,1004],name:[Hu,Dotu,Evp,Swe]})
df2 pd.DataFrame({id:[1001,1001,1003,1004, 1003],course:[c1,c2,c3,c2,c1],score:[100, 98, 64, 84, 69]})result pd.merge(df1, df…
Python数据攻略-Pandas进行CSV和Excel文件读写
在数据分析的世界里,能够读取和写入不同格式的文件是一项基本而重要的技能。CSV(逗号分隔值)和Excel是两种常见的数据存储格式。它们在商业、科研、教育等多个领域都有广泛应用。 文章目录 读取CSV文件`pd.read_csv()` 文件读取函数的基本用法`DataFrame.to_csv()` 数据写入…
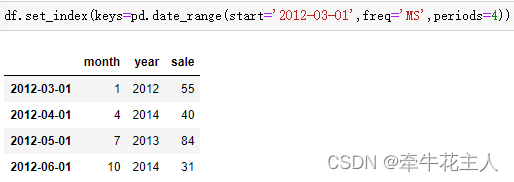
DataFrame.set_index()方法--Pandas
1.函数功能
为DataFrame重新设置索引(行标签)
2. 函数语法
DataFrame.set_index(keys, *, dropTrue, appendFalse, inplaceFalse, verify_integrityFalse)3. 函数参数
参数含义keys作为行标签的列名,可以DataFrame中的是单个列或者多列组…
机器学习-Pandas学习笔记
Pandas Python的数据分析库,与Numpy配合使用,可以从常见的格式如CSV、JSON等中读取数据。可以进行数据清洗、数据加工工作。数据结构Series,Pandas.Series(data,index,dtype,name,copy) data类型是Numpy的ndarray类型,index指定下…
docker--在Anaconda jupyter 容器中使用oracle数据源时,Oracle客户端安装配置及使用示例
配置oracle 11.2 客户端
将instantclient-basic-linux.x64-11.2.0.4.0.zip解压至/home/jupyter/oracle/将instantclient-sqlplus-linux.x64-11.2.0.4.0.zip解压/home/jupyter/oracle/【可选,提供sqlplus命令】复制【操作系统一般都有安装libaio.so】 cp /usr/lib64…

Python+Qt生日提醒
PythonQt生日提醒如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!前言这篇博客针对<<PythonQt生日提醒>>编写代码,代码整洁,规则,易读。 学习与应用推荐首选。文章目…
Pandas Series详解
文章目录一、创建Series1.1 创建空Series1.2 从ndarray创建Series1.3 从字典创建Series1.4 从标量创建Series二、访问Series2.1 通过位置访问Series数据2.2 通过索引访问Series数据三、Series常用属性四、Series常用方法4.1 查看数据4.2 检测缺失值Pandas 序列(Series)是pandas…
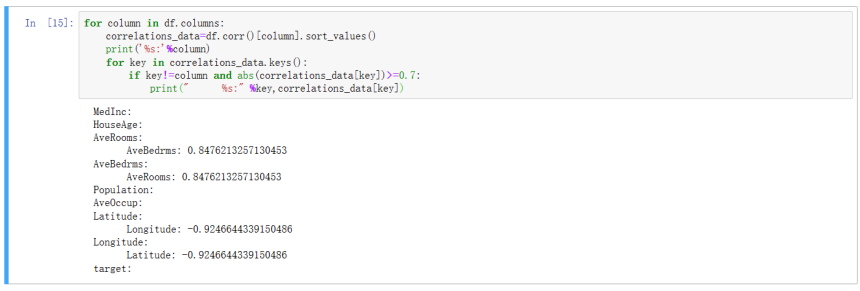
【数据预处理】基于Pandas的数据预处理技术【california_housing加州房价数据集】_后9个任务
文章目录一.需求分析二.需求解决2.1 对第一个特征(收入中位数)排序后画散点图2.2 对第一个特征(收入中位数)画分位数图并分析2.3 【选做】对所有特征画分位数图并进行分析2.4 使用线性回归方法拟合第一个特征(收入中位…
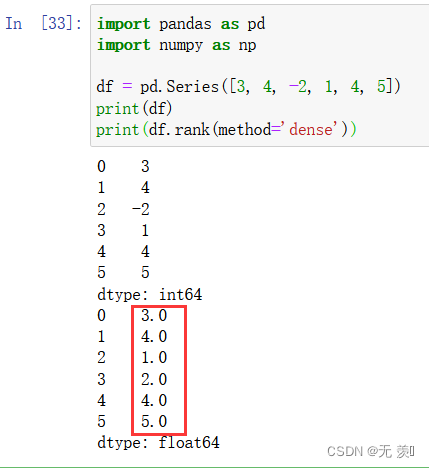
100天精通Python(数据分析篇)——第70天:Pandas常用排序、排名方法(sort_index、sort_values、rank)
文章目录每篇前言一、按索引排序:sort_index()1. Series类型排序1)升序2)降序2. DataFrame类型排序1)按行索引排序2)按列索引排序二、按值排序:sort_values()1. Series类型排序1)升序2ÿ…

仅三行就能学会数据分析——Sweetviz详解
文章目录前言一、准备二、sweetviz 基本用法1.引入库2.读入数据3.调整报告布局总结前言
Sweetviz是一个开源Python库,它只需三行代码就可以生成漂亮的高精度可视化效果来启动EDA(探索性数据分析)。输出一个HTML。
如上图所示,它不仅能根据性别、年龄等…
分支和循环语句——2
老铁们,这是博主对前一篇文章的补充,希望对你们有所帮助。 文章目录 一、for循 二、do while循环 一、for循环
for(表达式1; 表达式2; 表达式3)//语法 循环语句;
表达式1
表达式1为初始化部分,用于初始化循环变量的。
表达式2
表达式2为…
Nuitka 打包 Pandas、Numpy
其他 Nuitka 打包技巧见《Python程序打包指南》 本文主要讲解如何使用 Nuitka 打包 Pandas 包,主要分为两部分:1. 打包的两种方式对比,解决打包时间长的问题;2.对不推荐的打包方式的说明。 一、打包前准备 Pandas :1.5.3numpy:1.22.3Nuitka:1.4.8Windows 11 专业版 22H2…
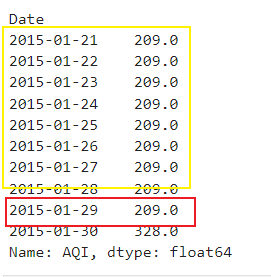
python数据处理----处理缺失值(二)
删除缺失值
删除缺失值会损失信息,并不推荐删除,当缺失数据占比较低的时候,可以尝试使用删除缺失值
按行删除
age为NaN的所有行都删了
train1.dropna(subset[Age],howany,inplaceTrue)按列删除
train1.drop([Age],axis1)填充缺失值
常量…

python数据处理----处理缺失值(一)
何为缺失值?
缺失值介绍 很多的数据集中因为数据量过大,并不是每一条数据都有完整的字段,缺失值字面意思就是某一条数据中有为空的字段,为空的字段就为缺失值。 在pandas中缺失值用NaN表示 pandas中的NaN来自于Numpy库…

python数据处理----pandas计算常用统计值和排序
计算常用统计值
describe( )方法:
college.describe()# count: 样本数据的大小
# mean: 数据的平均值
# std: 数据的标准差
# min: 数据的最小值
# 25%: 1/4位数,数据在25%时的值
# 50%: 中位数
# 75%: 3/4位数
# max: 数据的最大值定义describe的incl…
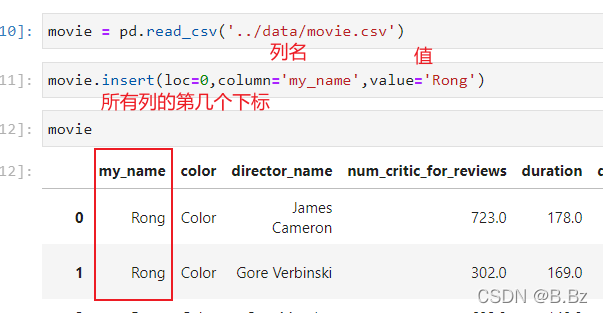
python数据处理----修改索引和行列
修改索引
修改索引之前是自动生成的索引: 使用set_index(以xx字段为索引,inplaceTrue)设置索引:
inplace为True不用给新变量赋值,使用旧的变量名发现索引就已经被改变
打开文件时就生成索引:
index_col以xx字段为索引
重置…
raspberry install pandas with python 3.6
berryconda
berryconda 是一款为树莓派定制基于 conda python 发行版的开源软件。我们可以使用它来实现类似 Miniconda 和 Anaconda 的功能。 berryconda 提供了 python2.7 的 Berryconda2 和 python 3.6 的 Berryconda3,同时还支持 树莓派 0 1 2 3各个系列&#x…
Pandas合并DataFrame数据写入Excels
concat对比merge
1.要想实现sql中的join,需要使用merge方法,能指定列key。 2.pandas中的join方法,相比merge,只是个弟弟,使用场景有限,相当于concat中的方向为1的合并。 3.concat实现的只是将两个或多个df…
![@[PANDAS]1.Pandas库的Series类型](https://img-blog.csdnimg.cn/20191002120921237.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDM4NzUxNQ==,size_16,color_FFFFFF,t_70)
@[PANDAS]1.Pandas库的Series类型
一.参考资料:
中国大学慕课网站: Python数据分析与展示 北京理工大学 嵩天 https://www.icourse163.org/search.htm?searchpandas#/获得pandas文档、代码的网站: http://pandas.pydata.org
二.介绍 提供: 1.提供便于操纵数据的…
Python数据分析之Pandas核心使用进阶
文章目录 DateFrame 行级遍历的两种方法操作Pandas的index三种方法重新设置行index将某列设置为index将index 设置为列 如何理解Pandas的列自动对齐空值检查和填充对数据集DataFrame去重对DataFrame分组使用join连接两个DataFrame和四种join方法使用pivot_table 透视DateFrameP…

date_range()函数--Pandas
1. 函数功能
生成连续的日期时间序列
2. 函数语法
pandas.date_range(startNone, endNone, periodsNone, freqNone, tzNone, normalizeFalse, nameNone, inclusiveboth, *, unitNone, **kwargs)3. 函数参数
参数含义start可选参数,起始日期end可选参数ÿ…
用pandas处理数据时,使变量能够在不同的Notebook会话页面进行传递,魔法命令%store
【需求来源】
在使用pandas时,有的时候我想将.ipynb文件分开写
其中一个写清洗数据代码另外一个写数据可视化代码
【解决方案】
但是会涉及到变量转移问题,这个时候我通常使用的方法是: 1、在清洗完数据后导出到本地 2、在文件后面增加当…
[python]问题:pandas处理excel,选中特定的sheet
要使用pandas处理Excel文件并选中特定的sheet,首先需要安装pandas和openpyxl库。可以使用以下命令进行安装:
pip install pandas openpyxl然后,可以使用以下代码读取Excel文件中的特定sheet:
import pandas as pd# 读取Excel文件
file_path = your_excel_file.xlsx
sheet…
Pandas常用操作整理
序号操作名称操作用途案例官方文档链接1pandas.merge进行表连接pd.merge(table1, table2, on"id", how"left")前往2pandas.DataFrame.drop_duplicates删除重复行df.drop_duplicates([brand, style], keeplast)前往3pandas.DataFrame.sort_values根据值进行…
学习 使用pandas库 DataFrame 使用
1 、 数据排序 sort_values()函数 by:要排序的名称或名称列表, sorted_df df.sort_values(byAge,ascendingFalse) 由大到小排序; sorted_df df.sort_values(byAge) 由小到大排序;
# 创建一个示例数据帧
data {Name: [Tom, Nick, John…
基础Python教程之pandas使用总结
Pandas 简介
Pandas 库是机器学习四个基础库之一, 它有着强大的数据分析能力和处理工具。它支持数据增、删、改、查;支持时间序列分析功能;支持灵活处理缺失数据;具有丰富的数据处理函数;具有快速、灵活、富有表现力的…
Pandas 数据处理分析系列1--SeriesDataFrame数据结构详解
Pandas 概述 Pandas 是一个开源的数据分析和数据处理库,是基于 NumPy 开发的。它提供了灵活且高效的数据结构,使得处理和分析结构化、缺失和时间序列数据变得更加容易。其在数据分析和数据处理领域广泛应用,在金融、社交媒体、科学研究等领域都有很高的使用率和广泛的应用场…

python数据处理----数据对象的布尔索引和运算
数据对象的布尔索引
DataFrame数据对象: 打印ages > ages.mean()可以看出是一列布尔值,通过布尔值来控制是否显示数据: 所以得出我们可以自定义一串布尔值来决定显示的数据: 同理Series数据对象: 数据对象的运算…
在Oracle中,TO_CHAR()、TO_NUMBER()和TO_DATE()函数的使用方法以及作用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、to_char 函数二、to_number函数二、to_date 函数总结前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能…

ImportError: No module named 'xlrd'
在用pandas处理Excel文件的时候,
import pandas as pd
df pd.read_excel(excelname.xlsx) # 读取数据
如上所示读入数据后可能会出现这样的错误提示:
ImportError: No module named xlrd
其原因是,我们需要单独安装一个xlrd模块才能支持…
pandas@get_dummies@ 虚拟变量@one-hot encoding
文章目录虚拟变量one-hot encodingdemodemo1demo2demo3数值化插值处理NaN数值化其他get_dummies例虚拟变量one-hot encoding pandas.get_dummies — pandas 1.5.3 documentation (pydata.org) 将分类变量转换为虚拟/指示变量。 在数据分析领域,dummies通常被翻译为…
Python数据分析:Pandas入门教程
Python数据分析:Pandas入门教程 一、Python数据分析简介1. 数据分析的定义与背景2. Python在数据分析中的优势 二、Pandas简介1 Pandas库的作用和优势2 Pandas的数据结构Series和DataFrame3 Pandas库的安装和使用 三、数据读取与导出1 读取本地CSV文件2 读取Excel文…

Python 03 变量
目录
一、运算符
1.1 算术运算符
1.2 逻辑运算符
1.3 位运算符
常用函数汇总
二、变量
三、数据类型转换 一、运算符
1.1 算术运算符 在Python中*运算符还可以用于字符串,计算结果就是字符串重复指定次数的结果
"" * 5 # 输出 1.2 逻辑运算符 …
Python数据分析教程08:pandas进行外卖订单数据分析
目录
功能点1:将订单以天为单位输出为单个文件
功能点2:提取数据表某列中,不是某个给定值的数据
功能点3:统计一个订单从下单到完成配送时刻之间的时间差
功能点4:绘制订单的持续时间曲线
功能点5:提取…
Python数据分析——pandas
1.pandas简介 pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持…
Python 机器学习最常打交道的 27 款工具包
为了大家能够对人工智能常用的 Python 库有一个初步的了解,以选择能够满足自己需求的库进行学习,对目前较为常见的人工智能库进行简要全面的介绍。 1、Numpy
NumPy(Numerical Python)是 Python的一个扩展程序库,支持大量的维度数组与矩阵运算…
pandas——groupby操作
Pandas——groupby操作 文章目录Pandas——groupby操作一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤一、实验目的
熟练掌握pandas中的groupby操作
二、实验原理 groupby(byNone, axis0, levelNone, as_indexTrue, sortTrue, group_keysTrue, squeezeFalse&…

Pandas数据操作详解-总结
pandas简介pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。pandas 是 Python 的核心数…

【100天精通Python】Day59:Python 数据分析_Pandas高级功能-多层索引创建访问切片和重塑操作,pandas自定义函数和映射功能
目录
1 多层索引(MultiIndex)
1.1 创建多层索引
1.1.1 从元组创建多层索引
1.1.2 使用 set_index() 方法创建多层索引
1.2 访问多层索引数据
1.3 多层索引的层次切片
1.4 多层索引的重塑
2 自定义函数和映射
2.1 使用 apply() 方法进行自定义函…
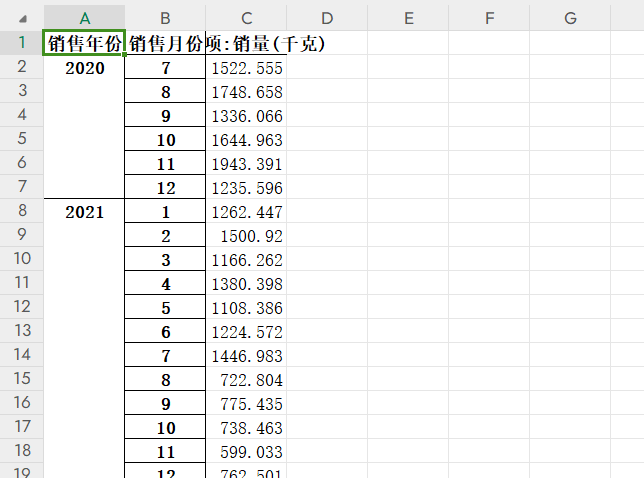
借助ChatGPT使用Pandas实现Excel数据汇总
一、问题的提出
现在有如下一个Excel表: 上述Excel表中8万多条数据,记录的都是三年以来花菜类的销量,现在要求按月汇总实现统计每个月花菜类的销量总和,如果使用Python的话要给出代码。
二、问题的解决
1.首先可以用透视表的方…
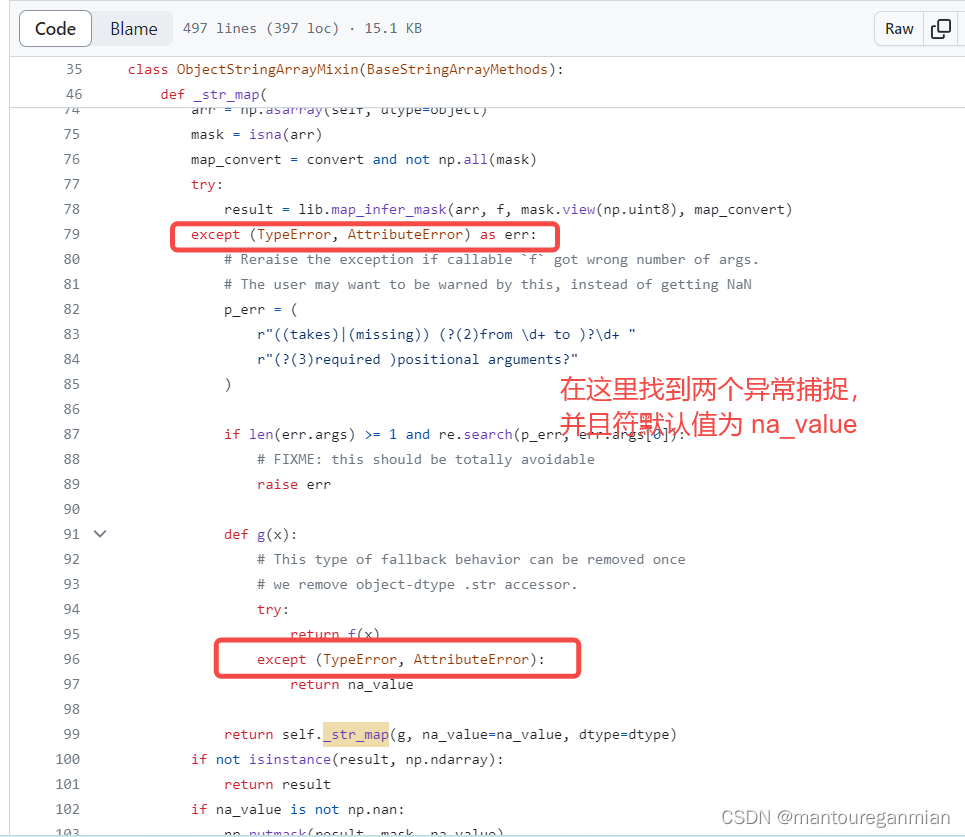
Pandas小白入门散记(3)---Series.str--源代码定位问题
文章目录 问题点原因解释 碰到了,一个错误,debug才定位到问题,记录一下。
本次最大收获是,pandas果然代码逻辑复杂,一个小小的异常捕捉,处处是门道。。。。。。
希望本次浅显的代码阅读过程,给…

pandas 筛选数据的 8 个骚操作
日常用Python做数据分析最常用到的就是查询筛选了,按各种条件、各种维度以及组合挑出我们想要的数据,以方便我们分析挖掘。
东哥总结了日常查询和筛选常用的种骚操作,供各位学习参考。本文采用sklearn的boston数据举例介绍。
from sklearn …
[python]问题:pandas处理excel里的多个sheet
Pandas 可以很容易地处理 Excel 文件中的多个工作表。首先,你需要安装 pandas 和 openpyxl(用于读取 .xlsx 文件)库。你可以使用以下命令安装这两个库:
pip install pandas openpyxl接下来,你可以使用以下代码来处理 Excel 文件中的多个工作表:
import pandas as pd# 读…
提取多个txt数据并合成excel——例子:与中国建交的国家
提取多个txt数据并合成excel——例子:与中国建交的国家 一、概要二、整体架构流程三、完整代码 一、概要 这段代码主要执行以下任务: 1. 定义辅助函数:首先,定义了两个辅助函数。has_chinese_chars函数用于检查给定的字符串中是否…
Python 数组操作指南:使用示例和方法解析
什么是 Python 数组?
数组是一种基本数据结构,也是大多数编程语言的重要组成部分。在 Python 中,它们是能够同时存储多个项目的容器。具体来说,它们是元素的有序集合,每个值都具有相同的数据类型。这是关于 Python 数组需要记住的最重要的事情 - 它们只能保存相同类型的多…
pandas数据分析40——读取 excel 合并单元格的表头
案例背景
真的很容易疯....上班的单位的表格都是不同的人做的,所以就会出现各种合并单元格的情况,要知道我们用pandas读取数据最怕合并单元格了,因为没规律...可能前几列没合并,后面几列又合并了....而且pandas对于索引很严格&am…
使用Pandas处理Excel文件
Excel工作表是非常本能和用户友好的,这使得它们非常适合操作大型数据集,即使是技术人员也不例外。如果您正在寻找学习使用Python在Excel文件中操作和自动化内容的地方,请不要再找了。你来对地方了。 在本文中,您将学习如何使用Pan…

开放式耳机百元价位怎么选、公认最好的百元开放式耳机
开放式耳机采用挂耳式的佩戴方式,不需封闭耳道,这一创新设计允许我们欣赏音乐的同时保持对周围环境的感知,从而在户外运动、通勤或其他活动中提供更安全的体验。而且,在预算有限的情况下,我们可以在百元价位范围内找到…
股票量化择时策略(1)
量化择时策略要解决什么?(与量化投资有关系,因为量化择时本身就选出买卖的时机,所以实际上是一回事) 主观决策:传统的投资方法通常涉及主观判断和情感因素,投资者可能会因情绪波动而做出不明智的决策。量化择时策略旨在通过数据和规则来减少主观性,提高投资决策的客观性…
Node.js在Python中的应用实例解析
随着互联网的发展,数据爬取成为了获取信息的重要手段。本文将以豆瓣网为案例,通过技术问答的方式,介绍如何使用Node.js在Python中实现数据爬取,并提供详细的实现代码过程。 Node.js是一个基于Chrome V8引擎的JavaScript运行时环境…
Python 字典(Dictionary) get() 函数返回指定键的值
Python 字典(Dictionary) get() 函数返回指定键的值。
语法 get()方法语法:
dict.get(key[, value]) 参数 key – 字典中要查找的键。 value – 可选,如果指定键的值不存在时,返回该默认值。 返回值 返回指定键的值,如果键不在字…
python数据分析中常用的库
Python是数据处理常用工具,可以处理数量级从几K至几T不等的数据,具有较高的开发效率和可维护性,还具有较强的通用性和跨平台性。Python可用于数据分析,但其单纯依赖Python本身自带的库进行数据分析还是具有一定的局限性的…
【致敬未来的攻城狮计划】— 连续打卡第二十天:RA2E1_UART —— 串口通信例程
系列文章目录 1.连续打卡第一天:提前对CPK_RA2E1是瑞萨RA系列开发板的初体验,了解一下 2.开发环境的选择和调试(从零开始,加油) 3.欲速则不达,今天是对RA2E1 基础知识的补充学习。 4.e2 studio 使用教程 5.…
【办公类-19-01-03】办公中的思考——Python,统计孩子名字的同音字(拼音)
一、现象:现在我是中班的班主任了,本周都在强化记忆孩子们的名字。1、前期已经知道班级里的同姓最多:因此,我有意识地在背诵姓氏时,考虑思考另几位同姓的人是谁?情景1:找找同姓氏的人师…
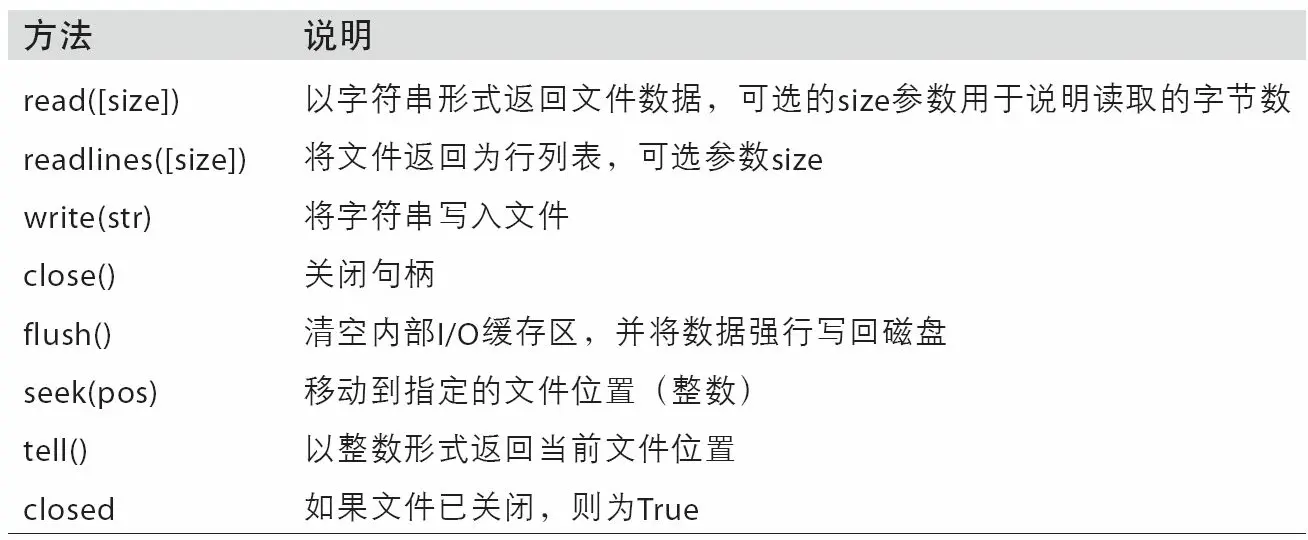
Python文件和操作系统基础
文章和代码等已经归档至【Github仓库:https://github.com/timerring/dive-into-AI 】或者【AIShareLab】回复 python数据分析 也可获取。 文章目录 文件和操作系统文件的字节和Unicode 文件和操作系统
代码示例大多使用诸如 pandas.read_csv 之类的高级工具将磁盘上…

Python读写EXCEL文件常用方法大全
python读写excel的方式有很多,不同的模块在读写的讲法上稍有区别,这里我主要介绍几个常用的方式。
用xlrd和xlwt进行excel读写;用openpyxl进行excel读写;用pandas进行excel读写;
一、数据准备
为了方便演示ÿ…
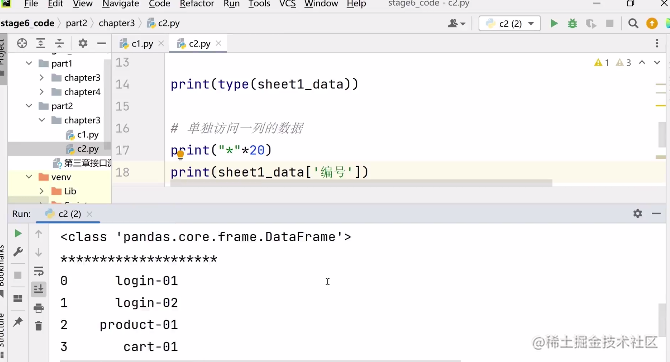
接口测试——Excel接口测试用例访问(六)
pandas访问链接
https://www.runoob.com/pandas/pandas-install.html
1. pandas库的安装及库安装方法总结
方法一:cmd命令行执行pip install pandas 1.WindowsR,输入cmd打开命令行窗口,输入pip install pandas。 下图所示 2.若出现下图所示…

apply函数 | pandas
1、概念
apply()可以应用于Pandas中的Series和DataFrame对象。在Series对象上,apply()将会对Series中的每个元素应用指定的函数并返回一个新的Series对象;在DataFrame对象上,apply()将会对每一行或者每一列应用指定的函数并返回一个新的Data…
科学计算库-Pandas随笔【及网络隐私的方法与策略闲谈】
文章目录 8.2、pandas8.2.1、为什么用 pandas ?8.2.2、pandas Series 类型8.2.3、pandas 自定义索引8.2.4、pandas 如何判断数据缺失?8.2.5、pandas DataFrame 类型8.2.6、pandas 筛选8.2.7、pandas 重新索引8.2.8、pandas 算数运算和数据对齐8.2.9、pan…

史上对pandas的rank()最直白最清晰的理解
官网的文档解释如下: 官方解释:rank通过将平均排名分配到每个组来打破平级关系。 我感觉比较晦涩难懂,感觉说的不是人话,为此我对此深究,结果如下:
例子:
代码:
obj pd.Series([…
58_Pandas中mode获取pandas的每一行和列
58_Pandas中mode获取pandas的每一行和列
使用pandas.Series和pandas.DataFrame的mode()方法,可以得到每一列每一行的mode。
在此,对以下内容进行说明。
pandas.Series 中的mode()pandas.DataFrame 中的mode(&#x…
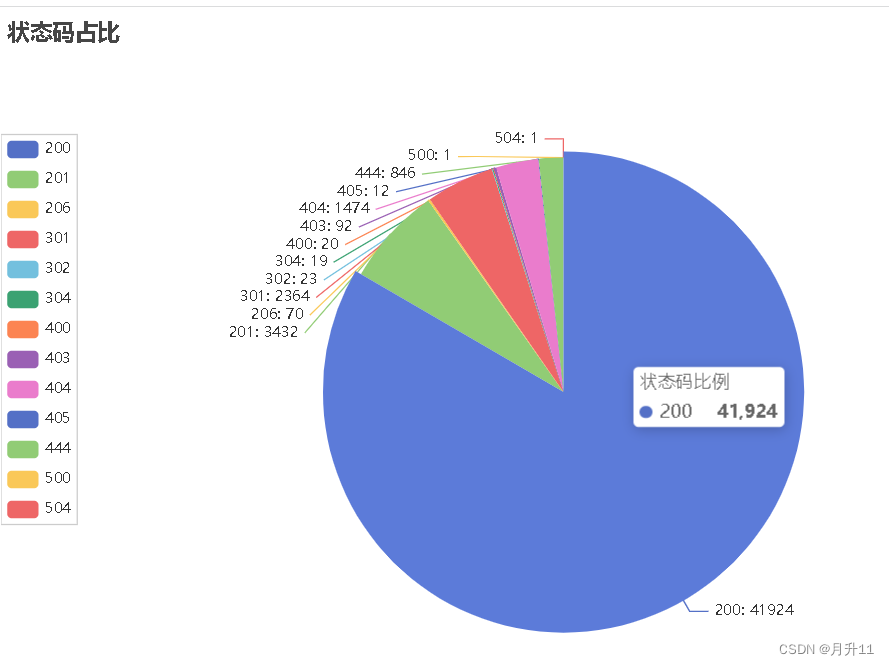
26. Pandas处理分析网站原始访问日志
Pandas处理分析网站原始访问日志
目标:真实项目的实战,探索Pandas的数据处理与分析
实例: 数据来源:我自己的wordpress博客蚂蚁学Python – 你有没有为写代码拼过命?那你知不知道 人生苦短,我用Python&am…
![python代码的基本操作[文件写入][文件读取]](https://img-blog.csdnimg.cn/35b40b748af14afe9ac774029a274d08.jpg)
Pandas数据分析教程-pandas的数据结构
pandas数据分析-pandas的数据结构 pandas 数据结构Series1. 创建Series数组2. 性质3. 索引4. 运算DataFrame1. 创建Df数组2. 性质3.索引4. 对列进行增删改Index Objects本文介绍pandas中一些常用的属性方法的概述,给读者提供快速学习的架构和思路。表格中提供的一些参数方法没…
Python数据攻略-Pandas与地理空间数据分析
地理空间数据分析已经成为数据分析不可或缺的一部分。无论是在城市规划、交通分析,还是在环境科学中,地理空间数据都发挥着关键作用。
本文将为初学者和新手提供一个详细的指南,通过使用Python的Pandas库和Geopandas库,来进行地理空间数据分析。 文章目录 用Pandas处理地理…
Spark上使用pandas API快速入门
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…
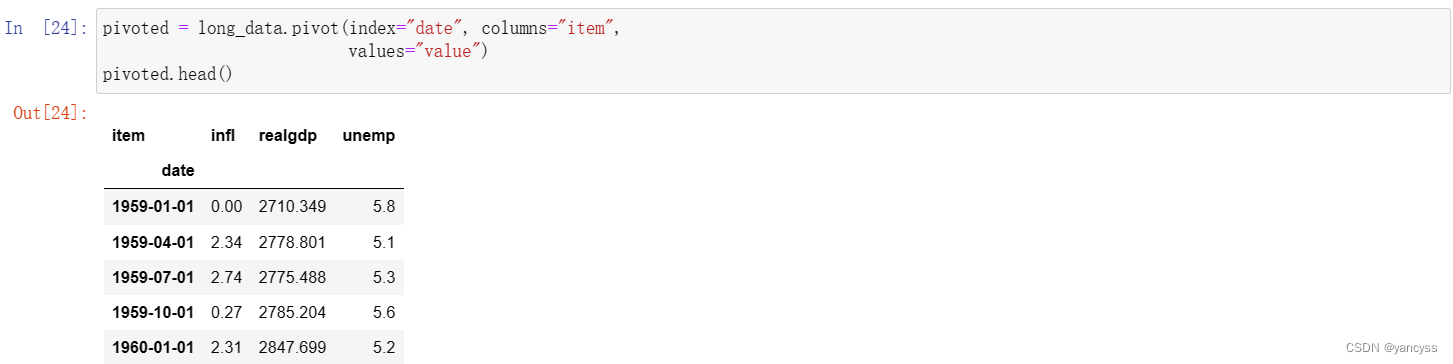
pandas由入门到精通-数据透视表
采集的数据存储后通常会分为多个文件或数据库,如何将这些文件按需拼接,或按键进行连接十分重要。这节将介绍数据索引的复杂操作如分层索引,stack,unstack,seet_index,reset_index等帮助重构数据,数据的拼接如merge,join,concat,combine_first等帮助连接数据,以及数据透视表…
Pandas 快速入门教程
Pandas 概览
Pandas 是 Pythonopen in new window 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开…
pandas 添加多个 sheet 页
pandas 添加多个sheet页
import pandas as pd
from openpyxl import load_workbook
# 读取Excel文件
file_path cs.xlsx # 替换为你的Excel文件路径
df pd.read_excel(file_path)# 指定字段和筛选项
field_to_filter 33 # 替换为你要筛选的字段名称
filter_values [1, 2…

Python数据分析实战-使用replace方法精确匹配替换某列的值(附源码和实现效果)
实现功能
将DataFrame中某一列的指定的两个值分别替换为0和1,而将其他值替换为2
实现代码
import pandas as pd# 创建一个示例DataFrame
data {A: [1, 2, 3, 4, 5],B: [a, b, c, d, e]}
df pd.DataFrame(data)# 打印替换前的DataFrame
print("替换前的Dat…

python -pandas -处理excel合并单元格问题
对于合并的单元格,不进行处理情况下,会默认输出nan问题
解决方法:
class A(object):def __init__(self, xlsx_file_path, sheet_index):self.xlsx_file FileDataProcesser.read_excel(xlsx_file_path, sheet_index)self.sheet_data self.…
pandas入门 数据结构
series
一个一维的数据对象,包含一个值序列,还有数据标签(索引,index)。也可以视为一个长度有限且有序的字典, obj4 pd.Series(sdata, states) pd.Series()接收一个数组或者字典,作为实际数据…
Pandas数据处理分析系列7-连接合并查询
Pandas 查询
Pandas 连接查询-merge
在实际数据分析过程中,有时候需要把不同的工作表,按照某些公共的列,将多个工作表连接起来,组合成一份新工作表,类似于Excel的Vlooup函数,或数据库的连接关系。Pandas 也提供了连接关系函数merge(),其将两个DataFrame的行按照指定的列…
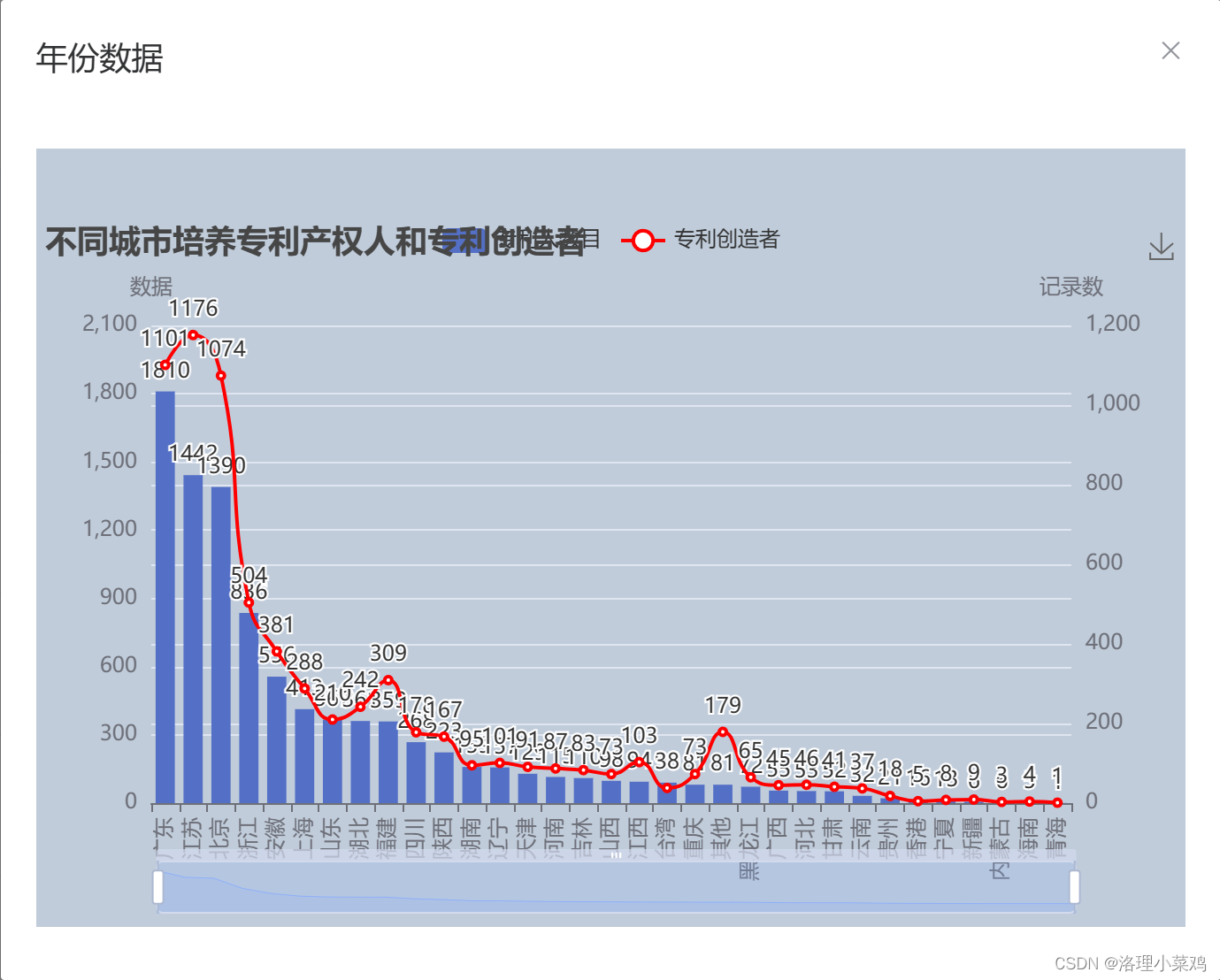
Springboot2 Pandas Pyecharts 量子科技专利课程设计大作业
数据集介绍 1.背景 根据《中国科学:信息科学》期刊上的一篇文章,量子通信包括多种协议与应用类型: 基于量子隐形传态与量子存储中继等技术,可实现量子态信息传输,进而构建量子信息网络,已成为当前科研热点&…

Python3数据科学包系列(三):数据分析实战
Python3中类的高级语法及实战
Python3(基础|高级)语法实战(|多线程|多进程|线程池|进程池技术)|多线程安全问题解决方案
Python3数据科学包系列(一):数据分析实战
Python3数据科学包系列(二):数据分析实战 一: 数据分析与挖掘认知升维 我们知道在数据分析与数据挖掘中,数据…
python一点通:数据处理顶流Pandas 2.0有什么新功能?
Pandas 2.0及其后续版本的发布引入了各种功能和增强,标志着在使用Pandas进行数据操作和分析方面的显著演进。这里是对一些新功能的深入解析: 可选依赖的安装: 在Pandas 2.0中,通过pip安装pandas时,可以通过指定extras来安装一组可…
PyPackage01---Pandas13_比较两个df是否一致
Intro
检查两个df是否完全一致
import pandas as pd
from pandas.testing import assert_frame_equalx1pd.DataFrame({"x1":[1,2],"x2":[2,3]})
x2pd.DataFrame({"x1":[1,2],"x2":[2,3]})
x3pd.DataFrame({"x1":[1,2],&qu…
chatgpt赋能Python-pythondataframe取出一列
用 Python Dataframe 取出一列
数据分析中,用到的数据往往是有多列多行的。而在实际的分析过程中,我们需要针对其中的某一列进行处理。这个时候,Python中的Dataframe就成了我们的利器。
在这篇文章中,我们将教你如何使用Python …

python orm框架
python orm框架是一个数据处理框架,它提供了许多有用的工具,包括: 1、使用 pandas库对数据进行预处理,如:添加标签、删除重复值、转换为表格样式等。 2、使用 sql语句进行数据的增删改查,如:在m…
pandas---分箱(离散化处理)、绘图、交叉表和透视表
1. 分箱
分箱操作就是将连续型数据离散化。分箱操作分为等距分箱和等频分箱.
1.1 等宽分箱
pandas.cut(x, bins, rightTrue, labelsNone, retbinsFalse, precision3, include_lowestFalse,
duplicatesraise, orderedTrue)
x:要分箱的一维数组或者 Series。
bi…
解决python问题:HTTPSConnectionPool(host=‘finance.yahoo.com‘, port=443): Read timed out. (read timeout=30
检查pip有没安装cryptography,pyOpenSSL,certifi要是没有先安装 pip install cryptography pip install pyOpenSSL pip install certifi
我安装完上述三个包后就解决问题了。

Python—Pandas学习之【排名rank】
Series
默认从小到大进行排名 对于obj来说,最小的是-2,因此-2的排名是1;第二小的是0,因此0的排名是2;obj中出现两个3,他们两个的排名分别是4和5,因此取中值排名为4.5。
为了避免出现中值排名&…

Python自动化对每个文件夹及其子文件夹的Excel表加个表头(Excel不同名且有xls文件)...
点击上方“Python爬虫与数据挖掘”,进行关注 回复“书籍”即可获赠Python从入门到进阶共10本电子书 今 日 鸡 汤 惟将旧物表深情,钿合金钗寄将去。 大家好,我是皮皮。 一、前言 上一篇文章,我们抛出了一个问题,这篇文章…
3步轻松获取Pandas DataFrame任意单元格值
在Pandas处理DataFrame数据的过程中,我们时常需要获取某个具体的单元格值进行操作。那么如何高效而灵活地从Pandas DataFrame中提取任意一个单元格的值呢? 今天分享在Pandas DataFrame获取单元格值的3大方法:
第一步:.loc[]方法,传入行列标签 使用.loc…
Pandas+sqlalchemy处理Excel-Sql写入文本和数据库
Excel数据如下 Pycharm中的包安装如下- + 然后收索install 代码如下
import pandas as pd
import sqlalchemy
from sqlalchemy import Table,MetaData,ForeignKey,Column,Integer,String,DateTime,Date,Floatdata=pd.read_excel(rC:\Users\044572\Downloads\制造中心-生产…
chatgpt赋能python:Python中None的使用详解
Python中None的使用详解
在Python语言中,None是一个非常常见的值,它在代码中用来表示空值或未定义的值。本文将介绍Python中None的使用方式,包括创建和比较None对象,以及在函数和类中使用None的方法。
创建和比较None对象
在Py…
[数据挖掘01] pandas数据对象功能大全
目录
一、说明
二、Series 容器
三、属性轴
四、数据转换
五、索引、迭代
六、二元运算符函数
七、窗口函数、分组函数( GroupBy & window )
八、计算/描述性统计
九、重建索引/选择/标签操作
十、缺失数据处理
十一、重定型、排序
十二…
仙境传说RO:npc汉化方法
仙境传说RO:npc汉化方法
大家好我是艾西,在我们说了那么多期的教程中大家应该有发现游戏内很多都还是英文的,如果对于国内的玩家开展这个游戏可能有些不熟悉的小伙伴玩起来会有点难受,今天艾西跟大家分享下怎么汉化NPC等。
我们…
pandas(三)数据查询
数值、列表、区间、条件、函数
Pandas查询数据的几种方法
df.loc方法,根据行、列的标签值查询df.iloc方法,根据行、列的数字位置查询df.where方法df.query方法
.loc既能查询,又能覆盖写入,强烈推荐!
Pandas使用df.…
chatgpt赋能python:Python快速入门:如何使用Python创建表格
Python 快速入门:如何使用Python创建表格
在数据处理和分析的过程中,表格是非常常见的数据结构。Python 是一种非常优秀的编程语言,可用于多种数据处理任务,包括表格的创建和处理。在本文中,我们将探讨如何使用 Pytho…

pandas (十) 缺失值的处理:填充、删除、过滤、查询
Pandas使用函数处理缺失值
isnull和notnull:检测是否是空值,可用于df和seriesdropna:丢弃、删除余缺失值 axis: 删除行还是列,{0 or ‘index’, 1 or ‘columns’), default 0 how: 如果等于any则任何值为空都删除,如…
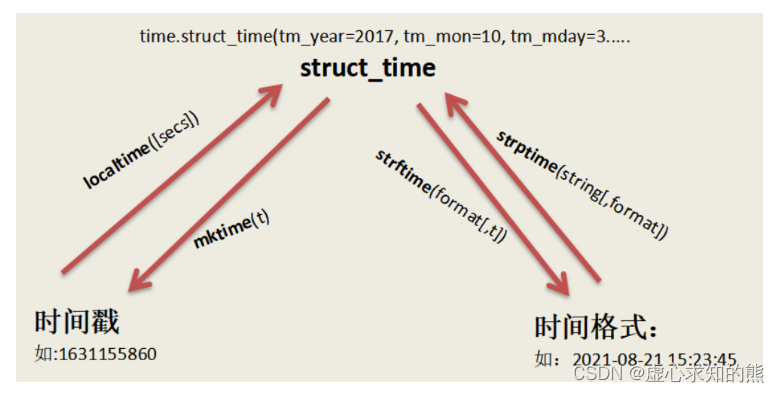
Python 之 Pandas 时间函数 time 、datetime 模块和时间处理基础
文章目录一、time 模块1、时间格式转换图2. struct_time 元组元素结构3. format time 结构化表示二、datetime 模块1. date类2. 方法和属性3. datetime 类三、timedelta 类的时间加减四、时间处理基础Python 中提供了对时间日期的多种多样的处理方式,主要是在 time …
【python】数据可视化,使用pandas.merge()对dataframe和geopandas类型数据进行数据对齐
目录
0.环境
1.适用场景
2.pandas.merge()函数详细介绍
3.名词解释“数据对齐”(来自chatGPT3.5)
4.本文将给出两种数据对齐的例子
1)dataframe类型数据和dataframe类型数据对齐(对齐NAME列);
数据对…
Windows下安装.whl
全傻瓜流程
1. 安装pip
(1) 下载 准备以下文件下载 pip下载 get-pip脚本下载
(2) 安装 打开cmd, 键入
python get-pip.py
2.安装whl
以pandas为例。在cmd键入
pip install pandas-0.20.3-cp36-cp36m-win_amd64.whl
报错
pandas-0.20.3-cp36-cp36m-win_amd64.whl i…
pandasy与numpy概念对比
numpy
NumPy 是 Python 中最流行、最常用的数值计算库之一,它提供了高效的多维数组(ndarray)对象以及对这些数组进行操作的函数和方法。NumPy 主要用于科学计算、数据分析和机器学习等方面。
pandas
Pandas 是基于 NumPy 的一个数据分析库…

sql读取数据直接存成pandas
导包
import pymysql
import pandas as pd获取mysql链接
def get_db():#打开数据库连接db pymysql.connect(host*.*.*.*,port3306,user "wws",passwd "yourpasswd",db "youdb")return db
db get_db()写sql 读数据保存
sql "select…
数据集:T-Drive(北京出租车轨迹数据)
1 数据来源
T-Drive trajectory data sample - Microsoft Research
2 数据介绍
数据集包含了2008年2月2日至2月8日期间在北京市内的10,357辆出租车的GPS轨迹。总共包含约1500万个GPS点,轨迹总里程达到了900万公里。 图1显示了两个连续点之间的时间间隔和距离间隔…
chatgpt赋能python:Python编程自动化办公–提升工作效率的利器
Python编程自动化办公 – 提升工作效率的利器
越来越多企业对协作和业务流程的优化提高了要求,自动化办公就是其中之一,而Python编程能够帮助我们实现高效自动化办公。Python是一种多用途,高效的编程语言,被广泛应用于应用程序开…
Pandas简要教程
文章目录1 前言2 安装3 Series4 DataFrame5 CSV5.1 head()5.2 tail()5.3 info()6 JSON7 数据清洗7.1 清洗空值7.2 清洗格式错误数据7.3 清洗本身错误数据7.4 清洗重复数据1 前言
Pandas 是 Python 语言的一个扩展程序库,用于数据分析,其主要数据结构是 …
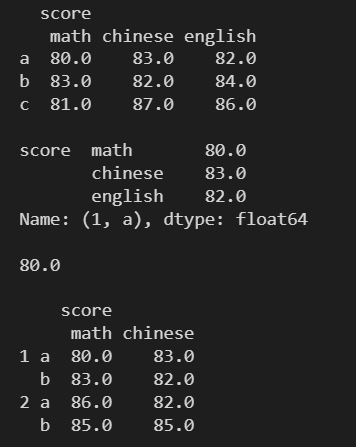
Pandas中DataFrame的属性、方法、常用操作以及使用示例
前言 系列文章目录 [Python]目录 视频及资料和课件 链接:https://pan.baidu.com/s/1LCv_qyWslwB-MYw56fjbDg?pwd1234 提取码:1234 文章目录前言1. DataFrame 对象创建1.1 通过列表创建 DataFrame 对象1.2 通过元组创建 DataFrame 对象1.3 通过集合创建 …

Python机器学习数据建模与分析——Numpy和Pandas综合应用案例:空气质量监测数据的预处理和基本分析
本篇文章主要以北京市空气质量监测数据为例子,聚集数据建模中的数据预处理和基本分析环节,说明Numpy和Pandas的数据读取、数据分组、数据重编码、分类汇总等数据加工处理功能。同时在实现案例的过程中对用到的Numpy和Pandas相关函数进行讲解。 文章目录数…
python读入excel,进行excel处理的基础操作
1.合并多个Excel文件的sheet
可以使用Python中的pandas库来读取和合并多个Excel文件的sheet。 首先需要安装pandas库,可以使用以下命令进行安装: pip install pandas 接下来,可以使用以下代码来读取和合并多个Excel文件的sheet:…
pandas---数据合并(concat、append、merge)
1. concat函数
pd.concat([data1, data2], axis1)
按照行或列进行合并,axis0为列索引,axis1为行索引。
df1 make_df([1, 2], [A, B])
df2 make_df([3, 4], [A, B])
display(df1, df2)
# 默认上下合并,垂直合并
pd.concat([df1, df2])
…
将统一标识的SCV文件批量合成excel文件
以下是使用Python将具有相同唯一标识符的大批SCV文件合并成一个Excel文件的代码: import pandas as pd import os
# 定义文件路径和文件名 folder_path /path/to/folder output_file merged.xlsx
# 获取文件夹中所有SCV文件的列表 file_list [f for f in os.li…
![【Python实用基础整合(三)】儒略日计算、Pandas写Excel文件多Sheet以及datetime64[ns]时间格式处理](https://img-blog.csdnimg.cn/55c840388dde479ebf7c5cd980987621.png)
【Python实用基础整合(三)】儒略日计算、Pandas写Excel文件多Sheet以及datetime64[ns]时间格式处理
一、儒略日计算
儒略日(Julian Day)是在儒略周期内以连续的日数计算时间的计时法,主要用于天文学领域,SMOKE、CMAQ、CAMx等模型中也有使用。Linux中主要使用IOAPI库中的juldate和jul2greg来进行常规日期和儒略日的相互转化。Pyth…

Python pandas 各类 操作 备忘
>>> import pandas as pd
>>> factors{2021:36.45,2020:35.43,2019:34.65,2018:33.9,2017:33.14}
# 必须加index,index中是列表,列表个数,即为记录数。 # 下面是以关键字为列名,共5列 >>> df pd.DataFrame(fac…
手把手教你学Python之Pandas(一文掌握数据分析与处理库-Pandas)
目录
基本结构之Series
Series对象的创建
Index对象介绍
Series中数据的访问
Series中常用方法
基本结构之DataFrame
DataFrame的创建
DataFrame中数据访问
DataFrame 常见属性
DataFrame 常见方法
DataFrame的合并操作
Pandas中常用方法
加载数据的方法
数…
python中pandas for遍历所有行以及其中列的值
#假设示例
teas pd.DataFrame(columns[name,url])
teas.loc[0] [陈xx,http://xxx.htm]
teas.loc[1] [黄xx,http://xxx.htm]
teas.loc[2] [朱xx,http://xxx.htm]#遍历行的下标以及其中列的值
for ind, row in teas.iterrows():print(ind)print(row[name])print(row[url])
python中pandas.DataFrame新添加一行
#两列,分别为name和url列
teas pd.DataFrame(columns[name,url])teaNum 0
for na in names:name naurl www.xxx.com#使用loc,注意是中括号 []teas.loc[teaNum] [name,url]teaNum1#获取值,也可以修改值
teas.loc[0,name] another
teas.l…
Python pandas常用函数详解
本文研究的主要是pandas常用函数,具体介绍如下。
1 import语句 1 2 3 4 5 import pandas as pd import numpy as np import matplotlib.pyplot as plt import datetime import re
2 文件读取 df pd.read_csv(pathfile.csv) 参数:headerNone 用默认列…
Pandas教程(非常详细)(第三部分)
接着Pandas教程(非常详细)(第一部分),继续讲述。
十三、Pandas设置数据显示格式
在用 Pandas 做数据分析的过程中,总需要打印数据分析的结果,如果数据体量较大就会存在输出内容不全࿰…
![[黑马程序员Pandas教程]——Pandas快速体验](https://img-blog.csdnimg.cn/703e7543f468482f92ecdad2b4c485b1.png)
[黑马程序员Pandas教程]——Pandas快速体验
目录:
为什么要使用Python做数据开发Python在数据开发领域的优势为什么要学习Pandas其他常用Python库介绍主要内容介绍Anaconda安装Anaconda的虚拟环境管理虚拟环境的作用可以通过Anaconda界面创建虚拟环境通过命令行创建虚拟环境通过Anaconda管理界面安装包也可以…
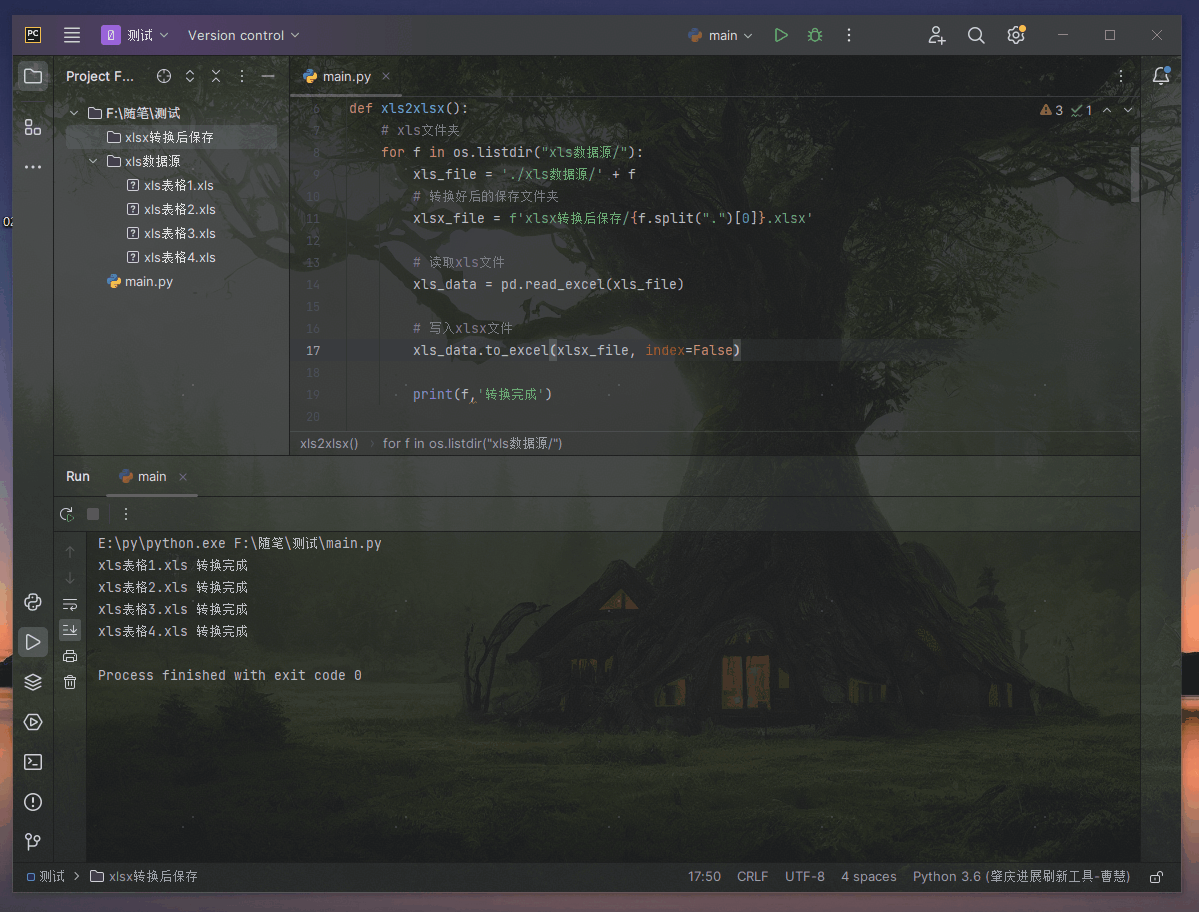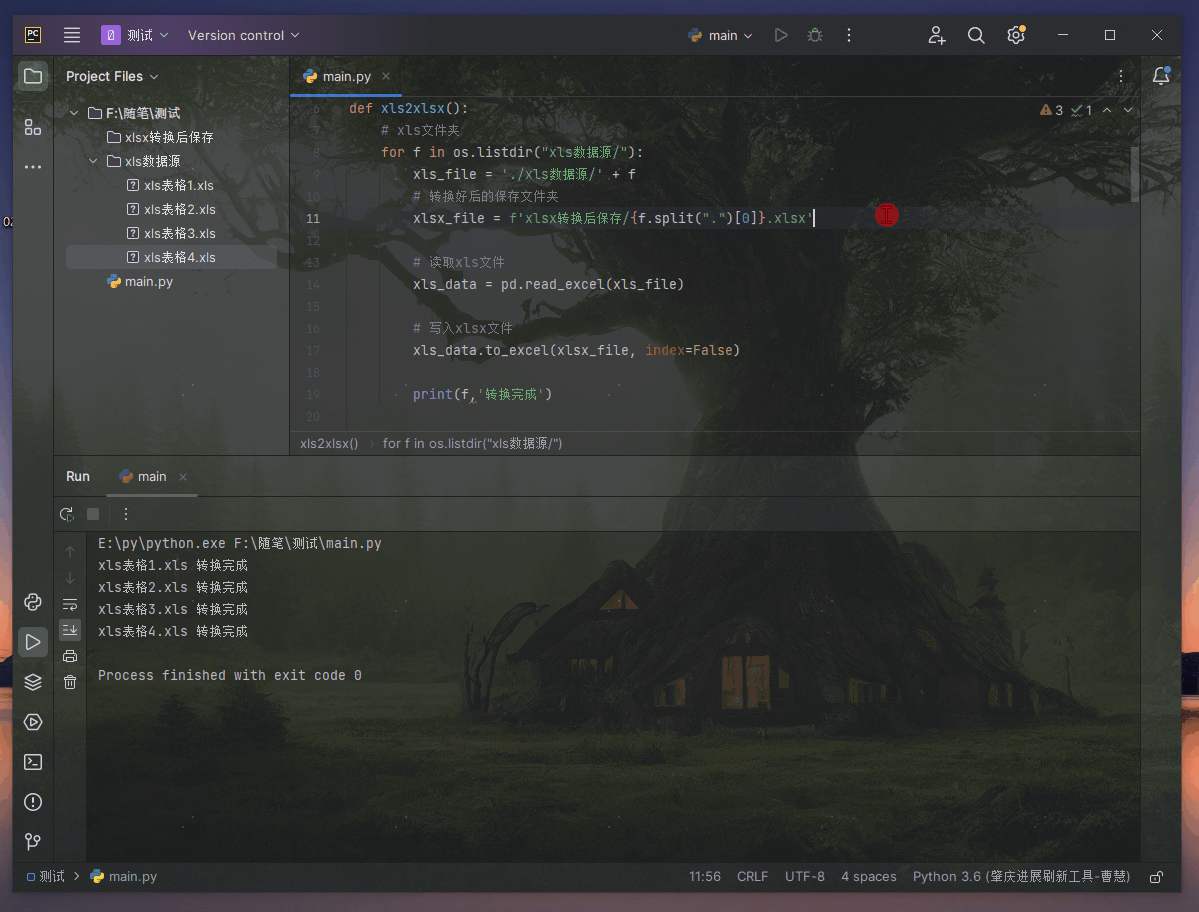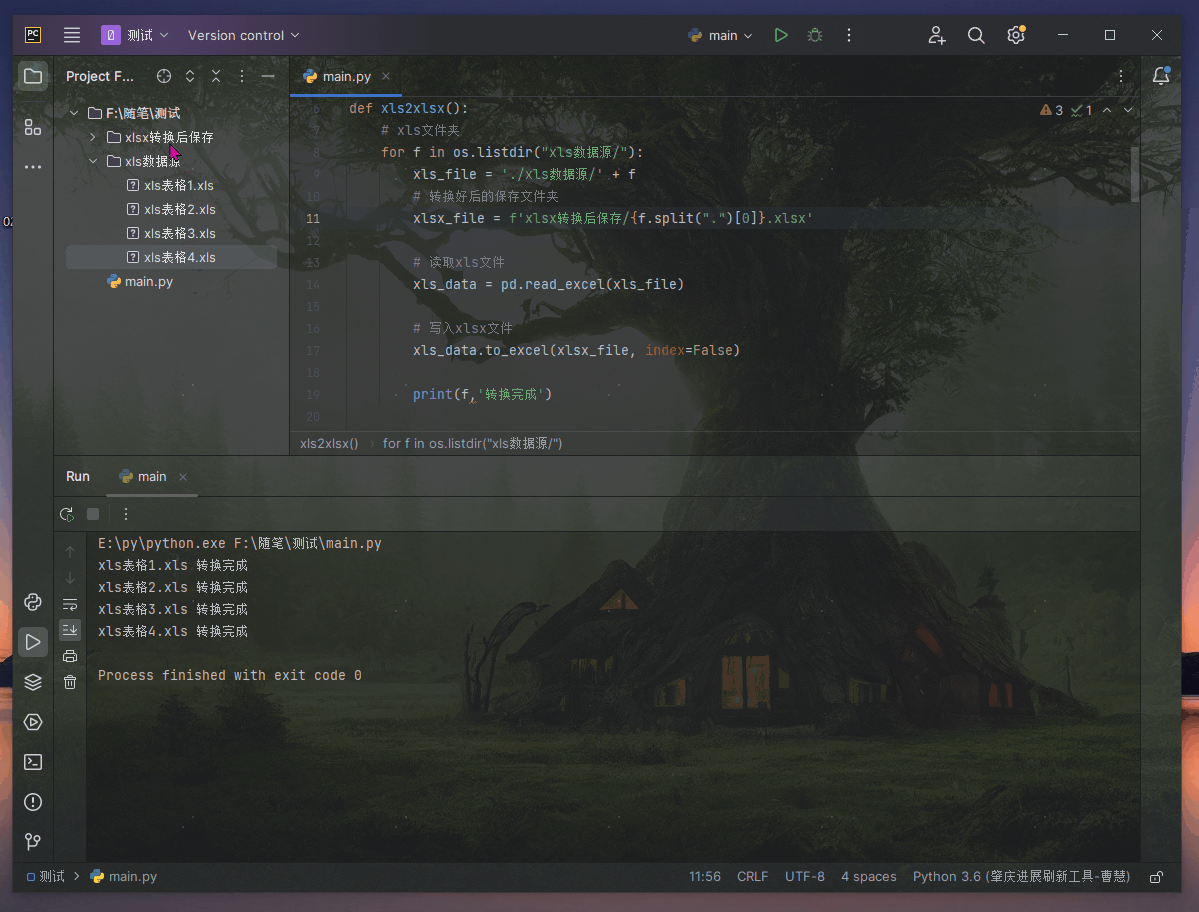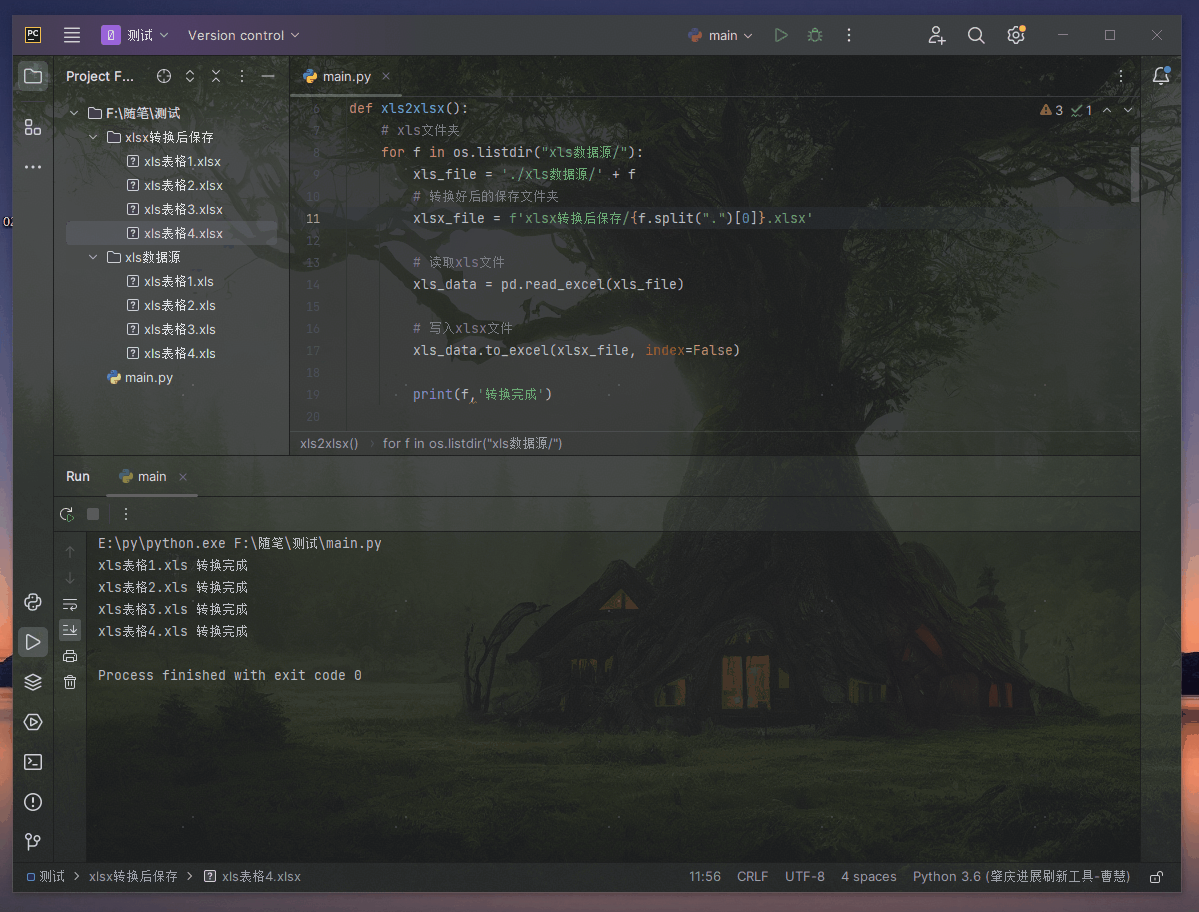
Python+pandas将Excel文件xls批量转换xlsx(代码全注释)
文章目录 专栏导读背景安装的库代码部分(全注释)视频演示总结👍 该系列文章专栏:[Python办公自动化专栏]PS: xlsx转xls文章在这:【点我直达】 专栏导读 🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的…
怎么查找性别为女性的不同学历层次不同学位以及所有人不同职务职称的人数
怎么查找性别为女性的不同学历层次不同学位以及所有人不同职务职称的人数
需求分析:
1.统计性别为女性的所获学位下不同学历层次的人数
2.统计不同职务职称的不同学位和学历层次的人数代码 def cal_xuewei_number(self):# 读取表格文件table pd.read_excel("…
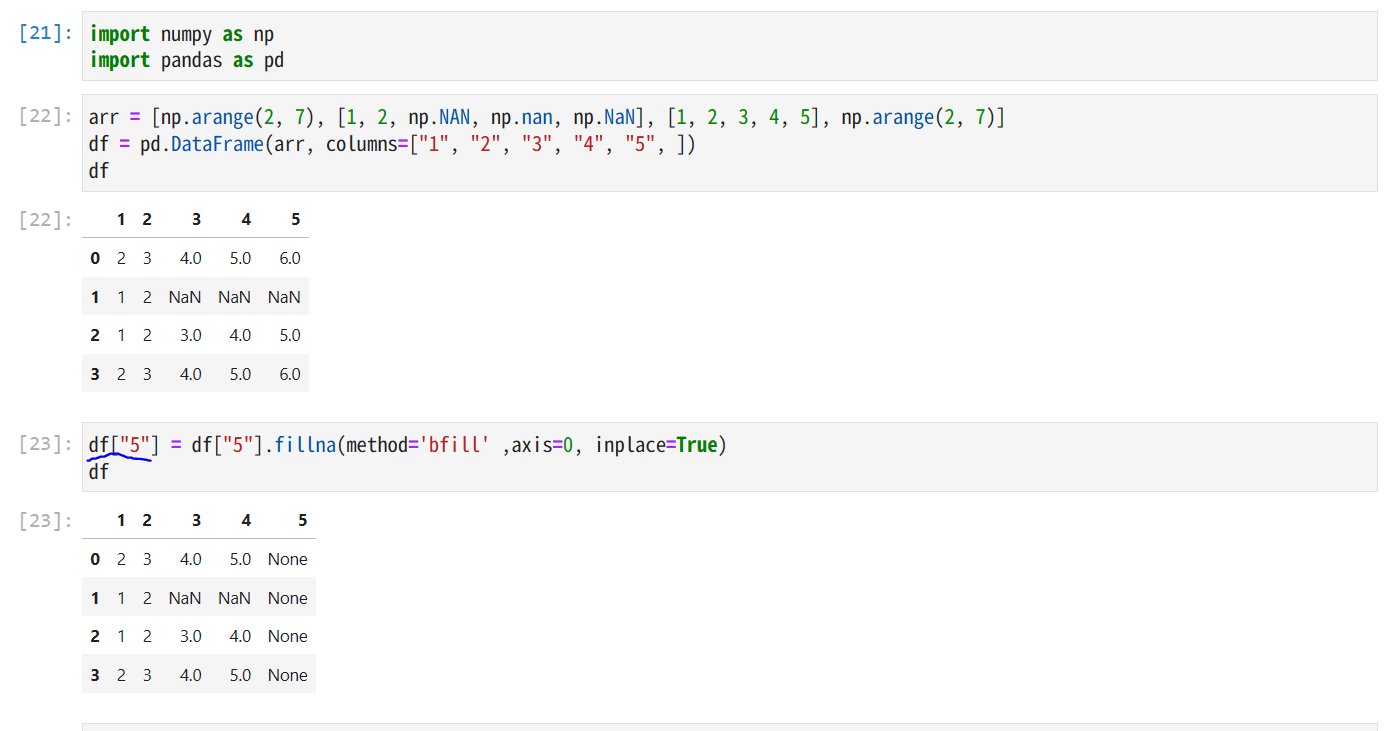
怎么通过联表合并表格的后查找不同职务职称的人数(python自动化办公,表格合并,同时查询不同类别情况下的个数)
怎么通过联表合并表格的后查找不同职务职称的人数(python自动化办公,表格合并,同时查询不同类别情况下的个数)
需求分析:
1.在本代码中,实现的功能为先合并两张子表,表一为主表,里…
[黑马程序员Pandas教程]——分组与分箱
目录:
学习目标分组对象DataFrameGroupBy 数据准备df.groupby分组函数返回分组对象分组对象其他API 取出每组第一条或最后一条数据获取分组后每组的名称gs.get_group()按分组依据获取其中一组分组聚合 分组后直接聚合分组后指定单列或多列聚合分组后使用多个聚合函数分组后对多…
pandas print输出格式设置
display pd.options.display
display.max_columns 50
display.max_rows 50
display.max_colwidth 100
display.width None
pandas --滑动窗口rolling详解
引言
为了提升数据的准确性,将某个点的取值扩大到包含这个点的一段区间,用区间来进行判断,这个区间就是窗口。移动窗口就是窗口向一端滑行,默认是从右往左,每次滑行并不是区间整块的滑行,而是一个单位一个单位的滑行。给个例子好理解一点:
import pandas as pd
s = [1…
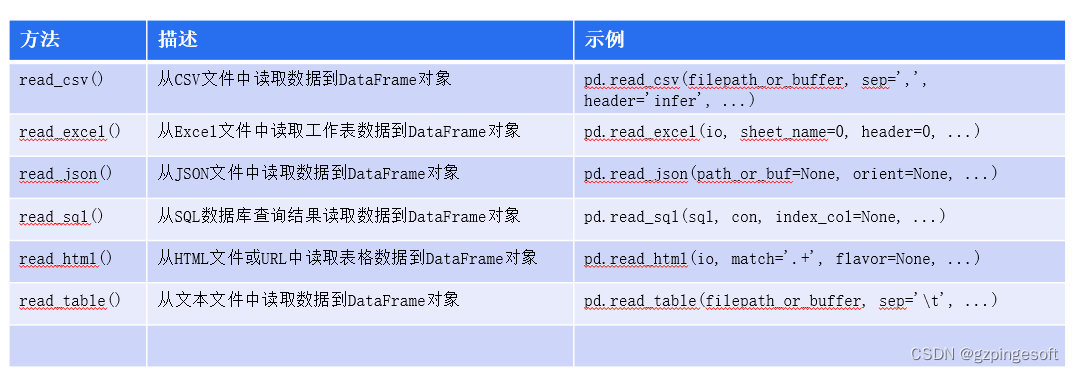
Pandas 数据分析--数据提取
Pandas Excel 数据导入
Pandas库提供了一组强大的输入/输出(I/O)函数(简称为:I/O API),用于读取和写入各种数据格式,目前已支持常见的多种外数据格式。
Pandas 常见读取方法如下表:
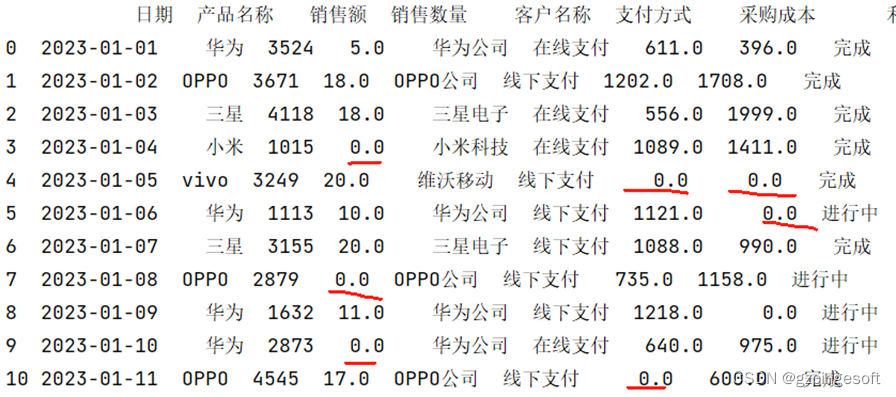
Pandas数据处理分析系列4-数据如何清洗
Pandas-数据清洗
①缺失值处理
使用fillna()函数将缺失值替换为指定的值或使用插值方法填充缺失值 示例:df.fillna(0) #将缺失值替换为0
import pandas as pddf1=pd.read_excel("销售表.xlsx")
# 检查每列是否缺失
print(df1.isna) 效果如下: import pandas as …
pandas常用数据操作记录
记录一些常用的pandas数据操作方法
#导入pandas包
import pandas as pd1. 读取保存文件
# 读取
df pd.read_csv("path", encoding"utf-9")
df pd.read_excel("path", sheet_name"Sheet1")# 保存
df df.sample(1000, random_state…
Pandas教程(非常详细)(第六部分)
接着Pandas教程(非常详细)(第五部分),继续讲述。
三十一、Pandas Excel读写操作详解
Excel 是由微软公司开发的办公软件之一,它在日常工作中得到了广泛的应用。在数据量较少的情况下,Excel 对…
python实现PDF表格与文本分别导出EXCEL
现需将pdf 转换至Excel , 目前实现方式:将PDF的TABLE部分与 非 TABLE部分分别导出至Excel两个sheet中 1)、识别PDF中的表格块 2)、将PDF转换为Word格式 3)、提取Word中非表格的文本数据 4)、对文本与表格重…
Python中的map()、apply()、applymap()的区别
map、apply、applymap的区别 1、实验背景2、实验过程3、实验结论1、实验背景 Pandas库被广泛用于数据处理和分析。map()、apply()和applymap()方法是Python中常用的转换方法,输出的结果及类型完全取决于作为给定方法的参数的函数
在日常数据处理过程中,会经常遇到这样的情况…
Pandas数据导入和导出:CSV、Excel、MySQL、JSON
MySQL查询导入
import pandascon "mysqlpymysql://user:pass127.0.0.1/test"
sql "SELECT * FROM student WHERE id 2"# sql查询
df1 pandas.read_sql(sqlsql, concon)
print(df1)导入mysql整张表
# 整张表
df2 pandas.read_sql_table(table_name&q…
pandas读取json文件,文件中包含多个json对象
文档为 file_pathtest.json, 内容如下,里面包含多个 json 对象
{"workspace_id":"20414","project_name":"创达"}
{"workspace_id":"5513","project_name":"盟博"}
{"works…
报错AttributeError: ‘DataFrame‘ object has no attribute ‘ix‘
项目场景:
在Pycharm中使用Pandas库做案例,使用DataFrame对象的ix属性时,报错DataFrame对象没有属性’ix’。 问题描述
示例代码:
for i in range(1000): count.ix[i, movie_genre[i]] 1
print(count)报错:Attribu…

Python中,我们可以使用pandas和numpy库对Excel数据进行预处理,包括读取数据、数据清洗、异常值剔除等
文章目录 一、什么是数据预处理二、对excel数据进行详细的数据预处理操作总结 一、什么是数据预处理
数据预处理是一种对数据进行清洗、整理、转换等操作的过程,旨在提高数据质量,使其适应模型的需求,从而改进数据挖掘或机器学习的结果。
数…
pandas教程:Periods and Period Arithmetic 周期和周期运算
文章目录 11.5 Periods and Period Arithmetic(周期和周期运算)1 Period Frequency Conversion(周期频度转换)2 Quarterly Period Frequencies(季度周期频度)3 Converting Timestamps to Periods (and Back…

浅析Python数据处理的相关内容及要点
文章目录 前言一、Numpy1.Numpy属性2.Numpy创建3.Numpy运算4.Numpy索引5.Numpy其他 二、Pandas1.Pandas数据结构2.Pandas查看数据3.Pandas选择数据4.Pandas处理丢失数据5.Pandas合并数据6.Pandas导入导出 三、Matplotlib关于Python技术储备一、Python所有方向的学习路线二、Pyt…

为什么在Pycharm中使用Pandas画图,却不显示?
问题描述:
在 Pycharm 中使用 Pandas 的 plot() 方法画图,却不显示图像,源代码如下:
import pandas as pd
import numpy as np# 从文件中读取数据
starbucks pd.read_csv(./file_csv/directory.csv)# 按照国家分组,…
pandas 是基于NumPy
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:第一章 Python 机器学习入门之pandas的使用 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章 系…
Python实战 | 使用 Python 的日志库(logging)和 pandas 库对日志数据进行分析
专栏集锦,大佬们可以收藏以备不时之需
Spring Cloud实战专栏:https://blog.csdn.net/superdangbo/category_9270827.html
Python 实战专栏:https://blog.csdn.net/superdangbo/category_9271194.html
Logback 详解专栏:https:/…
sklearn教程:boston波士顿房价数据集
文章目录 数据集介绍导入库划分训练集测试集导入DataFrame创建学习模型 KNN Linear DecisionTree SVR训练模型预测数据绘图可视化数据标准化模型训练和预测数据集介绍
Boston数据集是一个经典的回归分析数据集,包含了美国波士顿地区的房价数据以及相关的属性信息。该数据集共…
pandas定位选取某列某指标最大值所在的行记录,比如月底
比如对于一个股价时间序列表:
年月 年月日股价贵州茅台202301202301011500贵州茅台202301202301201600贵州茅台202301202301311400贵州茅台202302202302051300贵州茅台202302202302281700五粮液202301202301021000五粮液202301202301312000
怎样筛选出每个股票…

朴素贝叶斯应用案例 —— 商品评论情感分析
商品评论情感分析1 案例介绍2 流程实现2.1 获取数据集2.2 数据基本处理2.3 模型训练2.4 模型评估1 案例介绍
本案例提供了一个13条商品评价的小型数据集,通过对商品评价内容的分析,判断该评论是好评还是差评。 获取数据集:https://pan.baidu…
Python学习笔记(6):序列
写在前面
Hello,大家好,我是可乐。
这是Python数据分析系列的第5篇文章,今天要说的是数据结构中的序列(Series),Series是由一组数据和一组行索引构成的一维数组,可以理解为Excel里没有列名的一…
【sql小妙招】python连接数据库读入pandas并进行封装
读取为pandas格式
def conn2mysql(sql):# """# - 函数的参数为一个字符串类型的 SQL 语句# 5 返回值为一个 DataFrame 对象# """from pandas import read_sqlfrom pymysql import connect# 连接本机上的 MySQL 服务器中的 shop 数据库conn = …
史上最通俗易懂的EWMA(指数加权移动平均)的参数解释以及程序代码
文章目录 一、EWMA(指数加权移动平均)是什么?二、详细的参数解释3、使用Python pandas库中的ewm()函数实现指数加权移动平均(EWMA)的示例代码总结 一、EWMA(指数加权移动平均)是什么?…

Python自动化办公对每个子文件夹的Excel表加个表头(Excel同名)
点击上方“Python爬虫与数据挖掘”,进行关注 回复“书籍”即可获赠Python从入门到进阶共10本电子书 今 日 鸡 汤 玉容寂寞泪阑干,梨花一枝春带雨。 大家好,我是皮皮。 一、前言 前几天在Python粉丝【彩】问了一个Python自动化办公处理的问题&…
爬虫pandas库是啥呢?
爬虫是指通过程序自动化地获取互联网上的数据。在爬虫过程中,我们需要使用一些工具来处理和分析数据,其中pandas库是一个非常常用的工具。pandas库是一个开源的Python数据分析库,它提供了一些高效的数据结构和数据分析工具,可以帮…
python笔记15_实例演练_处理excel进行数据清洗
这是我在实际工作中使用到的工作小技巧(由于真实字段名称保密,以下字段名用加粗标出,并且使用与工作相同的含义做一些隐藏,无需在意实际情况,理解含义即可)
现在我需要对两个excel文件进行数据清洗&#x…

Pandas模块-数据读取和数据类型
Pandas 是一个 Python 类库,用于数据分析、数据处理、数据可视化,它具有高性能的数据结构和数据分析工具,经常与 numpy(数学计算)、scikit-learn(机器学习) 结合使用。
1. Pandas 数据读取 Pan…
pandas加载有空值的文件
各种数据库系统和文件系统在表示空值时各有特色,不尽相同。
因此,我们从各种数据库系统、文件系统导出数据时,空值会被各种各样的字符取代,例如:\NA、NULL、N、\001、NaN等。
那我们在使用pandas加载这些文件时&…
pandas的内存使用
目录
统计内存使用情况
info
memory_usage
数据类型和内存的关系 统计内存使用情况
info
ataFram对象调用 info() 时会显示 DataFrame 的内存使用情况(包括索引)。 例如,调用 info() 时会显示下面的 DataFrame 的内存使…
用Python进行数学建模(一)
一、导入数据
1.直接赋值 2.读取 Excel 文件 3.代码示例
import pandas as pd# 读取数据文件
def readDataFile(readPath): # readPath: 数据文件的地址和文件名try:if (readPath[-4:] ".csv"):dfFile pd.read_csv(readPath, header0, sep",") # 间隔…
pandas对 字符串属性 列 的操作
数据框:football
TeamGoalsYellow CardsRed CardsGermany1040Spain12110
对Team列进行字符串操作
footbal.Team.str.方法名
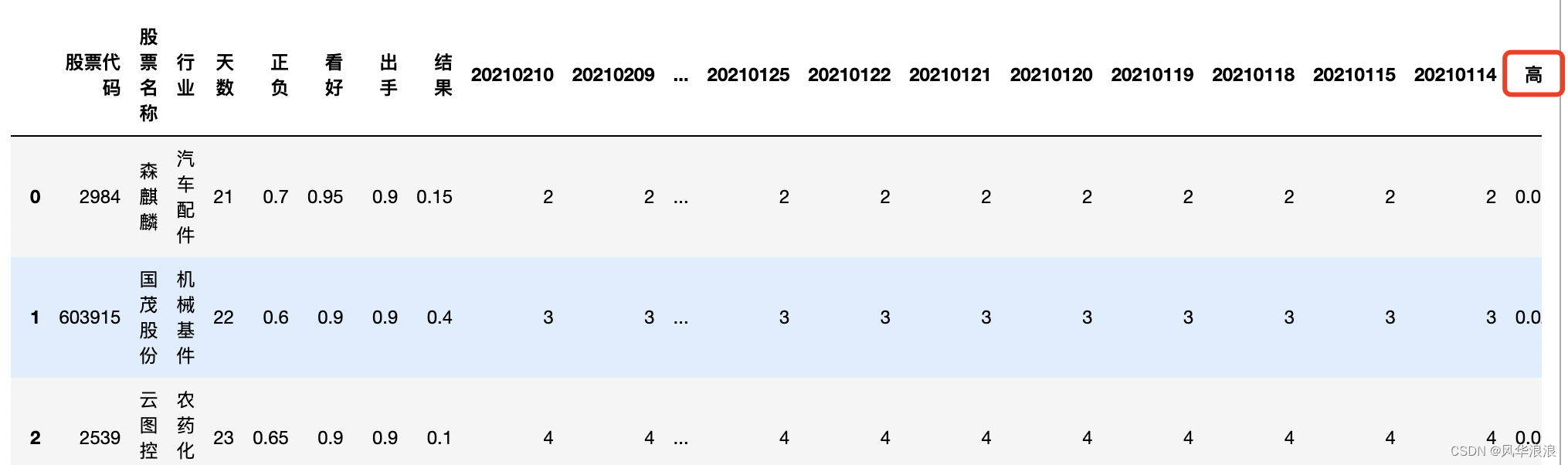
pandas(四十三)Pandas实现复杂Excel的转置合并
一、Pandas实现复杂Excel的转置合并 读取并筛选第一张表 df1 pd.read_excel("第一个表.xlsx")
df1# 删除无用列
df1 df1[[股票代码, 高数, 实际2]].copy()
df1df1.dtypes股票代码 int64
高数 float64
实际2 int64
dtype: object读取并处理第二张表…
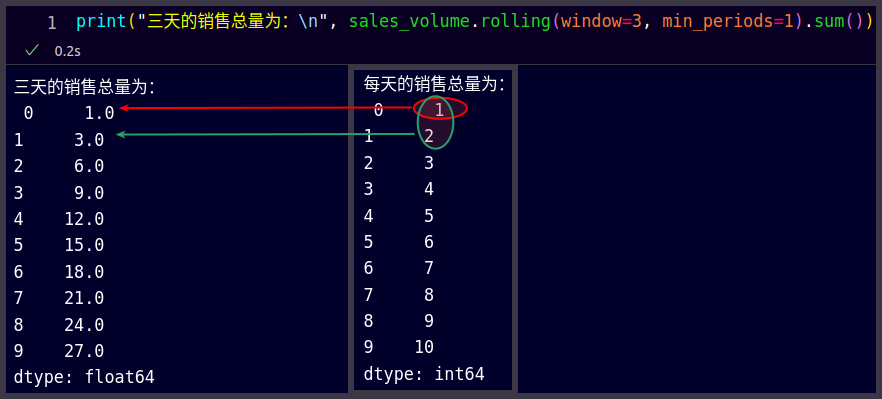
Pandas滑动窗口函数rolling()的使用方法(入门够用)
Pandas滑动窗口函数rolling()的使用方法(入门够用) 📝 在时间序列信号处理过程中,经常会用到滑动窗口处理方法:它规定一个特定单位长度的窗口来选区信号信号序列,然后计算该窗口中信号的统计指标。rolling(…

数据分析_04_pandas
pandas
处理除了数值型的数据之外的其他类型数据 常用数据类型 Series 一维数据,带标签的数组DataFrame 二维数据 创建Series数组 pd.Series([1,23,2,2,1], indexlist(“abcde”)) 也可以用字典转换到Series 转变数值类型 t2.astype(float)
切片和索引 获取值 …

附录一-pandas操作excel
文章参考 Python之如何使用pandas操作Excel表_1XXXXXXXXXXXXXXXXX1的博客-CSDN博客
我现在有一个 test.xlsx 文件,内容如下 目录
1 获取行列信息
2 获取单元格的值
3 改变单元格的值并保存到原文档 1 获取行列信息
pandas读取行号会不读取第一行 2 获取单…

【数学建模相关】matplotlib画多个子图(散点图+ 拟合曲线 线性,二次,指数 求 可决系数r^2)
文章目录例题例图代码展示例题
乙醇偶合制备 C4 烯烃
C4 烯烃广泛应用于化工产品及医药的生产,乙醇是生产制备 C4 烯烃的原料。
在制备过程中,催化剂组合(即:Co 负载量、Co/SiO2 和 HAP 装料比、乙醇浓度 的组合)与…
一文带你了解”数据分箱“技术
一文带你了解”数据分箱“技术 引言:什么是分箱? 分箱就是把数据按特定的规则进行分组,实现数据的离散化,增强数据稳定性,减少过拟合风险。逻辑回归中进行分箱是非常必要的,其他树模型可以不进行分箱。 01.…
Pandas apply 应用介绍
1、解释说明: 在Python的Pandas库中,apply()函数是一个非常强大的工具,它允许你对DataFrame或Series中的数据应用一个自定义函数。这个函数可以是一个内置函数,也可以是你自定义的函数。apply()函数的基本语法如下:
d…
pandas的 移动窗口函数rolling
pandas中有很多以rolling_开头的函数实现了滑动计算,例如: rolling_mean 移动窗口的均值 rolling_median 移动窗口的中位数 rolling_std 移动窗口的标准差 rolling_min 移动窗口的最小值 等等
可参考: https://blog.csdn.net/xxzhangx/artic…
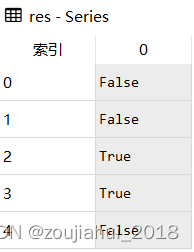
pandas中的文本包含函数.str.contains()
.str.contains()
.str.contains()会判断字符是否有包含关系,返回布尔序列,经常用在数据筛选中,它默认支持正则表达式,如果不需要,可以关掉。参数na可以指定对空值的处理方式。
import pandas as pd
import numpy as …
pandas使用中的坑
文章目录文件读写问题1问题2字典转DataFrame()的问题直接在创建DataFrame时设置index通过from_dict函数将value为标称变量的字典转换为DataFrame对象列表名义赋值与变量赋值列表快速赋值之坑列表循环之坑字典赋值问题生成器for不接受循环变量的赋值lambda函数之坑pandas读写数据…

Python3数据科学包系列(二):数据分析实战
Python3中类的高级语法及实战
Python3(基础|高级)语法实战(|多线程|多进程|线程池|进程池技术)|多线程安全问题解决方案
Python3数据科学包系列(一):数据分析实战
Python3数据科学包系列(二):数据分析实战 一:通过read_table函数读取数据创建(DataFrame)数据框 #…

pandas中的Series和DataFrame的区别与转化
1.series数据类型
1. Series相当于数组numpy.array类似
Series 它是有索引,如果我们未指定索引,则是以数字自动生成。
objSeries([4,7,-5,3])print obj
#输出结果如下:
0 4
1 7
2 -5
3 3如果数据被存在一个python字典中&#x…
python转换任意时间字符串为datetime时间对象
import datetime
from dateutil import parserdef getDateTime(s):d parser.parse(s)return d
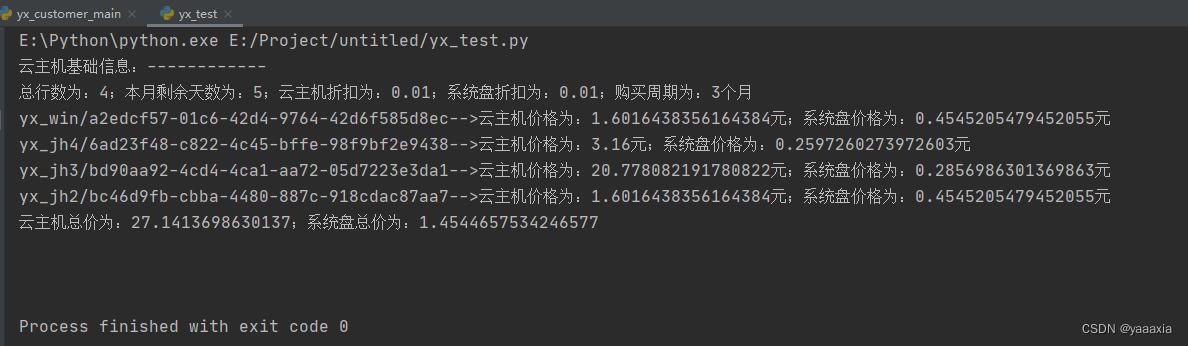
pytho实例--pandas读取表格内容
前言:由于运维反馈帮忙计算云主机的费用,特编写此脚本进行运算 如图,有如下excel数据 计算过程中需用到数据库中的数据,故封装了一个读取数据库的类
import MySQLdb
from sshtunnel import SSHTunnelForwarderclass SSHMySQL(ob…

使用groupby分组后agg函数对单列进行多种运算和对多列进行多种运算
import pandas as pd
import numpy as np
url https://raw.githubusercontent.com/HoijanLai/dataset/master/PoliceKillingsUS.csv
df pd.read_csv(url,sep,)
df1.对多列运算
df.groupby(race).agg({age:np.median,signs_of_mental_illness:np.sum})2.对单列进行多个运算
…
大数据(五):Pandas的基础应用详解(二)
专栏介绍
结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来!
全部文章请访问专栏:《Python全栈教…
pandas argmax 和max区别
argmax 和 max 是 Pandas 中的两个函数,它们在处理数据时发挥了不同的作用。
argmax函数用于返回数据集中最大(或最小)值的索引。如果数据集中有多个相同的最大(或最小)值,那么这个函数将返回第一个出现该…
pandas使用列号查找列
显示第0、1、3列的标题
df.columns[[0,1,3]]然后可以使用drop函数进行删除列操作
df.drop(df.columns[[0,1,3]],axis 1)如果此时列没有列名,可以直接向columns赋值
df.columns[first,second,third]
Pandas数据分析教程-数据清洗-字符串处理
pandas-02-数据清洗&预处理 D. 字符串处理1. Python自带的字符串处理函数2. 正则表达式3. Series的str属性-pandas的字符串函数文中用S代指Series,用Df代指DataFrame 数据清洗是处理大型复杂情况数据必不可少的步骤,这里总结一些数据清洗的常用方法:包括缺失值、重复值、…
pandas由入门到精通-Pandas的基本功能
pandas基础介绍-命令模版 基本功能reindex 重新索引drop 丢弃元素算数与数据对齐函数apply与映射map1. 逐元素函数2. 一维数组上的函数映射于每一行或每一列排序sort 与排名 rank1. 排序2. 排名本文介绍pandas中一些常用的属性方法的概述,给读者提供快速学习的架构和思路。表格…

python datetime类型简单使用
一.date类介绍
作用:date类用来处理日期信息 date类是datetime的内嵌类,实例化语法: datetime.date(year,month,day)
参数介绍: year年份、month月份及day日期
import datetime
tdatetime.date(2019,8,26)
print(type(t))
prin…
模型预测笔记(四):pandas_profiling生成数据报告
文章目录 介绍安装代码 介绍
pandas_profiling是一个基于Python的开源库,用于生成数据分析报告。它可以自动分析数据集的各种统计指标,并生成一个详细的HTML报告,包括数据的基本信息、缺失值分析、唯一值分析、数值变量的描述统计、相关性分…
正则表达式“\s+“
\s表示匹配任何空白字符,包括空格、制表符、换页符等等, 等价于[ \f\n\r\t\v] 而"\s"则表示匹配任意多个上面的字符
\f -> 匹配一个换页
\n -> 匹配一个换行符
\r -> 匹配一个回车符
\t -> 匹配一个制表符
\v -> 匹配一个垂直制表符作者&…
Python数据攻略-Pandas的数据计算、拼接与可视化
如何将数据转化为有用的信息?在数据分析的世界里,仅仅拥有大量数据是不够的。需要有方法去“翻译”这些数据,让它们告诉我们一些有用的信息。
本篇文章要探讨的内容:如何使用Pandas进行数据计算、拼接和可视化,从而让数据“说话”。 文章目录 Pandas的数据计算基本数学运…
[LeetCode系列] 30天pandas挑战
很久没有写AI或者Python相关的代码,毕竟现在已经不是一个算法工程师了。所以就用白嫖版的leetcode练练手。
先丢个代码,再慢慢填坑把
import pandas as pd# 1.大的国家,选出面基至少为300万或者人口至少为2500万的国家
# 简单的pandas过滤
…
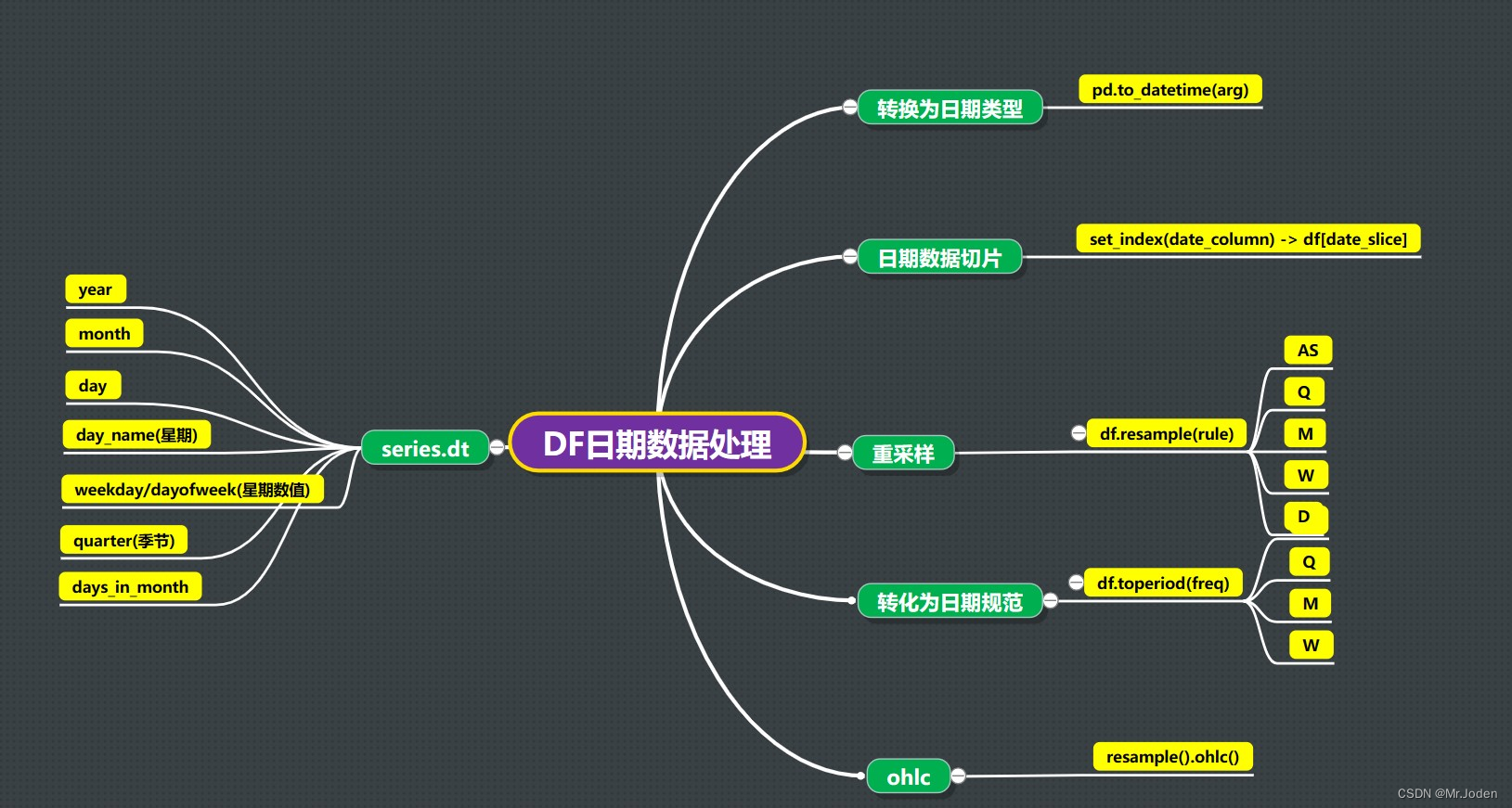
python数据分析总结(pandas)
目录
前言
df导入数据
df基本增删改查
数据清洗
编辑
索引操作
数据统计
行列操作
编辑
df->types
数据格式化
编辑
日期数据处理 前言 此篇文章为个人python数据分析学习总结,总结内容大都为表格和结构图方式,仅供参考。 df导入数…
Python Pandas 如何给DataFrame增加一行/多行 数据(第6讲)
Python Pandas 如何给DataFrame增加一行/多行 数据(第6讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ…
df:根据公共列合并两个df
import pandas as pddf1 pd.DataFrame({id: [A, B, C, D],age: [1, 2, 3, 4]})# df1为:id age
0 A 1
1 B 2
2 C 3
3 D 4df2 pd.DataFrame({id: [B, D, E, F],CRP: [5, 6, 7, 8]})# df2为:id CRP
0 B 5
1 D 6
2 E 7
3 F…
df:根据公共列合并两个df
import pandas as pddf1 pd.DataFrame({id: [A, B, C, D],age: [1, 2, 3, 4]})# df1为:id age
0 A 1
1 B 2
2 C 3
3 D 4df2 pd.DataFrame({id: [B, D, E, F],CRP: [5, 6, 7, 8]})# df2为:id CRP
0 B 5
1 D 6
2 E 7
3 F…
Python Pandas 删除局部数据 (第10讲)
Python Pandas 删除局部数据 (第10讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ�…
MySQL查询时间处理相关函数与方法实践笔记
1. 实践案例
在查询mysql数据库获取数据时,有这样一个需求:按每30分钟分组获取电量数据,形成1天48个数据点。
方法一:
select hour(a.CreateTime) 时点,case when MINUTE(a.CreateTime)<30 then 1 else 2 end 半小时,sum(a…
pandas库中的to_numberic
将参数转换为数字类型。
默认返回dtype为float64或int64, 具体取决于提供的数据。使用downcast参数获取其他dtype。
参数 描述 args 接受scalar, list, tuple, 1-d array, or Series类型 errors 有3种类型{‘ignore’, ‘raise’, ‘coerce’}, 默认为‘raise’ d…
Pandas groupby方法中的group_keys属性
pandas版本1.5.3中groupby方法,当设置group_keysTrue时,会以groupby的字段为第一级索引,如下述代码中time_id作为第一级索引,同时保留了原dataframe(df)中的索引作为第二级索引。
>>> df.groupby…
Python Pandas Excel/csv文件的保存与读取(第14讲)
Python Pandas Excel/csv文件的读取于保存(第14讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔…
Pandas实践_分类数据
文章目录 一、cat对象1.cat对象的属性2.类别的增加、删除和修改 二、有序分类1.序的建立2.排序和比较 三、区间类别1.利用cut和qcut进行区间构造2.一般区间的构造3.区间的属性与方法 一、cat对象
1.cat对象的属性
在pandas中提供了category类型,使用户能够处理分类…
pandas教程:GroupBy Mechanics 分组机制
文章目录 Chapter 10 Data Aggregation and Group Operations(数据汇总和组操作)10.1 GroupBy Mechanics(分组机制)1 Iterating Over Groups(对组进行迭代)2 Selecting a Column or Subset of Columns (选中…
使用prettytable美化dataframe输出的表格
文章目录 Prettytable简单示例输出DataFrame为PrettyTable Prettytable简单示例
prettytable的简单应用:
from prettytable import PrettyTablepre_table PrettyTable()
pre_table.title 这是标题
pre_table.field_names ["列1", "列2", &…

Python风控实战催收评分卡(xgb)
目录
一、数据读取
二、变量统计
三、模型构建
四、评分使用
五、划重点
少走10年弯路 在风控环节中,传统观念A卡为主、B卡C卡为辅,但是在市场逐步饱和、政策利率要求越来越低的背景下,B卡和C卡也越来越重要。本文以简易贷后数据实战催…
Python pandas 操作 excel 详解
文章目录 1 概述1.1 pandas 和 openpyxl 区别1.2 Series 和 DataFrame 2 常用操作2.1 创建 Excel:to_excel()2.2 读取 Excel:read_excel()2.2.1 header:标题的行索引2.2.2 index_col:索引列2.2.3 dtype:数据类型2.2.4 …
Pandas 高级教程——IO 操作
Python Pandas 高级教程:IO 操作
Pandas 提供了强大的 IO 操作功能,可以方便地读取和写入各种数据源,包括文本文件、数据库、Excel 表格等。本篇博客将深入介绍 Pandas 中的高级 IO 操作,通过实例演示如何灵活应用这些功能。
1.…
关于pandas dataframe数据转换为JSON格式存储在Redis后,读取数据时发生数据篡改的问题以及解决办法
问题:当时处理股票数据,获取到以dataframe数据结构的股票,由于Redis 是一个内存中的数据结构存储系统,但是不接受dataframe数据结构的数据,选择将其先转化为JSON格式,但发现再将JSON格式转化为原数据时&…

Pandas教程(三)—— 数据清洗与准备
1.处理缺失值 1.1 数据删除函数 作用:删除Dataframe某行或某列的数据 语法:df.drop( labels [ ] ) drop函数的几个参数: labels :接收一个列表,内含删除行 / 列的索引编号或索引名 axis &…
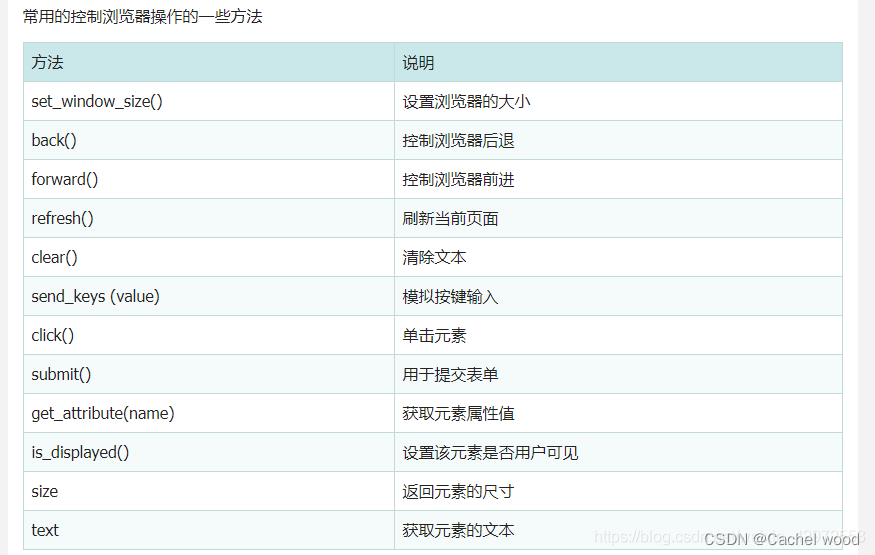
python爬虫教程:selenium常用API用法和浏览器控制
文章目录 selenium apiwebdriver常用APIwebelement常用API 控制浏览器 selenium api
selenium新版本(4.8.2)很多函数,包括元素定位、很多API方法均发生变化,本文记录以selenium4.8.2为准。
webdriver常用API
方法描述get(String url)访问目标url地址&…

从入门到精通!Python数据分析畅销书《利用Python进行数据分析》第三版中文版助你成为数据分析师!
Python数据分析畅销书《利用Python进行数据分析》第三版中文版助你成为数据分析师! 个人简介什么是数据分析如何自学数据分析书籍推荐作译者简介作者简介译者简介 主要变动导读视频:购书链接:参与方式往期赠书回顾 个人简介 🏘️&…
sort和sorted的区别、numpy和pandas、fastapi的原理、sso的单点登录、MySQL的日志、(缓存雪崩、缓存击穿、缓存穿透)
1 sort和sorted的区别
sort 和 sorted 是 Python 中用于对可迭代对象进行排序的两个方法,主要的区别在于它们的使用方式和影响:
1. **sort 方法:**- sort 是列表对象的方法,作用在原列表上进行排序,不会返回一个新的列…
67_Pandas将切片应用于字符串,以提取任意位置和长度的部分
67_Pandas将切片应用于字符串,以提取任意位置和长度的部分
Python 字符串(内置类型 str)方法应用于 pandas.DataFrame 列( pandas.Series),请使用 .str(str 访问器)。
例如&#x…
19. Python 数据处理之 Pandas
目录 1. 认识 Pandas2. 安装和导入 Pandas3. Pandas 数据结构4. Pandas 基本功能5. Pandas 数据分析 1. 认识 Pandas
Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
Pandas 的出…
pandas教程:Introduction to statsmodels statsmodels简介
文章目录 13.3 Introduction to statsmodels(statsmodels简介)1 Estimating Linear Models(估计线性模型)2 Estimating Time Series Processes(预测时序过程) 13.3 Introduction to statsmodels(…
pandas教程:Reading and Writing Data in Text Format (以文本格式读取和写入数据)
文章目录 Chapter 6 Data Loading, Storage, and File Formats(数据加载,存储,文件格式)6.1 Reading and Writing Data in Text Format (以文本格式读取和写入数据)1 Reading Text Files in Pieces(读取一部分文本&…
利用pandas提取某个列中不重复项目
假设存在以下数据: user_id age gender occupation zip_code 1 24 M technician 85711 2 53 F other 94043 3 23 M writer 32067 4 24 M technician 43537 5 33 F other 15213 6 42 M executive 98101 7 57 M administrator 91344 8 36 M administrator 05201 9 29 …
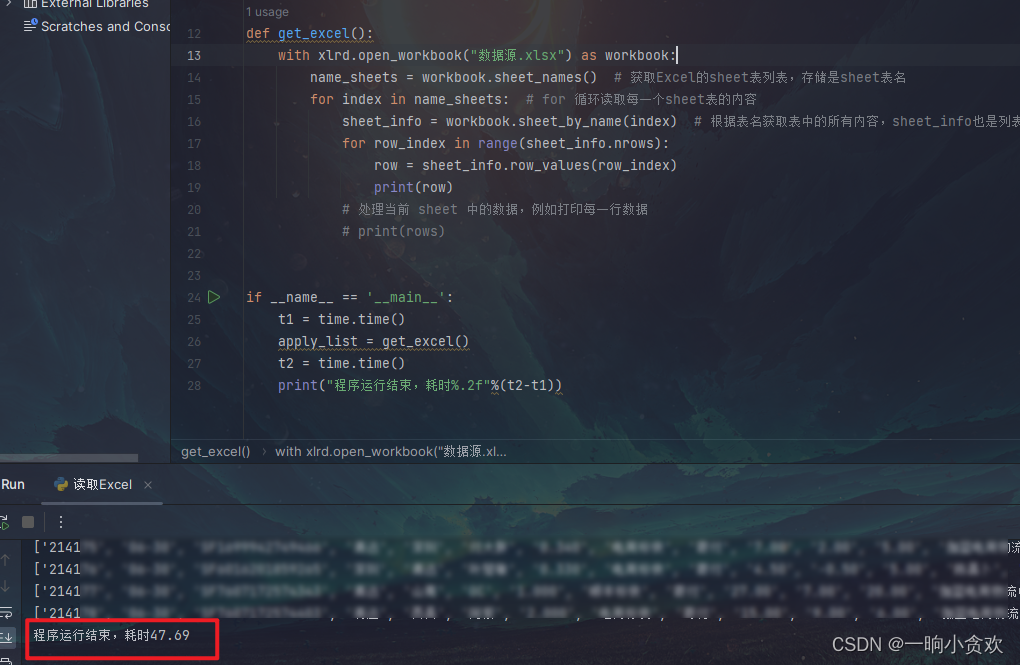
Python读取Excel每一行为列表—大PK(openpyxl\pandas\xlwings\xlrd)看谁用时少?
目录 背景使用—openpyxl(耗时89秒输出)使用—pandas(耗时44秒输出)使用—xlwings(耗时15秒输出)使用—xlrd(耗时47秒输出)总结 背景
我们在平常办公的时候,尤其是财务人…
Pandas的窗口函数rolling和expanding用法说明
Pandas的窗口函数rolling和expanding
1、rolling 移动窗口
rolling() 移动窗口函数,它可以与 mean、count、sum、median、std 等聚合函数一起使用。为了使用方便,Pandas 为移动函数定义了专门的方法聚合方法,比如 rolling_mean()、rolling_…

Python进行数据相关性分析实战
平时在做数据分析的时候,会要对特征进行相关性分析,分析某些特征之间是否存在相关性。本文将通过一个实例来对数据进行相关性分析与展示。
一、数据集介绍
本次分析的是企业合作研发模式效果分析,企业的合作研发大致分为 企企合作、企学合作…
将多个单独的 Excel 文件合并成一个,并添加标题行
要将多个单独的 Excel 文件合并成一个,并添加标题行,可以使用 Python 的 pandas 库。以下是一个示例代码,假设要合并的 Excel 文件都在同一个文件夹中: import os import pandas as pd
# 指定文件夹路径 folder_path path/to/fo…

Python:23种Pandas核心操作方法
前言
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 Pandas 是一个 Python 软件库,它提供了大量能使我们快速便捷地处理数据的函数和方法。
一般而言,Pandas 是使 Python 成为强大而高效的数据分析环境的重要因素之一。
在本文中,作者从基本…
pandas数据处理之构建联邦学习数据
本文以天池比赛《车辆贷款违约预测》的数据为例,通过pandas处理数据,构建联邦学习数据,用于FATE框架联邦学习。
通过pandas处理数据
1. 读取数据
下载car_loan_train.csv数据后,用pandas读取数据。
import pandas as pddatapd…
第二章:25+ Python 数据操作教程(第十二节python datetime 模块以及如何使用它来处理日期、时间和日期时间格式的列-变量)
在本教程中,我们将介绍 python datetime 模块以及如何使用它来处理日期、时间和日期时间格式的列(变量)。它包含各种实际示例,可帮助您增强使用 Python 函数处理日期和时间的信心。一般来说,日期类型列不容易操作,因为它面临很多挑战,例如处理闰年、一个月中的不同天数、…
【Pandas】Apply自定义行数
文章目录 1. Series的apply方法2. DataFrame的apply方法2.1 针对列使用apply2.2 针对行使用apply Pandas提供了很多数据处理的API,但当提供的API不能满足需求的时候,需要自己编写数据处理函数, 这个时候可以使用apply函数apply函数可以接收一个自定义函数, 可以将DataFrame的行…

Pandas 掉包侠刷题实战--条件筛选
本博文内容为力扣刷题过程的记录,所有题目来源于力扣。 题目链接:https://leetcode.cn/studyplan/30-days-of-pandas/ 文章目录 准备工作1. isin(values) 和 ~2. df.drop_duplicates()3. df.sort_values()4. df.rename()5. pd.merge() 题目-条件筛选1. 大…

DA1--用pandas查看网站用户数据
目录
1.题目描述
2.输入描述
3.输出描述
4.题目分析
5.通过代码 1.题目描述 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID …

Pandas+Pyecharts | 北京近五年历史天气数据可视化
文章目录 🏳️🌈 1. 导入模块🏳️🌈 2. Pandas数据处理2.1 读取数据2.2 处理最低气温最高气温数据2.3 处理日期数据2.4 处理风力风向数据 🏳️🌈 3. Pyecharts数据可视化3.1 2018-2022年历史温度分布…
python的第三方模块pandas模块学习笔记
pandas模块是python的第三方模块
Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。Pandas 已经成为 Python 数据分析的必备高级工…

pandas中如何取需要的列数据以及转化成字符串数据
1.并不想展示所有的数据,只要某一列的几个数据,操作方法 板块 A股代码 A股简称 A股上市日期 A股总股本 A股流通股本 所属行业 0 主板 000001 平安银行 1991-04-03 19,405,918,198 19,405,546,950 J 金融业 1 主板 000002 万 科A 1991-01-29 9…
将 Pandas 换为交互式表格的 Python 库
Pandas是我们日常处理表格数据最常用的包,但是对于数据分析来说,Pandas的DataFrame还不够直观,所以今天我们将介绍4个Python包,可以将Pandas的DataFrame转换交互式表格,让我们可以直接在上面进行数据分析的操作。
Piv…
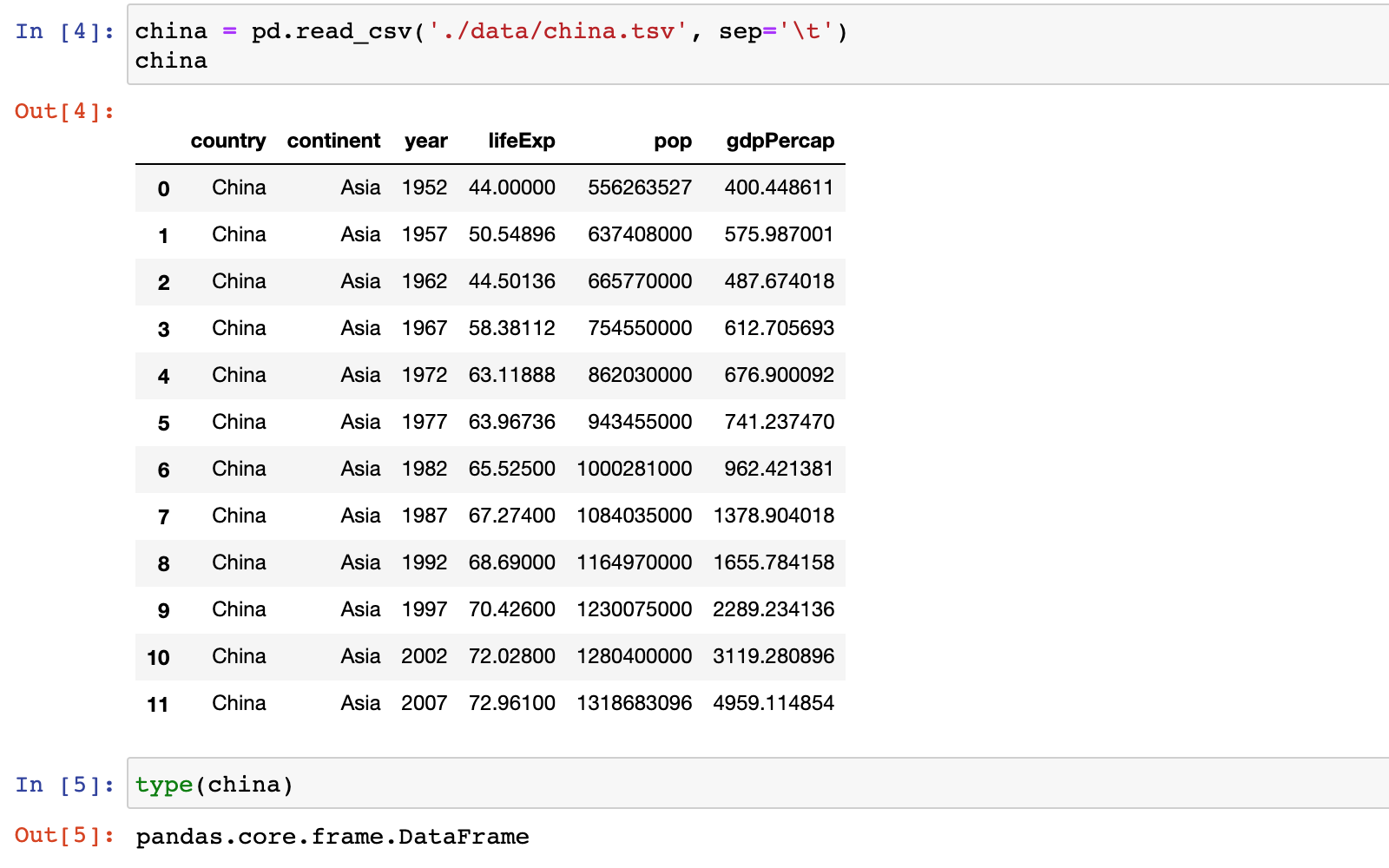
Python大数据之pandas快速入门(一)
文章目录 pandas快速入门学习目标1. DataFrame 和 Series 简介2. 加载数据集(csv和tsv)2.1 csv和tsv文件格式简介2.2 加载数据集(tsv和csv) pandas快速入门
学习目标
能够知道 DataFrame 和 Series 数据结构能够加载 csv 和 tsv 数据集能够区分 DataFrame 的行列标签和行列位…
Python--Pandas库函数文档API
关键缩写和包导入 缩写:
df:任意的Pandas DataFrame对象 s:任意的Pandas Series对象 导入包:
import pandas as pd import numpy as np
导入数据 pd.read_csv(filename):从CSV文件导入数据 pd.read_table(fil…

【python学习第12节 pandas】
文章目录 一,pandas1.1 pd.Series1.2 pd.date_range1.3 pd_DataFrame1.4浏览数据1.5布尔索引1.6设置值1.7操作1.8合并1.8.1concat()函数1.8.2 merge()函数 一,pandas
1.1 pd.Series
pd.Series 是 Pandas 库中的一个数据结构&…
paddle.load与pandas.read_pickle的速度对比(分别在有gpu 何无gpu 对比)
有GPU 平台
测试通用代码 import time
import paddle
import pandas as pd# 测试paddle.load
start_time time.time()
paddle_data paddle.load(long_attention_model)
end_time time.time()
print(f"Paddle load time: {end_time - start_time} seconds")# 测试…
![[Pandas] pandas.melt](https://img-blog.csdnimg.cn/0dc4a5ed794f4a7682a2ed58eb26e82f.png)
[Pandas] pandas.melt
melt是溶解 / 分解的意思,即拆分数据
melt()函数可以将一些列的内容进行合并,把宽表整合成长表
语法格式
pandas.melt(frame, id_varsNone, value_varsNone, var_nameNone, value_namevalue)参数说明 frame:要处理的数据集 id_vars&#…

python数据分析基础—pandas中set_index()、reset_index()的使用
文章目录 一、索引是什么?二、set_index()三、reset_index() 一、索引是什么?
在进行数据分析时,通常我们要根据业务情况进行数据筛选,要求筛选特定情况的行或列,这时就要根据数据类型(Series或者DataFrame)的索引情况…
Pandas - 数据转换
数据转换一班包括一列数据转换为多列数据,行列转换,DataFrame转换为字典、DataFrame转换为列表和DataFrame转换为元组等。
1.一列数据转换为多列数据 如原始地址数据为:“广东省 深圳市 罗湖区 xxxx”, 此时如果我们需要按照省来…
pandas-corr
pandas的corr方法用于计算两个或多个Series或DataFrame之间的相关系数矩阵。
语法示例:
DataFrame.corr(methodpearson, min_periods1)参数说明:
method:相关系数的计算方法,可以是’pearson’、‘kendall’或’spearman’。默…
64_Pandas进行字符串和数字的相互转换和格式化
64_Pandas进行字符串和数字的相互转换和格式化
本文介绍如何在 pandas.DataFrame 和 pandas.Series 中进行字符串和数字之间的转换,以及如何更改字符串的格式。
下面对内容进行说明。
类型转换(强制转换):astype() 将数字转换为…

1.2Python 三方库的安装以 pandas 为例_python量化实用版教程(初级)
Python 三方库的安装以 pandas 为例
Python 拥有丰富的第三方库,可以方便地进行各种编程任务。以 pandas 库为例,下面是安装 pandas 库的步骤:
1. 打开命令行终端(Windows 用户可以使用 cmd,Linux 和 Ma…

32 数据分析(下)pandas介绍
文章目录 工具excelTableauPower Queryjupytermatplotlibnumpypandas数据类型Series基础的SeriesSeries的字典操作增加表的索引名字和表名字索引操作 DataFrameDataFrame 的基础使用DataFrame的列方法------理解DataFrame的行列方法------使用loc 与 iloc 对齐操作SeriesDataFr…
Pandas多列排序与多列排名
Pandas多列排序与多列排名 1、需求背景2、数据准备3、实验过程4、实现方式5、实验结论1、需求背景 工作中,我们可能会遇到这样的需求:按汇总指标A排名,指标A值相同,则按指标B排名
本文将通过一个小实验介绍如何使用Pandas在多个列上进行排序排名操作
2、数据准备
import…
Pandas 数据处理分析--SeriesDataFrame数据结构详解
Pandas 概述 Pandas 是一个开源的数据分析和数据处理库,是基于 NumPy 开发的。它提供了灵活且高效的数据结构,使得处理和分析结构化、缺失和时间序列数据变得更加容易。其在数据分析和数据处理领域广泛应用,在金融、社交媒体、科学研究等领域都有很高的使用率和广泛的应用场…
Pandas数据分析系列8-数据分组与聚合
Pandas 数据分组 在处理数据时,经常会需要对某一列或多列进行分组,分组后再对数据进行计算累加、最大值、最小值等。类似于Excel里的分类汇总,
在Pandas中,我们可以使用groupby 来完成这系列的分组统计。
语法结构:
dataframe.groupby(by=None, axis=0, level=None, …
SQL On Pandas最佳实践
SQL On Pandas最佳实践 1、PandaSQL1.1、PandaSQL简介1.2、Pandas与PandaSQL解决方案对比1.3、PandaSQL支持的窗口函数1.4、PandaSQL综合使用案例2、DuckDB2.1、DuckDB简介2.2、SQL操作(SQL On Pandas)2.3、逻辑SQL(DSL on Pandas)2.4、DuckDB on Apache Arrow2.5、DuckDB …
Pandas数据分析系列9-数据透视与行列转换
Pandas 数据透视表 当数据量较大时,为了更好的分析数据特征,通常会采用数据透视表。数据透视表是一种对数据进行汇总和分析的工具,通过重新排列和聚合原始数据,可以快速获得更全面的数据洞察。数据透视表在Excel中也是经常使用的一个强大功能,在Pandas模块,其提供了pivot…
python画气泡标尺图
目录 渐变气泡图彩色气泡图 在进行实验结果分析的时候,气泡标尺图能非常清晰对不同的结果进行多维度的比较,特别是在深度学习模型大小和精度进行比较的时候非常合适使用,以下是几个例子。 渐变气泡图
import seaborn as sns
import matplotl…
使用.bat脚本运行PPOCRLabel时只能使用管理员运行才能生效
1.使用.bat脚本运行PPOCRLabel
2.脚本中加命令使.bat运行以默认管理员身份进行
脚本示例:
CALL C:\Users\12073\anaconda3\Scripts\activate.bat C:\Users\12073\anaconda3
CALL conda activate yolo5
ppocrlabel --lang ch注意,第一行的路径为电脑中…
pandas教程:String Manipulation 字符串处理和正则表达式re
文章目录 7.3 String Manipulation(字符串处理)1 String Object Methods(字符串对象方法)2 Regular Expressions(正则表达式)3 Vectorized String Functions in pandas(pandas中的字符串向量化函…
pandas教程:Combining and Merging Datasets 合并数据集
8.2 Combining and Merging Datasets(合并数据集)
pandas里有几种方法可以合并数据:
pandas.merge 按一个或多个key把DataFrame中的行连接起来。这个和SQL或其他一些关系型数据库中的join操作相似。pandas.concat 在一个axis(轴…
pandas dataframe 统计某一列的值出现的次数并形成一列新的列
要统计Pandas DataFrame 中某一列的值出现的次数,并将结果形成一列新的列,可以使用value_counts()方法和map()函数。
下面是一个示例:
import pandas as pd# 创建一个DataFrame对象
df pd.DataFrame({A: [apple, banana, apple, orange, b…
怎么剔除掉六十岁(退休)以上的人(python自动化办公)
怎么剔除掉六十岁(退休)以上的人(python自动化办公)
需求分析:
1.本代码的要求是从表1中根据姓名合并表2
2.删除掉为空的人数 ,后面再合并
3.表格内的19971111,所以首先需要得到年份
4.找出大…
Pandas教程(非常详细)(第四部分)
接着Pandas教程(非常详细)(第一部分),继续讲述。
十九、Pandas groupby分组操作详解
在数据分析中,经常会遇到这样的情况:根据某一列(或多列)标签把数据划分为不同的组…
numpy教程:Array-Oriented Programming with Arrays 数组导向编程
文章目录 1 Expressing Conditional Logic as Array Operations (像数组操作一样表示逻辑条件)2 Mathematical and Statistical Methods (数学和统计方法)3 Methods for Boolean Arrays(布尔数组的方法)4 Sorting(排序)5 Unique a…
pandas笔记:读写excel
1 读excel
read_excel函数能够读取的格式包含:xls, xlsx, xlsm, xlsb, odf, ods 和 odt 文件扩展名。
支持读取单一sheet或几个sheet。
1.0 使用的数据 1.1 主要使用方法
pandas.read_excel(io, sheet_name0, header0, namesNone, index_colNone, usecolsNon…

英伟达发布RAPIDS cuDF框架 pandas在GPU上运行速度快了150倍
11月9日 消息:Nvidia 发布了一款名为 RAPIDS cuDF 的新版本,据称可以将 pandas 运行在 GPU 上,并且性能提升了150倍。pandas 是一款流行的基于 Python 的数据框架库,用于数据处理和分析。它的开源版本由 Wes McKinney 开发和发布&…
值之字符串(string)
一、创建字符串
"""单引号、双引号、三引号均能创建字符串"""
s kidney
s "kidney"
s """kidney"""
# 以上三种方法输出相同:
kidney"""将数值转为字符串""&q…

利用爬虫技术自动化采集汽车之家的车型参数数据
导语
汽车之家是一个专业的汽车网站,提供了丰富的汽车信息,包括车型参数、图片、视频、评测、报价等。如果我们想要获取这些信息,我们可以通过浏览器手动访问网站,或者利用爬虫技术自动化采集数据。本文将介绍如何使用Python编写…
[黑马程序员Pandas教程]——Pandas数据类型
目录:
学习目标一般类型类型转换 seriers.astype函数转换数据类型 astype函数使用示例astype函数使用的坑pd.to_numeric函数字符串转数字类型category分类类型 创建分类类型分类类型转换datetime时间类型 Python中的datetime类型读取数据时指定列为datetime类型pd.…
pandas教程:Data Aggregation 数据聚合
文章目录 10.2 Data Aggregation(数据聚合)1 Column-Wise and Multiple Function Application(列对列和多函数应用)2 Returning Aggregated Data Without Row Indexes(不使用行索引返回聚合数据) 10.2 Data…
Python的Pandas库(一)基础使用
Python开发实用教程
Pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。与NumPy十分类似的一点是,NumPy的核心是提供了数组结构,而Pandas 的核心是提供了两种数据结构: Series(一维数据)…
Pandas数据透视表:pivot_table()和crosstab()
Pandas使用pivot_table()方法和crosstab()方法实现透视表。
pivot_table()方法及参数
pivot_table()方法的语法格式如下: pandas.pivot_table(data, valuesNone, indexNone, columnsNone, aggfunc‘mean’, fill_valueNone, marginsFalse, dropnaTrue, margins_na…
pandas教程:Date and Time Data Types and Tools 日期和时间数据类型及其工具
文章目录 Chapter 11 Time Series(时间序列)11.1 Date and Time Data Types and Tools(日期和时间数据类型及其工具)1 Converting Between String and Datetime(字符串与时间的转换) Chapter 11 Time Serie…

pandas教程:USDA Food Database USDA食品数据库
文章目录 14.4 USDA Food Database(美国农业部食品数据库) 14.4 USDA Food Database(美国农业部食品数据库)
这个数据是关于食物营养成分的。存储格式是JSON,看起来像这样:
{"id": 21441, &quo…
Pandas在Excel同一个sheet里插入多个Dataframe和行
Pandas默认的to_excel是直接把完成的Datafrme写入一个sheet里,这并不能满足我们在一个sheet里插入多个Dataframe或多行的需求。为了实现插入多行或多Dataframe的目的,我们需要新建一个ExcelWriter对象,然后依次插入数据。
这里我们以插入2个Dataframe和三行单元格为例。
新…
pandas美化表格并导出到Excel
美化Excel表格用两种方式,一种是用Pandas自带的Dataframe.style类并通过CSS来改变样式,另外一种是通过Excel引擎来直接修改Excel样式。
Dataframe.style
Dataframe.style可以美化Pandas样式。导出样式到Excel的功能只有openpyxl渲染引擎支持。
大于平均数的单元格背景变色…
pandas数据结构Series, DataFrame
pandas数据结构Series, DataFrame
pandas的目的在于方便进行列操作,如果想遍历循环,就利用values值转换为numpy。
import pandas as pd
df pd.DataFrame({a:[10,20,30],b:[c,30,40]})
print(df.values)
print(df[a].values)[[10 c][20 30][30 40]][10…
pandas 基础操作3
数据删减
虽然我们可以通过数据选择方法从一个完整的数据集中拿到我们需要的数据,但有的时候直接删除不需要的数据更加简单直接。Pandas 中,以 .drop 开头的方法都与数据删减有关。
DataFrame.drop 可以直接去掉数据集中指定的列和行。一般在使用时&am…
15个Pandas代码片段助力数据分析
大家好,Python的Pandas库是数据分析的基本工具,提供了强大的数据操作和分析功能。本文将探讨15个高级Pandas代码片段,这些代码片段将帮助简化数据分析任务,并从数据集中提取有价值的见解。
1. 过滤数据
import pandas as pd# 创…

关于 Python 的最全面试题
1 Python的函数参数传递
看两个例子:
a 1
def fun(a):a 2
print a # 1a []
def fun(a):a.append(1)
print a # [1]所有的变量都可以理解是内存中一个对象的“引用”,或者,也可以看似c中void*的感觉。
这里记住的是类型是属于对象的,而…
4.Pandas行列进阶操作
1.新增列
1.1 assign
Pandas中提供的assign()函数不仅可以实现不该表原数据情况下新增列,而且可以同时新增多列,还可以配合链式操作使用一行代码完成多个新增列的创建,使得代码非常整洁。
函数
import numpy as np
import pandas as pd
d…
python pandas 数据预处理
pandas数据处理 相关知识DataFrame合并1. pandas.concat()2. DataFrame.append()3. DataFrame.merge()或者pd.merge()4. DataFrame.join() 第1关:数据读取与合并任务描述本关代码 第2关:数据清洗任务描述相关知识删除缺失值: dropna()检测缺失值 isnull(…
Python Pandas 如何增加/插入一列数据(第5讲)
Python Pandas 如何增加/插入一列数据(第5讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹…
python使用pandas实现dict与excel文件互转
一. dict 转 excel
import pandas as pd# data[{sku: 12001-0026, price: 166}, {sku: 12001-0027, price: 166}]
# rule {sku: 款号, price: 价格}
def dict2Xls(data, rule):downFile static/xls/datetime.datetime.now().strftime("H%M%S").xlsxfile_path pd.…

Dash中 基本的 callback 5
app.callback
在Dash中,app.callback 被用于创建交互性应用程序,它用于定义一个回调函数,该函数在应用程序中发生特定事件时被触发。回调函数可以修改应用程序的布局或更新图表等内容,从而实现动态交互。
下面是一个简单的 app.…

Pandas教程(一)—— 数据结构
前言 Pandas是贯穿数据分析的主要工具之一,它经常和其他数值计算工具一起使用(例如:Numpy、SciPy和matplotlib)。尽管pandas采用了很多NumPy的代码风格,但二者最大的区别是:pandas主要用于处理表格型或异质…
pandas教程:Interacting with Web APIs API和数据库的交互
文章目录 6.3 Interacting with Web APIs (网络相关的API交互)6.4 Interacting with Databases(与数据库的交互) 6.3 Interacting with Web APIs (网络相关的API交互)
很多网站都有公开的API,通过JSON等格式提供数据流。有很多方法可以访问这些API,这里…
pandas教程:Introduction to pandas Data Structures pandas的数据结构
文章目录 Chapter 5 Getting Started with pandas5.1 Introduction to pandas Data Structures1 Series2 DataFrame3 Index Objects (索引对象) Chapter 5 Getting Started with pandas
这样导入pandas:
import pandas as pde:\python3.7\lib\site-packages\numpy…
![[黑马程序员Pandas教程]——Pandas常用计算函数](https://img-blog.csdnimg.cn/1e41c64fc78b477a8017dea2ff84196b.png)
[黑马程序员Pandas教程]——Pandas常用计算函数
目录:
学习目标排序函数 sort_values函数rank函数常用聚合函数 corr函数计算数值列之间的相关性min函数计算最小值max函数计算最大值mean函数计算平均值std函数计算标准偏差quantile函数计算分位数sum函数求和count计算非空数据的个数其他常用计算函数 round改变浮…

python 运用pandas 库处理excel 表格数据
文章目录 读取文件查看数据数据选择数据筛选创建新列计算并总结数据分组统计 读取文件
Pandas 是一个强大的数据分析库,它提供了丰富的数据结构和数据分析工具,其中之一是用于读取不同格式文件的 read_* 函数系列。以下是一个简单介绍如何使用 Pandas 读…
![解决docker使用pandarallel报错OSError: [Errno 28] No space left on device](https://img-blog.csdnimg.cn/0e7b6899d68e4b0d83c694994f21d321.png)
解决docker使用pandarallel报错OSError: [Errno 28] No space left on device
参考:https://github.com/nalepae/pandarallel/issues/127
在使用pandarallel报错OSError: [Errno 28] No space left on device,根据上述issue发现确实默认使用的MEMORY_FS_ROOT为 /dev/shm,而在docker环境下这个目录大小只有64M࿰…
pandas教程:Advanced GroupBy Use 高级GroupBy用法
文章目录 12.2 Advanced GroupBy Use(高级GroupBy用法)1 Group Transforms and “Unwrapped” GroupBys(组变换和无包装的GroupBy)2 Grouped Time Resampling(分组时间重采样) 12.2 Advanced GroupBy Use&a…
pandas教程:Creating Model Descriptions with Patsy 利用Patsy创建模型描述
文章目录 13.2 Creating Model Descriptions with Patsy(利用Patsy创建模型描述)1 Data Transformations in Patsy Formulas(Patsy公式的数据变换)2 Categorical Data and Patsy(Categorical数据和Patsy) 1…
编码数据未来:Python数据科学的现代工具箱
数据处理和科学计算: Python中的利器
前言
在当今信息爆炸的时代,数据已成为决策和创新的驱动力。对于数据的处理和科学计算变得至关重要,尤其是在Python生态系统中,三个强大的库——numpy、scipy和pandas,为数据科学家和工程师…
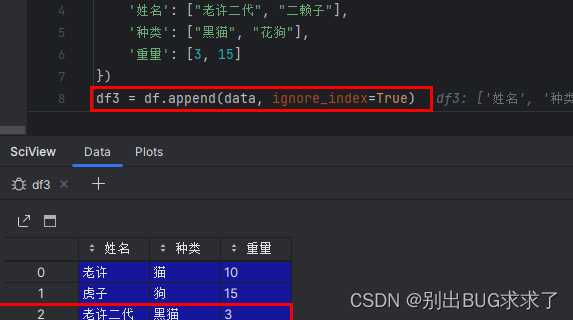
python的pandas中如何在dataframe中插入一行或一列数据?
dataframe类型是如何插入一行或一列数据的呢?这个需求在本文中将会进行讨论。相比较ndarray类型的同样的“数据插入”需求,dataframe的实现方式,则不是很好用。本文以一个dataframe类型变量为例,测试插入一行数据或者一列数据的方…
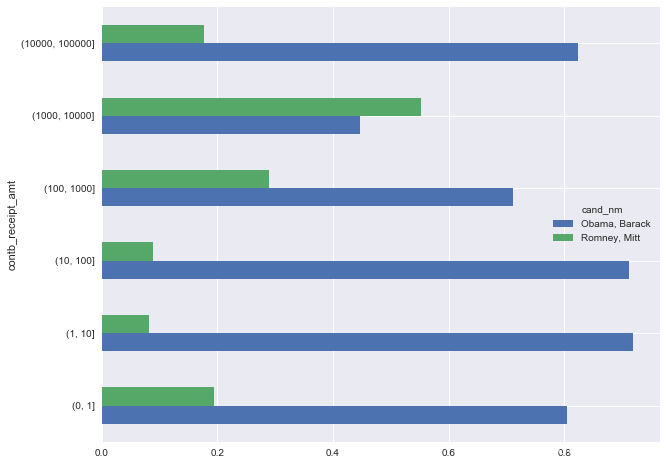
pandas教程:2012 Federal Election Commission Database 2012联邦选举委员会数据库
文章目录 14.5 2012 Federal Election Commission Database(2012联邦选举委员会数据库)1 Donation Statistics by Occupation and Employer(按职业与雇主划分的捐赠数据)2 Bucketing Donation Amounts(桶捐赠额&#x…
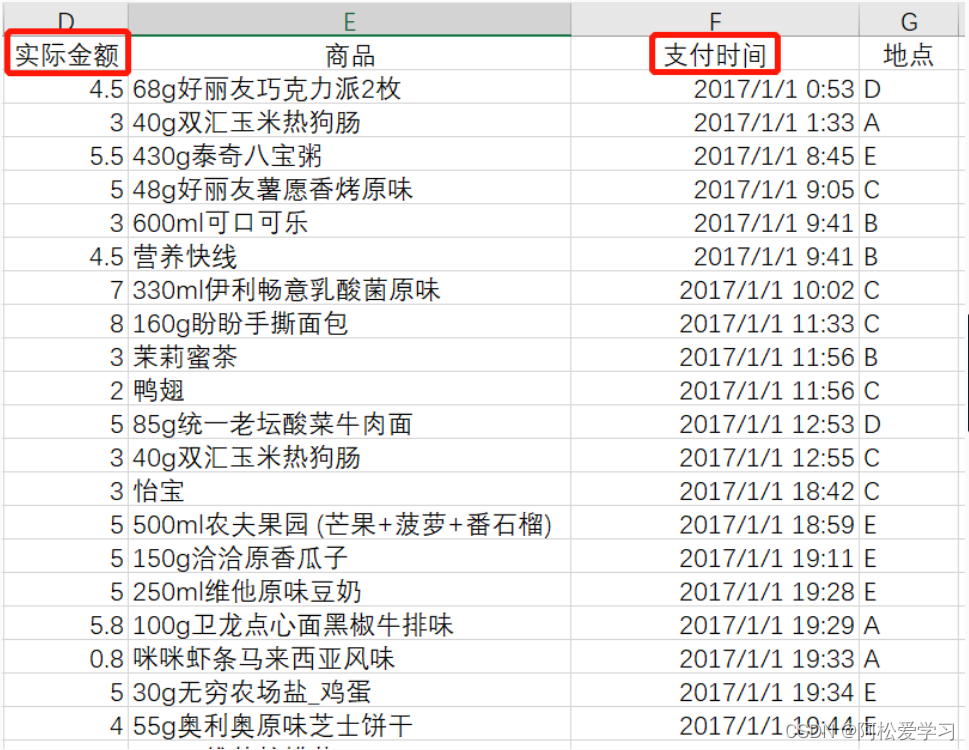
Seaborn数据可视化综合应用Basemap和Seaborn在线闯关_头歌实践教学平台
Seaborn数据可视化综合应用Basemap和Seaborn 第1关 Seaborn第2关 Seaborn图形介绍第3关 Basemap 第1关 Seaborn
任务描述 本关任务:编写一个绘制每个月销售总额的折线图。 编程要求 本关的编程任务是补全右侧上部代码编辑区内的相应代码,根据输入文件路…
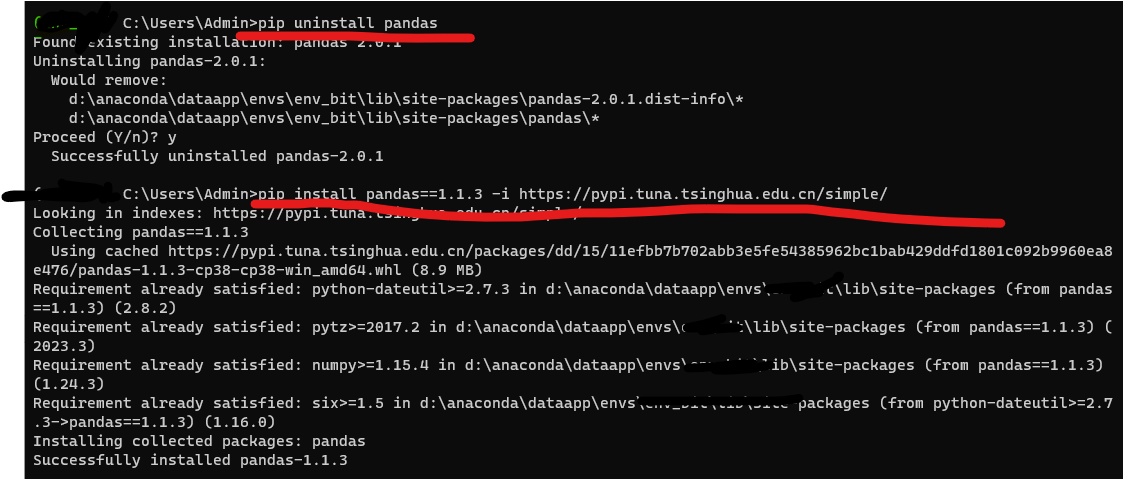
module pandas has no attribute Int64Index
pandas报错 pandas 报错解决 pandas 报错
module pandas has no attribute Int64Index
解决
将pandas将为1.1.3版本即可pip uninstall pandas
pip install pandas1.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple/
9.2 Plotting with pandas and seaborn(用pandas和seaborn绘图)
9.2 Plotting with pandas and seaborn(用pandas和seaborn绘图)
matplotlib是一个相对底层的工具。pandas自身有内建的可视化工具。另一个库seaborn则是用来做一些统计图形。 导入seaborn会改变matplotlib默认的颜色和绘图样式,提高可读性和美感。即使不适用seaborn的API,…

Python学习之pandas模块duplicated函数的常见用法
pandas库中的duplicate()函数常用于查找和处理数据中的重复项。 以下是duplicate()函数的常见用法: 查找重复项:使用duplicate()函数可以查找数据中的重复项。例如,df.duplicated()可以返回一个布尔数组,指示每一行是否是重复项。…

Python通过Flask+pyecharts对房地产数据实现数据分析结果Web可视化(二)
一、背景 在Python通过pyecharts对爬虫房地产数据进行数据可视化分析(一)基础上添加Flask框架实现web可视化功能,把生成的所有图表生成一份完整的数据分析报告,这样就可以方便直接在网页上看到整体的数据分析可视化结果。 二、步骤…
安装pandas报错
报错信息:
C:\Users\Jordan>pip install pandas
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple/
Collecting pandasUsing cached https://pypi.tuna.tsinghua.edu.cn/packages/3a/6e/6c9c197ec2da861ea8c9c6848f0f887b7563f16e607bc6a35506af6…
Pandas分组函数和聚合函数
pandas中的分组函数groupby()可以完成各种分组操作,聚合函数agg()可以将多个函数的执行结果聚合到一起,这两类函数经常在一起使用。
groupby用法和参数介绍
groupby(self, byNone, axis0, levelNone, as_indexTrue, sortTrue, group_keysTrue, squeeze…
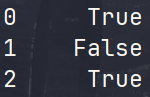
力扣:182. 查找重复的电子邮箱(Python3)
题目: 表: Person ----------------------
| Column Name | Type |
----------------------
| id | int |
| email | varchar |
----------------------
id 是该表的主键(具有唯一值的列)。
此表的每一行都包含一封电子…
python如何合并或拆分excell单元格
#codinggbk
import openpyxl# 打开Excel文件
workbook openpyxl.load_workbook(D:\Desktop\二转\\11.xlsx)# 选择第一个工作表
sheet workbook.worksheets[0]
print(sheet)
# 创建一个新的工作表用于存储复制后的数据
new_sheet workbook.create_sheet(Copied)# 遍历每一行
…
获取pandas中的众数
pandas.DataFrame 也有一个 mode() 方法。 以下面的 pandas.DataFrame 为例。
df pd.DataFrame({‘col1’: [‘X’, ‘X’, ‘Y’, ‘X’], ‘col2’: [‘X’, ‘Y’, ‘Y’, ‘X’]}, index[‘row1’, ‘row2’, ‘row3’, ‘row4’]) print(df)
col1 col2
row1 X X
row2…
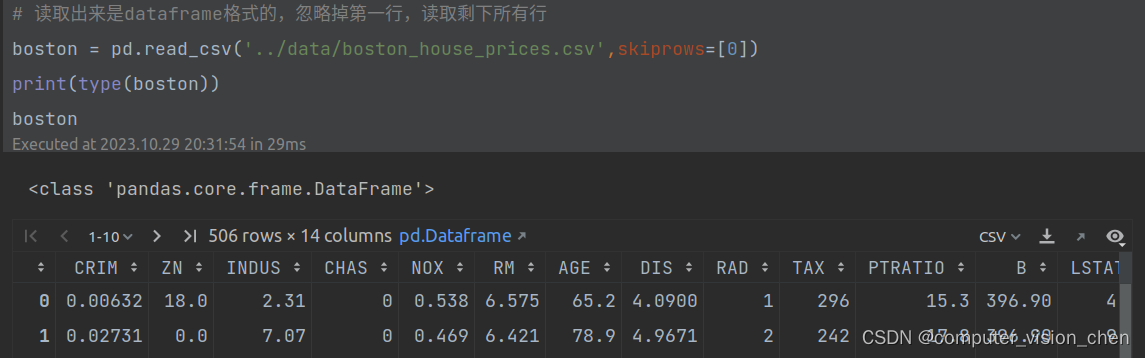
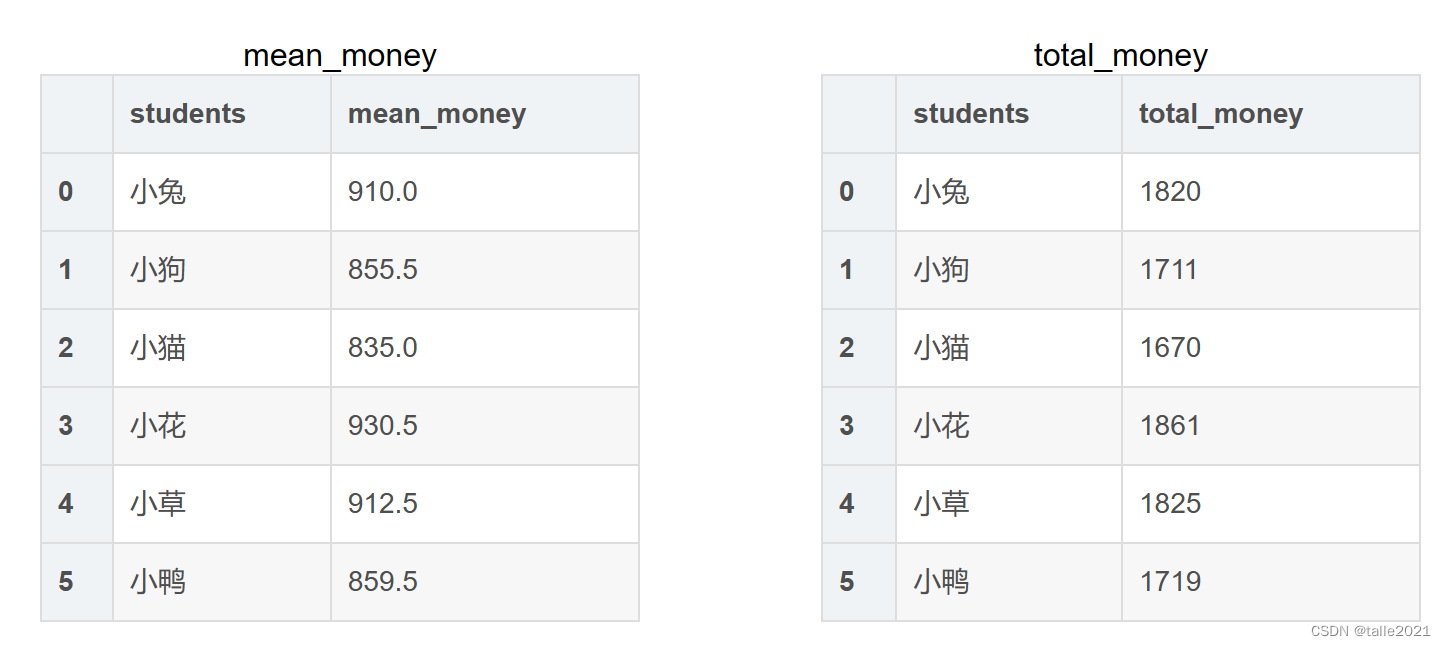
【pandas技巧】group by+agg+transform函数
目录
1. group by单个字段单个聚合
2. group by单个字段多个聚合
3. group by多个字段单个聚合
4. group by多个字段多个聚合
5. transform函数 studentsgradesexscoremoney0小狗小学部female958441小猫小学部male938362小鸭初中部male838543小兔小学部female909314小花小…
(四) Python Pandas入门
一、介绍 Pandas是Python中一个强大的数据处理库,它提供了许多功能强大的数据结构和数据分析工具。在本文中,我们将介绍Pandas的基本概念和如何使用它生成一个包含今天到未来20个工作日的日期列表的Excel文件。
Pandas提供了大量的数据结构和数据分析工…
![[黑马程序员Pandas教程]——Pandas数据结构](https://img-blog.csdnimg.cn/99a2be73281c49c49a642fc3437496cb.png)
[黑马程序员Pandas教程]——Pandas数据结构
目录:
学习目标认识Pandas中的数据结构和数据类型Series对象通过numpy.ndarray数组来创建通过list列表来创建使用字典或元组创建s对象在notebook中不写printSeries对象常用API布尔值列表获取Series对象中部分数据Series对象的运算DataFrame对象创建df对象DataFrame…
python imblearn教程:不平衡数据处理
文章目录 imblearn介绍常见方法数据处理实例演示采样函数imblearn介绍
官方教程:https://imbalanced-learn.org/stable/references/index.html
常见方法
不平衡数据的处理主要分为在数据层面的处理和在算法层面的改进,因为两者互不影响,所以也有结合两者的方法。首先进行…

Python爬虫教程27:秀啊!用Pandas 也能爬虫??
说到爬虫,大家可能都知道requests、re、scrapy、selenium等等一些工具库。虽然它低调,但功能非常强大,用于抓取Table表格型数据时,简直是个神器,没有必要去F12研究HTML页面结构甚至写正则表达式解析字段。
#我的Pytho…
selenium下载安装对应的chromedriver并执行
文章目录 selenium对应版本chrome驱动下载114以及之前的chrome版本119/120/121的chrome版本 chromedriver安装执行selenium代码 selenium
Selenium是广泛使用的模拟浏览器运行的库,它是一个用于Web应用程序测试的工具。 Selenium测试直接运行在浏览器中,…

Pandas教程06:DataFrame.merge数据的合并处理
DataFrame.merge() 是 pandas 库中用于合并两个DataFrame数据的方法。该方法主要用于根据一个或多个键(键可以是列名或索引)将两个 DataFrame 连接在一起,这个过程类似于 SQL 中的 JOIN 操作。
#我的Python教程
#微信公众号:wdPy…
Pandas数据清洗_Python数据分析与可视化
Pandas数据清洗 删除缺失值检测缺失值填充缺失值拉格朗日插值线性插值 在处理数据的时候,需要对数据进行一个清洗过程。清洗操作包括:空白行的删除、数据完整性检验、数据填充、插值等内容。
下面是数据清洗过程中使用的具体方法
删除缺失值
DataFram…
入门指南:介绍Python库——Pandas
个人网站
本文首发于公众号小肖学数据分析
Pandas是一个功能强大、灵活易用的Python数据处理库。
无论你是数据分析师、数据科学家还是Python初学者,掌握Pandas都将为你提供高效、便捷的数据处理和分析能力。
本文将为你详细介绍Pandas的基本概念、常用功能和使…
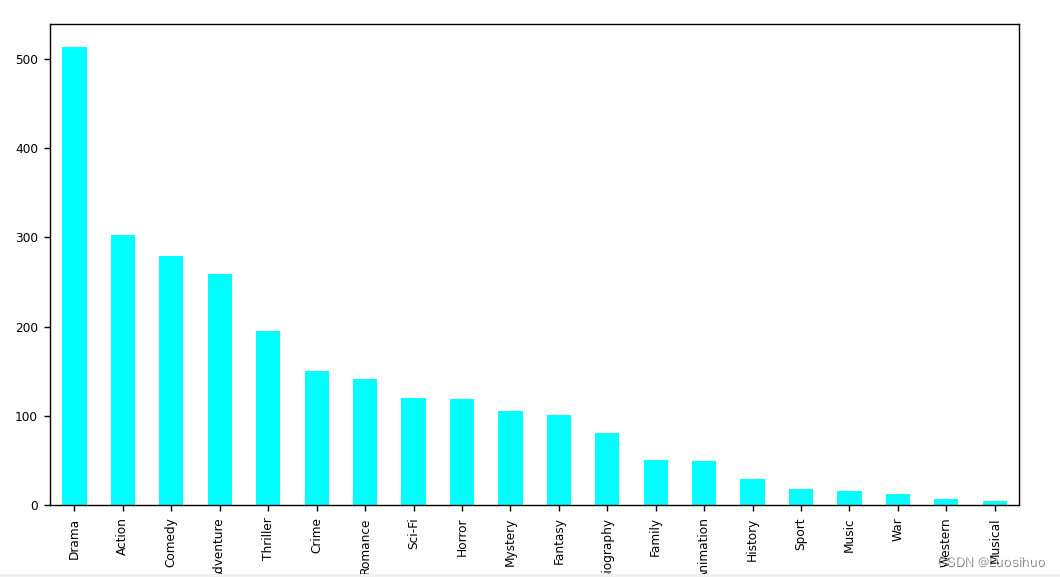
学习Pandas 二(Pandas缺失值处理、数据离散化、合并、交叉表与透视表、分组与聚合)
文章目录 六、高级处理-缺失值处理6.1 检查是否有缺失值6.2 缺失值处理6.3 不是缺失值NaN,有默认标记的 七、高级处理-数据离散化7.1 什么是数据的离散化7.2 为什么要离散化7.3 如何实现数据的离散化 八、高级处理-合并8.1 pc.concat实现合并,按方向进行…
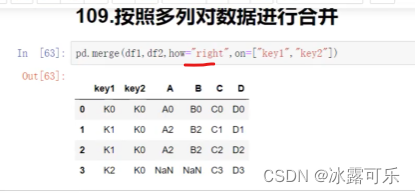
Python pandas数据分析
Python pandas数据分析:
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle,尤其…
csv、pandas、numpy写文件的区别
写入文件:
import csv
# 写入数据到 CSV 文件
with open(data_csv.csv, w, newline) as csvfile:writer csv.writer(csvfile)writer.writerow([1, 2, 3, 4])1,2,3,4 import pandas as pd
# 写入数据到 Pandas DataFrame
data_pd pd.DataFrame({col: [1, 2, 3, 4]…
世界杯可视化part1
前言:针对阿里天池赛的世界杯可视化,表的内容我不赘述了,既然能查到这里肯定知道是什么,我就讲一下第一位大佬的代码,反正我是啥也不懂,我直接抄他的进行复现
%matplotlib inline
import numpy as np
impo…
从网页抓取数据到Pandas运算,再到MySQL的大数据处理---提效率篇
前言:
在处理网络数据时,从网页抓取表格数据并分析它们是一项常见任务。这篇文章介绍一种有效的工作流程,包含数据抓取、使用Pandas进行逻辑运算,以及对于大量数据运用MySQL的策略。 抓取并保存数据
当从网页上抓取数据时,直接进…

Python (十六) pandas(四)
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…
深入了解Pandas的数据类型
大家好,Pandas是一个功能强大的数据处理和分析库,它提供了丰富的数据类型,使得数据操作更加灵活和高效。本文我们将深入了解Pandas的数据类型,包括Series和DataFrame。
1.Series
Series是Pandas中最基本的数据类型,它…
使用pandas处理数据的一些总结
1、替换换行符等特殊符号
df df.replace({None: "", np.nan: "", "\t": "", "\n": "", "\x08": ""}, regexTrue)
2、清除DataFrame中所有数据的左右空格,字符串中间空格不会清…
大数据(十一):概率统计基础
专栏介绍
结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来!
全部文章请访问专栏:《Python全栈教…

pandas将dataframe列中的list转换为多列
在应用机器学习的过程中,很大一部分工作都是在做数据的处理,一个非常常见的场景就是将一个list序列的特征数据拆成多个单独的特征数据。
比如数据集如下所示:
data [[John, 25, Male,[99,100,98]],[Emily, 22, Female,[97,99,98]],[Michae…
【Python】人工智能-机器学习——不调库手撕贝叶斯分类问题
1. 作业内容描述
1.1 背景
数据集大小150该数据有4个属性,分别如下 Sepal.Length:花萼长度(cm)Sepal.Width:花萼宽度单位(cm)Petal.Length:花瓣长度(cm)Petal.Width:花瓣宽度(cm)category:类别࿰…
pandas超出print限制时如何查看完整dataframe
当设置了 pd.set_option(display.max_rows, None),我们期望能够打印出数据框的所有行。然而,在某些情况下,即使设置了该选项,仍然无法完全打印出所有行的内容。这是因为数据量可能超出了系统的内存或显示限制。
为了解决这个问题…
【用pandas,写入内容到excel工作表的问题】
用pandas的话(如下面代码所示),写入内容到excel工作表,有几个问题: 1、运行的之前,excel需要先关闭。
2、如果Sheet2存在,那么就会报错。如果if_sheet_exists‘replace’,那么就会把…
用python合并文件夹中所有excel表
你可以使用Python的pandas库和glob库来完成这个任务。以下是一个示例代码,它将合并指定文件夹中所有的Excel文件: python复制代码
import pandas as pd import glob # 指定文件夹路径 folder_path path_to_your_folder # 获取所有Excel文件 excel_file…
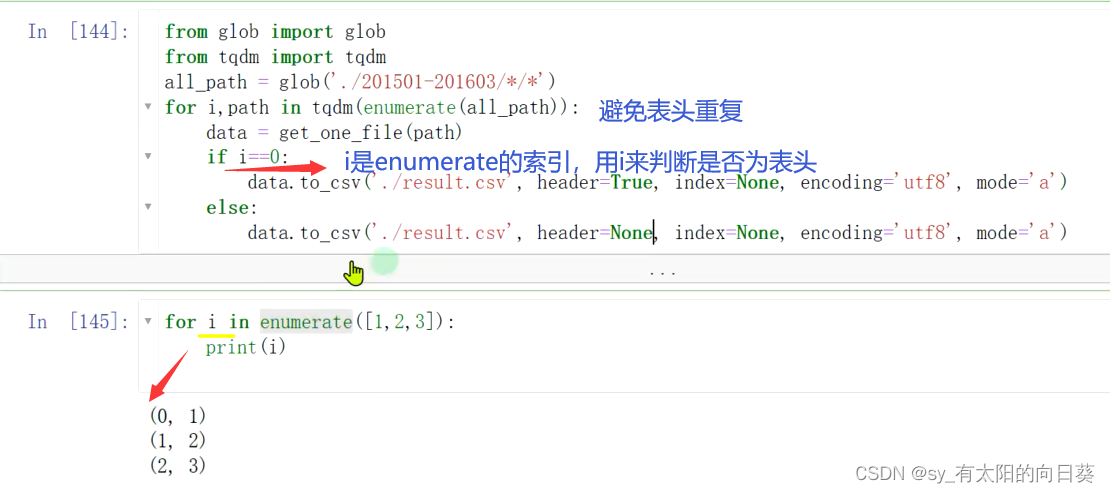
数据分析——火车信息
任务目标
任务
1、整理火车发车信息数据,结果的表格形式为: 2、并输出最终的发车信息表
难点
1、多文件 一个文件夹,多个月的发车信息,一个excel,放一天的发车情况
2、数据表的格式特殊 如何分析表是一个难点
数…
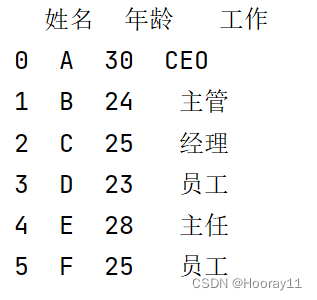
python_数据可视化_pandas_导入excel数据
目录
1.1导入库
1.2读取excel文件
1.3读取excel,指定sheet2工作表
1.4指定行索引
1.5指定列索引
1.6指定导入列
案例速览: 1.1导入库
import pandas as pd
1.2读取excel文件 pd.read_excel(文件路径) data pd.read_excel(D:/desktop/TestExcel…
Pandas实战100例 | 案例 8: 数据合并 - 使用 `concat`、`merge` 和 `join`
案例 8: 数据合并 - 使用 concat、merge 和 join
知识点讲解
在数据分析中,经常需要将不同的数据集合并在一起。Pandas 提供了 concat, merge, 和 join 几种方法来实现数据的合并。
concat: 用于沿一定轴向将多个对象堆叠在一起。可以用于简单的数据合并操作&…
Pandas实战100例 | 案例 13: 数据分类 - 使用 `cut` 对数值进行分箱
案例 13: 数据分类 - 使用 cut 对数值进行分箱
知识点讲解
在数据分析中,将连续的数值数据分类成不同的区间(或“分箱”)是一种常见的做法。Pandas 提供了 cut 函数,它可以根据你指定的分箱边界将数值数据分配到不同的类别中。 …

pandas详细笔记
一:什么是Pandas from matplotlib import pyplot
import numpy as np
import pandas as pdarange np.arange(1, 10, 2)
series pd.Series(arange,indexlist("ABCDE"))
print(series)二:索引 三:切片 位置索引切片(左闭…
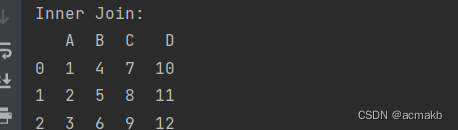
Pandas中concat的用法
Pandas中concat的用法
pd.concat 是 pandas 库中的一个函数,用于将多个 pandas 对象(如 Series、DataFrame)沿指定轴进行合并连接。
pd.concat(objs, axis0, joinouter, ignore_indexFalse, keysNone, levelsNone, namesNone, verify_in…
SpringMVC之视图和RESTful
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。各位小伙伴,如果您: 想系统/深入学习某技术知识点… 一个人摸索学习很难坚持,想组团高效学习… 想写博客但无从下手,急需…
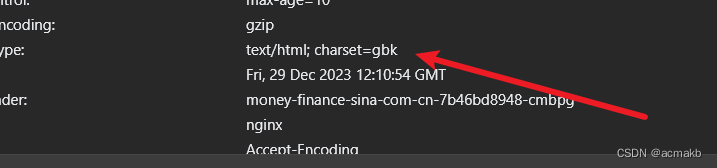
利用Pandas进行高效网络数据获取
利用Pandas进行高效网络数据获取
背景:
最近看到一篇关于使用Pandas模块进行爬虫的文章,觉得很有趣,这里为大家详细说明。
基础铺垫:
pd.read_html pandas 库中的一个函数,用于从 HTML 页面中读取表格数据并…
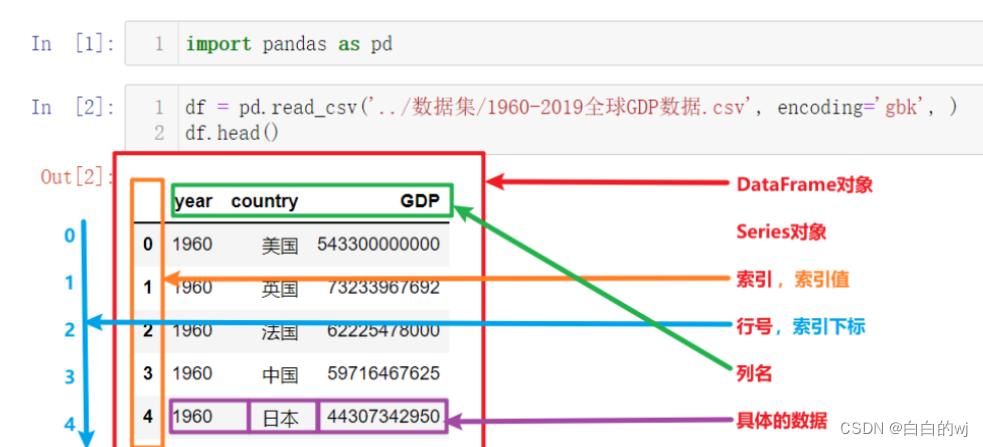
2023.12.30 Pandas操作
目录 1. pandas基础 1.1 pandas的基本介绍 1.2 pandas基础使用 2. pandas的数据结构
2.1 series对象 2.2 使用列表,自定义索引,字典,元组方式创建series对象
2.3 Series对象常用API
2.4 Series 对象的运算 1. pandas基础 1.1 pandas的基本介绍
Python在数据处理上独步天下…

Python入职某新员工大量使用Lambda表达式,却被老员工喷是屎山
Python中Lambda表达式是一种简洁而强大的特性,其在开发中的使用优缺点明显,需要根据具体场景权衡取舍。 Lambda表达式的优点之一是它的紧凑语法,适用于一些短小而简单的函数。这种形式使得代码更为精炼,特别在一些函数式编程场景中…
pandas的drop_duplicates无法去重问题
之前没研究过pandas的去重方法,今天用了一下,发现这个方法并不是那么好用,我的需求是去除所有列的重复值,并保留第一个重复的值,按我的想法应该是下面这样写
import pandas as pd
import numpy as npdf1 pd.DataFram…
深入Pandas:数据分析的强大工具
文章目录 引言Pandas简介Pandas的核心功能实战示例:数据分析与可视化示例目的环境需求示例数据集示例过程及结果源代码 结语 引言
在当今快速发展的数据科学领域,Python凭借其强大的库生态系统,特别是像Pandas这样的库,已成为数据…
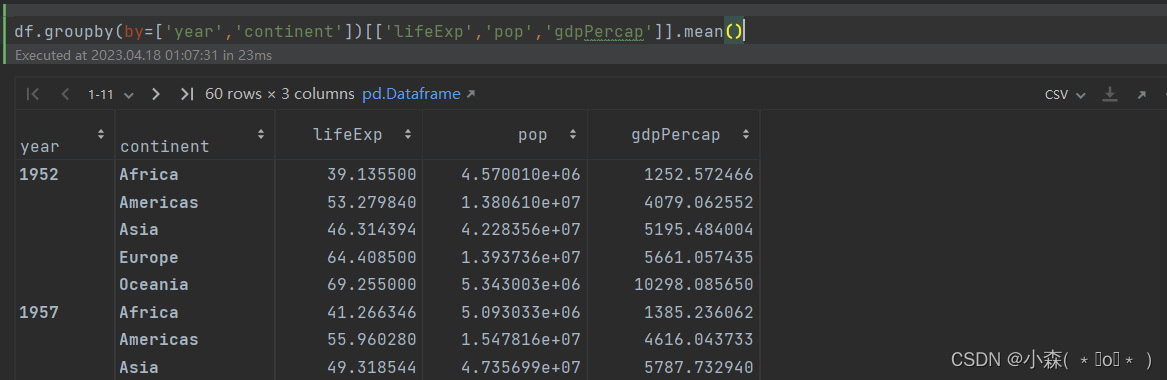
DataFrame的使用
查看数据类型及属性
# 查看df类型
type(df)
# 查看df的shape属性,可以获取DataFrame的行数,列数
df.shape
# 查看df的columns属性,获取DataFrame中的列名
df.columns
# 查看df的dtypes属性,获取每一列的数据类型
df.dtypes
df.i…
Python 读取和写入包含中文的csv、xlsx、json文件
背景
最近在做数据的训练,经常需要读取写入csv、xlsx、json文件来获取数据,在这里做简单总结记录。
ps: 读取和写入中文文件时,需要确保文件的编码格式是正确的。通常情况使用UTF-8编码格式。如果使用其他编码格式可能会导致读取或写入时出…
pythonPandas一: 数据结构和基本操作
让我们通过几个案例来学习Pandas中Series和DataFrame的创建、访问、修改等基本操作,以及如何选择、过滤、排序和合并数据,以及处理缺失值和重复数据。
首先,我们将创建一个包含学生信息的DataFrame:
import pandas as pddata {…
数据分析-Pandas如何选择数据子集
数据分析-Pandas如何选择数据子集
Dataframe的数据中,选择某一列,某一行,或者某个子区域,该怎么办呢?
python数据分析-数据表读写到pandas
经典算法-遗传算法的python实现
经典算法-遗传算法的一个简单例子
大模型…
Polars使用指南(一)
pandas是Python数据处理中非常经典的一个科学计算库,表形式的数据结构、丰富的API和灵活的编程语法使得pandas成为最常用的的数据分析工具。但是pandas也有一个最致命的缺陷,就是效率问题,尤其是不支持并行计算。pandas2在性能方面有了极大的…
Pandas实战100例 | 案例 20: 日期时间运算
案例 20: 日期时间运算
知识点讲解
Pandas 提供了强大的日期和时间处理功能。你可以从 datetime 类型的列中提取出年份、月份、日、星期等信息,也可以进行日期时间的加减运算。 提取日期时间信息: 使用 dt 访问器,你可以从 datetime 类型的列中提取出年份 (year)、月份 (mo…
1、Pandas 数据结构:从 Series 到 DataFrame
目录 Series
创建 Series
Series 索引和选择
DataFrame
创建 DataFrame
DataFrame 索引和选择
DataFrame 操作和转换
数据结构转换 Series Series 是 Pandas 中的一维数组形式的数据结构,它可以包含任何数据类型(整数、字符串、浮点数、Python对象…
从数据角度分析年龄与NBA球员赛场表现的关系【数据分析项目分享】
好久不见朋友们,今天给大家分享一个我自己很感兴趣的话题分析——NBA球员表现跟年龄关系到底大不大?数据来源于Kaggle,感兴趣的朋友可以点赞评论留言,我会将数据同代码一起发送给你。 目录 NBA球员表现的探索性数据分析导入Python…
Pandas实战100例 | 案例 43: 数据排序
案例 43: 数据排序
知识点讲解
在数据分析中,对数据进行排序是一项基本且常见的任务。Pandas 提供了 sort_values 方法,用于根据一列或多列的值对数据进行排序。
按一列排序: 使用 sort_values 方法并指定 by 参数,可以按照某一列的值进行…
Pandas实战100例 | 案例 26: 检测异常值
案例 26: 检测异常值
知识点讲解
在数据分析中,检测和处理异常值(或离群值)是一个重要的步骤。异常值可能会影响数据的整体分析。一种常用的方法是使用四分位数和四分位数间距(IQR)来识别异常值。
四分位数和 IQR: …

数据分析-Pandas如何用图把数据展示出来
数据分析-Pandas如何用图把数据展示出来
俗话说,一图胜千语,对人类而言一串数据很难立即洞察出什么,但如果展示图就能一眼看出来门道。数据整理后,如何画图,画出好的图在数据分析中成为关键的一环。
数据表ÿ…
Pandas实战100例 | 案例 18: 列操作 - 重命名、删除和重新排序列
案例 18: 列操作 - 重命名、删除和重新排序列
知识点讲解
在处理 DataFrame 时,经常需要对列进行各种操作,如重命名列、删除列或重新排序列。Pandas 提供了简洁的方法来执行这些任务。
重命名列: 使用 rename 方法可以改变 DataFrame 中一个或多个列的…
Pandas实战100例 | 案例 23: 处理空值
案例 23: 处理空值
知识点讲解
处理空值是数据清洗过程中的一个关键步骤。Pandas 提供了多种方法来检测、填充和删除空值。
检测空值: 使用 isnull 方法可以检测 DataFrame 中的空值。填充空值: 使用 fillna 方法可以填充空值。删除包含空值的行或列: 使用 dropna 方法可以删…
Pandas实战100例 | 案例 17: 处理重复数据 - 删除重复行
案例 17: 处理重复数据 - 删除重复行
知识点讲解
在数据分析过程中,处理重复的记录是一个常见的任务。Pandas 提供了方便的方法来删除重复行,保证数据的准确性和可靠性。
删除所有列重复的行: 使用 drop_duplicates() 方法可以删除 DataFrame 中所有列…
python中none的替换方法:pandasnumpy
none的替换方法:
1.pandas
# 将缺失的id值替换为None
merged_df[id].fillna(None, inplaceTrue)
#这行代码使用了Pandas库中的fillna方法,对DataFrame中的id列进行了填充操作。具体来说,它将该列中的缺失值用字符串None进行填充,…
pythonPandas三: 数据清洗和预处理
让我们通过几个案例来学习如何使用Pandas进行数据清洗和预处理,包括处理缺失值、异常值,进行数据转换和规范化,以及处理重复数据等操作。 处理缺失值: # 创建包含缺失值的DataFrame
data {姓名: [张三, 李四, None, 赵六],年龄: …
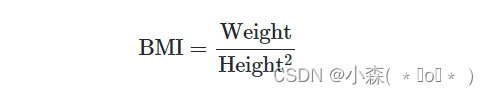
pandas分组聚合转换
分组的一般模式
分组操作在日常生活中使用极其广泛:
依据性别性别分组,统计全国人口寿命寿命的平均值平均值依据季节季节分组,对每一个季节的温度温度进行组内标准化组内标准化
从上述的例子中不难看出,想要实现分组操作&#…
Pandas实战100例 | 案例 55: 应用条件
案例 55: 应用条件
知识点讲解
在数据处理过程中,有时需要根据条件对数据进行转换或计算。Pandas 的 apply 方法允许你对 DataFrame 的每一行或列应用一个自定义函数,实现复杂的逻辑。
应用条件: 使用 apply 方法结合 lambda 函数,可以根据…
69_Pandas.DataFrame获取行号和列号
69_Pandas.DataFrame获取行号和列号
将讲解如何从pandas.DataFrame的行名和列名中获取行号和列号,以及如何从列元素的值中获取行名和行号。 下面对内容进行说明。
根据行名和列名获取行号和列号 get_loc() 方法 当行名和列名重复时 列表索引、列 从列元素值获取行…
0、Pandas微课数据集说明
Pandas数据集说明
188万起美国森林火灾
24年地理参考的火灾记录
最后更新:4年前(版本2) 关于这个数据集 数据集为sqlite数据库文件 夸克网盘下载地址:链接:https://pan.quark.cn/s/160d21814154 提取码:qgDj 夸克网盘csv下载地址:本节夸克网盘数据集链接:https://pa…
【机器学习】快速入门!关于 Pandas 库的简介和常用方法整理
Pandas Pandas 简介1. 数据加载和存储加载数据:存储数据: 2. 数据清洗3. 数据统计和汇总4. 数据选择和过滤5. 数据合并和连接6. 时间序列处理创建时间序列数据:索引和选择:时间序列分析:时间序列可视化: 7.…
pythonPandas二:数据读取与写入
Pandas提供了各种函数和方法来实现数据读取和写入的操作。下面我将详细介绍Pandas中常用的数据读取和写入的方法。
数据读取: 从CSV文件读取:可以使用pd.read_csv()函数来读取CSV文件,并将其转换为DataFrame对象。 df pd.read_csv(data.csv…
pandas逐行追加到csv的正确方式
pandas逐行追加到csv的正确方式:
# ---encoding:utf-8---
# Author : STZZ AIOT TLZS
# Email :stzzaiottlzsgmail.com
# Site : AIOT
# File : 逐行追加到csv文件.py
# Software: PyCharm
import pandas as pddef append_to_csv():data_df p…
AI应用开发-python实现redis数据存储
AI应用开发相关目录 本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧 适用于具备一定算法及Python使用基础的人群
AI应用开发流程概…

【python数据分析基础】—dataframe中index的相关操作(添加、修改index的列名、修改index索引值等)
文章目录 前言一、添加、修改index的列名二、修改index索引值 前言
本文主要讲dataframe结构中index的相关操作,index相当于是数据表的行。 一、添加、修改index的列名
新建一个dataframe表,我们可以自定义index的值,如下:
imp…
71_Pandas.DataFrame排名
71_Pandas.DataFrame排名
使用rank()方法对pandas.DataFrame和pandas.Series的行/列进行排名。
sort_values() 是一种按升序或降序对 pandas.DataFrame 列和 pandas.Series 进行排序的方法,但rank() 返回每个元素的排名而不对数据进行排序。
请参阅下面的文章了解…
pandas笔记:找出在一个dataframe但不在另一个中的index
1 问题描述
假设我们有两个dataframe(这一段代码)来自transbigdata 笔记:官方文档案例1(出租车GPS数据处理)-CSDN博客
data tbd.clean_outofshape(data, sz, col[Lng, Lat], accuracy500)
data data2 tbd.clean_ta…
Polars使用指南(二)
在上一篇文章中,我们介绍了Polars的优势和Polars.Series的常用API,本篇文章我们继续介绍Polars.Series的扩展API。
对于一些特殊的数据类型,如 pl.Array、list、str 等,Polars.Series 提供了基于属性的直接操作API,如…
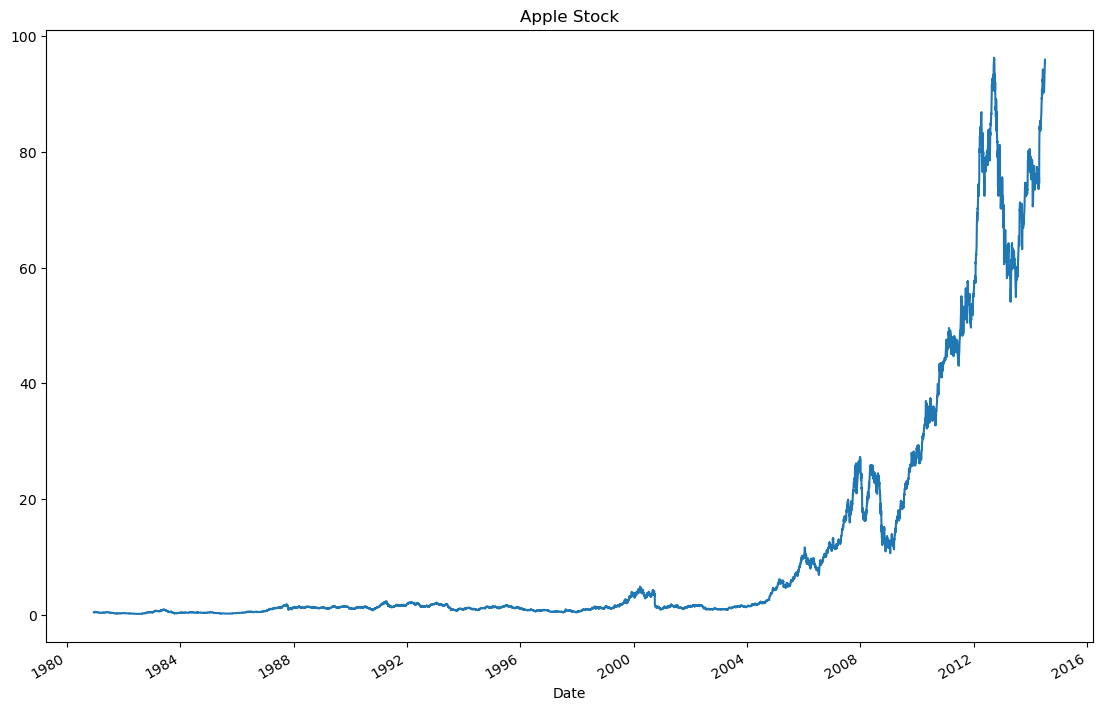
Pandas十大练习题,掌握常用方法
文章目录 Pandas分析练习题1. 获取并了解数据2. 数据过滤与排序3. 数据分组4. Apply函数5. 合并数据6. 数据统计7. 数据可视化8. 创建数据框9. 时间序列10. 删除数据 代码均在Jupter Notebook上完成 Pandas分析练习题 数据集可从此获取: 链接: https://pan.baidu.co…
Pandas实战100例 | 案例 5: 数据过滤 - 使用条件过滤数据
案例 5: 数据过滤 - 使用条件过滤数据
知识点讲解
数据过滤是数据分析中的常见需求,它允许你基于一定条件从数据集中筛选出感兴趣的数据子集。
示例代码
基于单个条件过滤
# 筛选出某列值大于特定值的所有行
filtered_data df[df[Column] > 10]
print(filt…
传送门:【巴尔加瓦算法图解】所有文章
文章巴尔加瓦算法图解——第一章 算法简介巴尔加瓦算法图解——第二章 选择排序巴尔加瓦算法图解——第三章 递归巴尔加瓦算法图解——第四章 快速排序巴尔加瓦算法图解——第五章 散列表巴尔加瓦算法图解——第六章 广度优先搜索巴尔加瓦算法图解——第七章 狄克斯特拉算法巴尔…

政安晨:政安晨:机器学习快速入门(三){pandas与scikit-learn} {模型验证及欠拟合与过拟合}
这一篇中,咱们使用Pandas与Scikit-liarn工具进行一下模型验证,之后再顺势了解一些过拟合与欠拟合,这是您逐渐深入机器学习的开始! 模型验证
评估您的模型性能,以便测试和比较其他选择。
在上一篇中,您已经…
sklearn.preprocessing 特征编码汇总
文章目录 常见特征种类one-hot编码特征哈希(`Feature hashing`)基于统计的类别编码对循环特征的编码目标编码(Target encoding)K折目标编码(K-Fold Target encoding)用于数据分析的特征可能有多种形式,需要将其合理转化成模型能够处理的形式,特别是对非数值的特征,特征…
Pandas.DataFrame.product() 乘积(累乘积) 详解 含代码 含测试数据集 随Pandas版本持续更新
关于Pandas版本: 本文基于 pandas2.2.0 编写。
关于本文内容更新: 随着pandas的stable版本更迭,本文持续更新,不断完善补充。
传送门: Pandas API参考目录
传送门: Pandas 版本更新及新特性
传送门&…
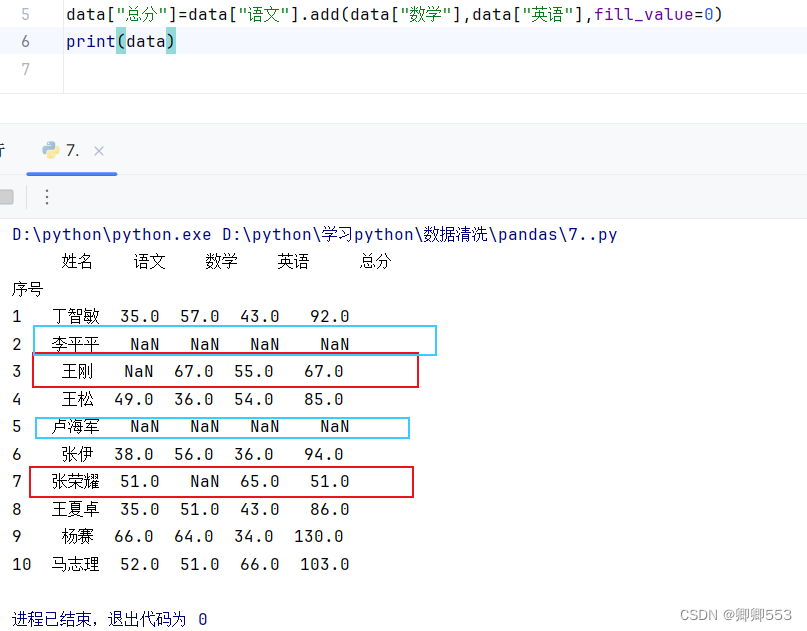
pandas进行数据计算时如何处理空值的问题?
目录
1.数据预览:
2.解决方法
(1)问题示例
(2)方法
A.方法一
B.方法二 1.数据预览: 2.解决方法
(1)问题示例
如下图如果不理睬这些空值的话,计算总分便也会是空值…
Pandas实战100例 | 案例 49: 数值运算
案例 49: 数值运算
知识点讲解
Pandas 提供了进行基本数学运算的简便方法,允许你在 DataFrame 的列之间执行加法、减法、乘法和除法等操作。
数值运算: 直接对 DataFrame 的列应用算术运算符(, -, *, /)可以执行相应的数值运算。
示例代码…
Pandas实战100例 | 案例 53: 处理缺失值
案例 53: 处理缺失值
知识点讲解
在数据分析中,处理缺失值是一个常见且重要的步骤。Pandas 提供了多种方法来处理 DataFrame 中的缺失值,包括填充缺失值和删除含有缺失值的行或列。
填充缺失值: 使用 fillna 方法可以将缺失值替换为指定的值。删除缺失…

python常用pandas函数nlargest / nsmallest及其手动实现
目录
pandas库
Series和DataFrame
nlargest和nsmallest
用法示例
代替方法
手动实现
模拟代码 pandas库
是Python中一个非常强大的数据处理库,提供了高效的数据分析方法和数据结构。它特别适用于处理具有关系型数据或带标签数据的情况,同时在时间…

数据分析-Pandas如何整合多张数据表
数据分析-Pandas如何整合多张数据表
数据表,时间序列数据在数据分析建模中很常见,例如天气预报,空气状态监测,股票交易等金融场景。数据分析过程中重新调整,重塑数据表是很重要的技巧,此处选择Titanic数据…
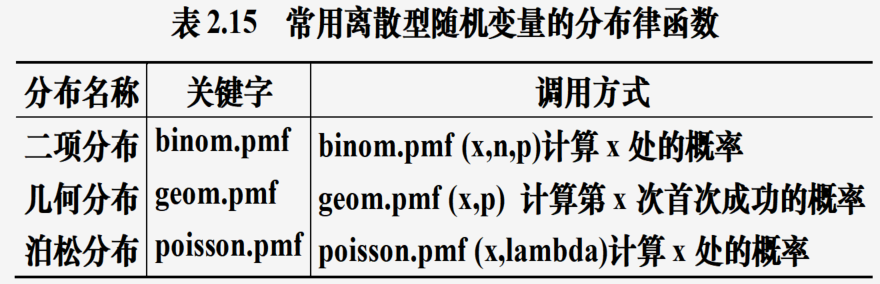
【数学建模】数据处理与可视化
文章目录 数值计算工具NumPy数组的创建、属性和操作数组的运算、通用函数和广播运算Numpy.random模块的随机数生成文本文件和二进制文件存取 文件操作文件基本操作文件管理方法 数据处理工具PandasSeries和DataFrame外部文件存取 Matplotlib可视化基础用法可视化应用可视化综合…
Pandas.Series.count() 非空单元格计数 详解 含代码 含测试数据集 随Pandas版本持续更新
关于Pandas版本: 本文基于 pandas2.1.2 编写。
关于本文内容更新: 随着pandas的stable版本更迭,本文持续更新,不断完善补充。
Pandas稳定版更新及变动内容整合专题: Pandas稳定版更新及变动迭持续更新。 Pandas API参…

爬虫与DataFrame对象小小结合
import pandas as pd
import requests
from lxml import etree
#数据请求
url"https://www.maigoo.com/brand/list_1715.html"
headers{User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Safari…
数据分析 | Pandas 200道练习题,每日10道题,学完必成大神(2)
文章目录前期准备1.通过DataFrame保存为EXCEL2.查看数据行列数3.提取popularity列中值大于3小于7的行4.交换两列的位置5.提取popularity列最大的行所在行6.查看最后3行数据7.删除最后一行数据8.添加一行数据9.队数据按照popularity列的值的大小进行排序10.统计grammer列每个字符…
52_Pandas处理日期和时间列(字符串转换、日期提取等)
52_Pandas处理日期和时间列(字符串转换、日期提取等)
将解释如何操作表示 pandas.DataFrame 的日期和时间(日期和时间)的列。字符串与 datetime64[ns] 类型的相互转换,将日期和时间提取为数字的方法等。
以下内容进行…
统计软件与数据分析Lesson1--3 其它知识点
提示:统计软件与数据分析Lesson1至Lesson3 补充知识点 统计软件与数据分析Lesson1--3 其它知识点1.python查看数据基本信息1.1查看变量类型:type(变量名)1.2查看变量长度:len(变量名)1.3查看变量包含的属性:dir(变量名)1.4查看Numpy数组基本信息1.5查看dataframe数据…

数据分析 | Pandas 200道练习题 进阶篇(1)
文章目录前期准备DA5 牛客网用户没有补全的信息DA6 查看牛客网哪些用户使用PythonDA7 牛客网Python用户的成就值DA8 文件最后用户的部分数据好久没有更新数据分析相关的内容,大家都知道数据分析的练习题不好找,博主这些天找的一个可以在线练习的网站推荐…

【Python】pd.set_option()的效果与解析
【Python】pd.set_option()的效果与解析 文章目录【Python】pd.set_option()的效果与解析1. 介绍2. API3. 举例-13.1 显示所有行3.2 显示所有列3.3 显示列中单独元素的最大长度4. 举例-24.1 换行显示、每行最大显示宽度5. 参考1. 介绍
pd.set_option()这个函数主要用于设置Dat…
pandas 通过正则表达式查询和筛选
str.contains():包含一个特定的字符串 参数na:缺少值NaN处理 参数case:大小写我的处理 参数regex:使用正则表达式模式
可以通过str.contains()的参数na来指定替换NaN结果的值。 print(df_nan[‘name’].st…
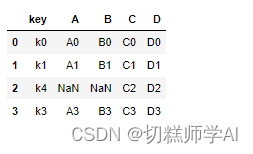
Python量化交易01——构建基础策略
参考书目:深入浅出Python量化交易实战 量化交易是很早就想开的栏目了,之前没时间。现在正好放寒假,然后也找到了一本合适的书可以进行学习。
本次第一章就介绍一下简单的量化流程和一个简单的策略。
量化交易顾名思义就是用代码去验证交易策略是否赚钱…
如何使用pandas提取含有指定字符串
这里写自定义目录标题name age state point0 Alice 24 NY 641 Bob 42 CA 922 Charlie 18 CA 70name age state point0 Alice 24 NY 642 Charlie 18 CA 700 False1 True2 TrueName: state, dtype: boolname age state point1 Bob 42 CA 922 Charlie 18 CA 700 True1 False2 True…
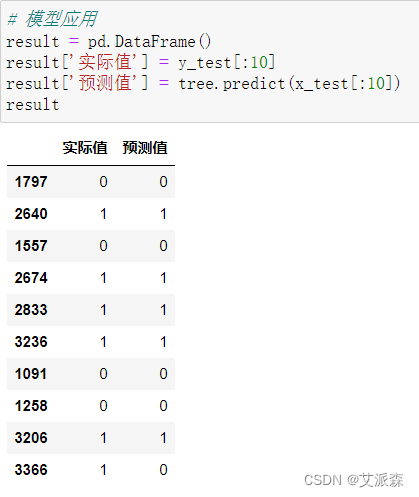
大数据分析案例-基于决策树算法构建员工离职预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…
【致敬未来的攻城狮计划】— 连续打卡第四天:e2 studio 使用教程
系列文章目录 1.连续打卡第一天:提前对CPK_RA2E1是瑞萨RA系列开发板的初体验,了解一下 2.开发环境的选择和调试(从零开始,加油) 3.欲速则不达,今天是对RA2E1 基础知识的补充学习。 文章目录 系列文章目录 文…

python共词矩阵分析结果一步到位
import os
import re
import pandas as pd
from PyPDF2 import PdfFileReader
import string
import yakeif __name__ __main__:# 运行第一部分代码pdf_files_path C:/Users/win10/Documents/美国智库/pdf_files# 定义一个函数,用于读取PDF文件并将其转化成文本de…
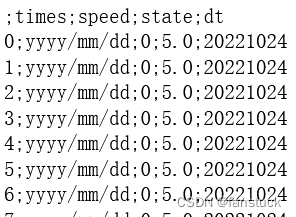
Pandas.to_csv()函数及全部参数使用方法一文详解+实例代码
目录
前言
一、基础语法与功能
二、参数说明和代码演示
1.path_or_buf 选择文件/文件路径写入
2.sep 指定分隔符 3.na_rep 指定缺少数据表示
4.float_format 指定浮点型字符串输出格式
5. columns 指定要写入的列
6.header 是否需要写入列名 7.index 是否写入行名称&am…
python实现excel和csv中的vlookup函数
本篇博客会介绍如何使用python在excel和csv里实现vlookup函数的功能,首先需要简单了解一下python如何操作excel
1. python处理excel
1.1 删除excel中指定行
在文件夹里创建了一个excel文件,可以看到里面放的是三国人物的数据 会发现在【蜀】里&#…
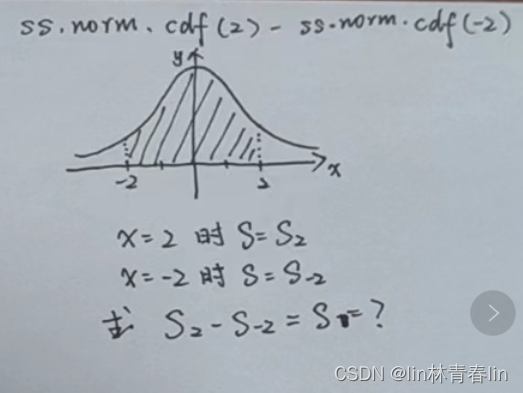
python学习笔记-查看数据结构、均值、中位数、分位数、众数、离中趋势(标准差、方差、求和、偏态系数、风险系数)正态分布pdf、cdf、ppf
①引入pandas包,命名为pd。
import pandas as pd
②读入HR.csv数据
dfpd.read_csv(“./data/HR.csv”)
③查看是什么结构
type(df)
④查看单个类别satisfaction_level的数据结构
type(df[“satisfaction_level”])
⑤查看均值的数据结构
type(df.mean())
…
Python 关于大文件的读写
1、前言项目时遇到训练集过大的情况,无法直接读入内存,而使用keras的fit_generator()感觉也遇到了IO瓶颈。 于是想把验证集从训练集中分离出来,每次只把验证集读取进内存,节省一定的时间。在这个过程中遇到了一系列问题࿰…

padans关于数据处理的杂谈
情况:业务数据基本字段会有如下:
Index([时间, 地区, 产品, 字段, 数值], dtypeobject)这样就会引发一个经典“三角不可能定理”,如何同时简约展现分时序、分产品、分字段数据。)一般来说,
1、时序为作为单独的分类&…
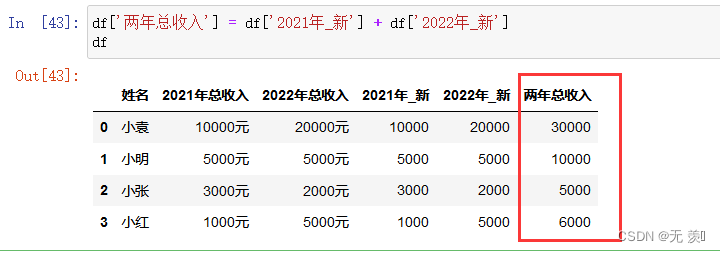
100天精通Python(数据分析篇)——第76天:Pandas数据类型转换函数pd.to_numeric(参数说明+实战案例)
文章目录专栏导读一、to_numeric参数说明0. 介绍1. arg1)接收列表2)接收一维数组3)接收Series对象2. errors1)errorscoerce2)errors ignore3. downcast1)downcastinteger2)downcastsigned3&…
【附代码】Python Excel合并单元格(OpenPyXL) Pandas.DataFrame groupby样式保存xlsx
文章目录 相关文献Excel合并单元格并居中Pandas.DataFrame groupby样式保存Excel 作者:小猪快跑 基础数学&计算数学,从事优化领域5年,主要研究方向:MIP求解器、整数规划、随机规划、智能优化算法
如有错误,欢迎指…
Python - Pandas绘图
绘图
柱状图
tips[total_bill].plot.hist()
plt.show()tips[[total_bill, tip]].plot.hist()
plt.show()kde 图:
tips[tip].plot.kde()
plt.show()散点图:
tips.plot.scatter(xtotal_bill, ytip)
plt.show()六角星箱体图:
tips.plot.hexbin(xtotal_bill, ytip, gridsize10…

Python实战:xlsx文件的读写
Python实战:xlsx文件的读写 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程 👈 希望得到您的订阅和支持~ &#…
pandas、xlrd、openpyxl读取Excel性能对比
假设有一个包含1000行、30列数据的Excel文件,我们可以使用以下代码对这三种方法进行性能测试。 方法一:使用Pandas库 import pandas as pd
import timeitexcel_file example.xlsx
sheet_name Sheet1def pandas_method():data_frame pd.read_excel(ex…
python pandas写入csv
在Python的Pandas库中,可以使用to_csv方法将DataFrame对象写入CSV文件。以下是一个简单的示例:
import pandas as pd# 创建一个DataFrame对象
data {Name: [Alice, Bob, Charlie, David],Age: [25, 30, 35, 40],City: [New York, Los Angeles, Chicago…
【Python】进阶学习:pandas--如何根据指定条件筛选数据
【Python】进阶学习:pandas–如何根据指定条件筛选数据 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望…
数据科学必备技能:掌握Pandas序列和数据框
数据科学必备技能:掌握Pandas序列和数据框 文章目录数据科学必备技能:掌握Pandas序列和数据框一、Pandas简介二、序列1、序列创建及访问2、序列属性3、序列方法4、序列切片5、序列聚合运算三、数据框1、数据框创建2、数据框属性3、数据框方法4、数据框切…

【量化交易笔记】5.SMA,EMA 和WMA区别
股票中的SMA,EMA和WMA是常用的技术分析指标。这些指标基于历史股价计算得出,可以帮助投资者了解股票的趋势,为决策提供依据。虽然它们都是平均值算法,但它们之间还是有一些区别的。
SMA 简单移动平均线(Simple Moving…
Pandas处理数据常用方法
pd处理表格步骤
1. 接收文件流,已 django 为例
# 接受单个文件
file request.FILES[file] # 写法一
file request.FILES.get(file) # 写法二# 接收多个文件
files request.FILES.getlist(files) 2. pd读取文件流
df pd.read_excel(file)
3. 常用处理数据方法…
pandas库中的read_csv函数读取数据时候的路径问题详解(ValueError: embedded null character)
read_csv()函数不仅是R语言中的一个读取csv文件的函数,也是pandas库中的一个函数。pandas是一个用于数据分析和处理的python库。它的read_csv函数可以读取csv文件里的数据,并将其转化为pandas里面的DataFrame对象。它由很多参数可以设置,例如…
【python】Pandas库用法详解!
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Py…
python --生成时间序列,作为横轴的标签。时间跨越2008-2022年,生成每年的6-10月的第一天作为时间序列
python 生成制定的时间序列作为绘图时x轴的标签
问题需求
在绘图时,需要对于x轴的标签进行专门的设置,整体时间跨越2008年-2022年,将每年的6-10月的第一天生成一条时间序列,绘制成图。
解决思路
对于时间序列的生成࿰…
Pandas中的方法及使用示例
前言 系列文章目录 [Python]目录 视频及资料和课件 链接:https://pan.baidu.com/s/1LCv_qyWslwB-MYw56fjbDg?pwd1234 提取码:1234 文章目录前言1. Series() -- 创建 Series 对象2. DataFrame() -- 创建 DataFrame 对象3. read_csv() -- 读取 csv 文件fi…
5行代码实现新列自动生成,也许你还不知晓这么简单!
Pandas是Python中非常流行的数据分析库,它的DataFrame和Series数据结构可以方便地处理和分析大量数据。很多时候,我们需要根据DataFrame中的某些列来生成新的列,今天我们就来看一个根据两列值条件判断生成新列的例子。 假设我们有一个DataFra…
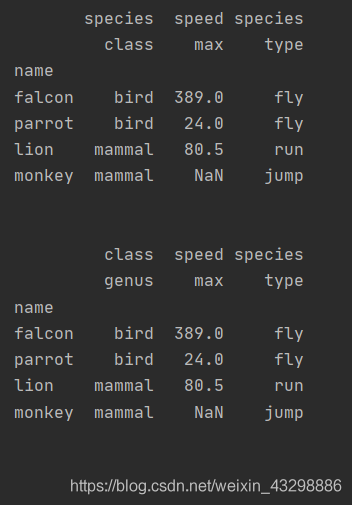
【Python_Pandas】reset_index() 函数解析
【Python_Pandas】reset_index函数解析 文章目录 【Python_Pandas】reset_index函数解析1. 介绍2. 示例2.1 参数drop2.2 参数inplace2.3 参数level2.4 参数col_level2.5 参数col_fill 参考 1. 介绍
pandas.DataFrame.reset_index
reset_index(levelNone, dropFalse, inplaceF…

Pandas中的逻辑运算符(与或非)及Python代码示例
Pandas是Python中一个非常流行的用于数据处理和分析的库,它提供了大量的函数和操作符,以便用户可以方便地对数据进行操纵。其中逻辑运算符是在Pandas中经常使用的一些操作符之一,因为它们使我们可以对数据进行逻辑上的比较和筛选。本篇博客将…

晶飞FLA5000光谱仪.FlaSpec格式解析批处理导出CSV文件
引言
首先说明下晶飞上位机软件存在的问题,实验所采用的FLA5000型号光谱仪,光谱波段从280-970nm,FWHM值为2.4nm。 1、上位机软件中的光谱数据复制功能基本是废的,最多只能到599.9nm,后面的数据全部消失。 2、上位机软…
27. Pandas怎样找出最影响结果的那些特征?
import pandas as pd
import numpy as np# 特征最影响结果的K个特征
from sklearn.feature_selection import SelectKBest# 卡方检验,作为SelectKBest的参数,测量特征和结果的关系
from sklearn.feature_selection import chi2df pd.read_csv(./titanic/titanic_tr…
25.Pandas结合Sklearn实现泰坦尼克存活率预测
实例目标:实现泰坦尼克存活预测
处理步骤: 1、输入数据:使用Pandas读取训练数据(历史数据,特点是已经知道了这个人最后有没有活下来) 2、训练模型:使用Sklearn训练模型 3、使用模型:对于一个新的不知道存活…
chatgpt赋能Python-left_join_python
了解Python的Left Join
随着数据生成速度的急剧增加,数据存储和处理已经成为企业成功的关键因素。数据库的产生和发展对于当今企业已经变得非常普及,但是在处理数据的过程中,很少会有数据能够完全匹配。这时候,Left Join就成为了…

python数据处理----整理数据
为什么要整理数据 对于这种“宽”数据,在展示方面来说没有什么问题,但是数据分析的时候我们需要“长”数据,这时候就需要整理数据整理成我们想要的样子。 melt( )函数
把字段拆分成数据
id_vars参数:保留哪个字段(可…
pandas---数据处理(excel文件)
近期在弄一个项目的前期数据,所以总结了一下,内容如下(以下以csv文件为例) 1. DataFrame常用操作1.1 DataFrame去除空行(1)对于一般空行(2)对于列表式(list)空…

2018年北京积分落户数据分析 看这篇就够了
2018北京积分落户名单 百度网盘提取码: w7gy
话不多说,直接上代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 读取文件
luohu_data pd.read_csv(./bj_luohu.csv, index_colid)# 显示前5条信息
print(luohu_data.head())# descr…
Pandas的时间与日期(日期转换,创建日期等)
创建日期:
import pandas as pd
rng pd.date_range(1/1/2011, periods10958, freqD) # freqD 以天为间隔,
# periods10958创建10958个print(rng[:10958])
T pd.DataFrame(rng[:10958]) # 创建10958个连续日期
T.to_csv(data05.csv) # 保存 事实证…
linux专题:GDB详细调试方法与实现
系列文章目录
例如:第一章 Linux-GDB 调试实验的使用 文章目录 目录 系列文章目录 文章目录 一、实验目的 二、实验现象 三、实验准备 四、Linux GDB调试实验流程 五、Linux GDB 调试器 总结 一、实验目的
掌握使用 gcc 分步编译 c 代码为可执行程序步骤以及 gc…
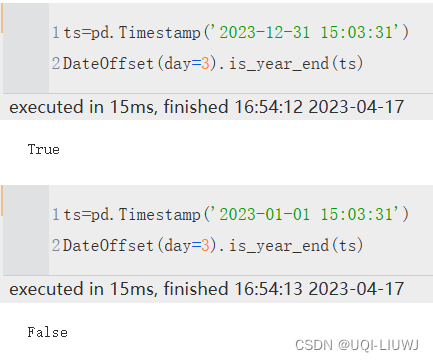
pandas笔记:offset.DateOffset
进行date的偏移
class pandas.tseries.offsets.DateOffset
1 参数说明
n 偏移量表示的时间段数。 如果没有指定时间模式,则默认为n天。 normalize是否将DateOffset偏移的结果向下舍入到前一天午夜**kwds 添加到偏移量的时间参数 年(years)…
python-pandas按各种时间统计
使用到的库
pandas、matplotlib、numpy
使用到的函数
df.resample(“H”).sum() 参数 B business day frequency C custom business day frequency (experimental) D calendar day frequency W weekly frequency M month end frequency BM business month end frequency CBM…
数据科学简介:如何使用 Pandas 库处理 CSV 文件
部分数据来源:ChatGPT
什么是 CSV 文件? CSV ( Comma Separated Values)文件是一种常见的文本文件格式,它通常用于存储结构化数据,因为它可以轻松地转换成电子表格,如Excel。
CSV 文件是以逗号作为分隔符的表格数据。文件中的每行代表一个记录,每列代表一个属性。例如…
python学习之pandas库的使用总结
【1】读取CSV并进行透视
我们的原始数据格式: ① 读取数据
pd.read_csv 会读取csv表格并使用names指定读取后的列名称。
import pandas as pdreleaseNumOfYear pd.read_csv("data/releaseNumOfYear.csv", headerNone, names[Year, Genre, ReleaseNum]…
python3.9安装和pandas安装踩坑处理
0、先决条件:系统内最好先安装有gcc、libffi-devel等 1、安装包下载
https://www.python.org/downloads/source/ 2、解压安装包并上传到/usr/local/python3.9 3、打开shell
cd /usr/local/python3.9要先把python3.9的所有文件复制到/usr/local/python3.9才会成功…
2023年美国大学生数学建模A题:受干旱影响的植物群落建模详解+模型代码(一)
目录
前言
一、题目理解
背景
解析:
要求
二、建模
1.相关性分析
2.相关特征权重
只希望各位以后遇到建模比赛可以艾特认识一下我,我可以提供免费的思路和部分源码,以后的数模比赛只要我还有时间肯定会第一时间写出免费开源思路&…
使用 Python 生成股票 K 线图
引言 在股票分析中,经常需要用到 K 线图来分析股票的价格波动情况和交易量情况。本文将介绍如何使用 Python 和 pyecharts 库生成股票 K 线图,并将其保存为 HTML 文件。
准备数据 首先,我们需要准备股票数据。在这里,我们使用 stock.csv 示例数据,该数据包括日期、开盘价…
用LDA主题模型并进行可视化
以下是一个使用Python中Gensim库实现LDA主题模型并进行可视化的代码示例: 这段代码实现了一个简单的LDA主题模型构建和可视化的过程。
方法2
首先,使用Pandas库中的read_excel()函数读取一个Excel文件data.xlsx作为数据源,然后选取其中一个…
DSP CCS 开发问题总结及解决办法
文章目录 问题汇总 1. CCS编译器的Project菜单栏工程导入选项丢失,怎么解决! 1.1启动CCS后发现导入工程菜单栏丢失,无法导入工程文件。 1.2方法一 工程选项的导入工程文件丢失,如果要重新获得相应的选项,就需要删除当前…
random.shuffle(indices) 写一个demo
random.shuffle(indices)是Python中的一个函数,用于将一个序列随机打乱。该函数会直接修改原始列表,不会返回任何值。
以下是一个简单的示例,演示如何使用random.shuffle()函数打乱一个整数序列: 复制代码 import random # 生成一…
使用Pandas进行数据处理和分析的入门指南
摘要:本文将介绍如何使用Python的Pandas库进行数据处理和分析,包括数据导入、数据清洗、数据转换和简单分析等方面的内容。
引言
在数据科学和数据分析领域,数据处理是一个关键的步骤。Python的Pandas库提供了强大且易于使用的工具…
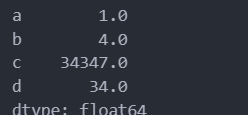
pandas 中如何按行或列的值对数据排序?
在处理表格型数据时,常会用到排序,比如,按某一行或列的值对表格排序,要怎么做呢?
这就要用到 pandas 中的 sort_values() 函数。
一、 按列的值对数据排序
先来看最常见的情况。
1.按某一列的值对数据排序
以下面…

pandas对某一列的种类编码
文章目录背景实现背景
如果某一列的种类特别多,想要通过映射来编码,这样非常麻烦,所以可以对一个列全部一次性进行编码。
例如我的数据如下: 我需要编码专业这个列,我们可以看到这一列很多:
实现
使用…

Python基础—文件操作
Python基础—文件操作
文件操作
文件是指为了重复使用或长期使用的目的,以文本或二进制形式存放于外部存储器(硬盘、U盘、光盘等)中的数据保存形式,文件是信息交换的重要途径,也是利用程序解决实际问题的重要媒介。 …
python中.ix()函数的作用
在早期版本的Pandas库中,.ix函数被用于基于标签和整数位置进行数据访问和操作。然而,在较新的版本中(从Pandas 0.20.0开始),.ix函数已被弃用,并建议使用.loc和.iloc函数来替代。
在较新版本的Pandas中&…
全国大学生数据统计与分析竞赛2021年【本科组】-B题:基于某 K12 教育企业用户数据的消费行为价值分析
目录 摘 要 一、 问题重述 1 . 1 问题背景 1 . 2 提出问题 二、 数据预处理
pandas使用教程:apply函数、聚合函数agg和transform
文章目录 apply函数调用apply函数描述性统计apply函数lambda自定义 聚合函数aggregate/agg用字典实现聚合 transform函数多函数 Transform 重置索引与更换标签行重置索引行和列同时重置索引 apply函数调用
apply函数描述性统计
import numpy as np
df.loc[:,Q1:Q4].apply(np.…
python遍历一个文件夹下所有excel,读取所有sheet页,然后写入另一个文件夹下对应模板的excel中
本来想直接写入,但是我们的excel报表太麻烦了,里面表头有多处要求合并的,用python去写太要命了,想了下,设置一堆空的excel模板,这样只需要把原文件的数据读出来就可以了,简单多了 #读取文件夹下…
![[Pandas] 读取Excel文件](https://img-blog.csdnimg.cn/3112274ca9574ec4b0cc899969cbe515.png)
[Pandas] 读取Excel文件
练习数据准备 demo.xlsx demo.xlsx中的工作表Sheet1显示上述的数据,Sheet2没有数据 我们可以使用Pandas中的read_excel()方法读取Excel格式的数据文件,生成DataFrame数据框进行数据分析处理
基本语法格式
import pandas as pd
pd.read_excel(io, sheet…
pandas基本操作
df.head()/tail() 查看头/尾5条数据;df.info 查看表格简明概要;df.dtypes 查看字段数据类型;df.index 查看表格索引;df.columns 查看表格列名;df.values 以array形式返回指定数据的取值;list(dt.groupby(&q…
Pandas-如何用pandas批量删除含有某些特征数据的行
前言 本文是该专栏的第30篇,后面会持续分享python数据分析的干货知识,记得关注。
在工作上处理数据需求的时候,会通常需要你将某张数据表里面的多条特征数据进行删除,最后再保存清洗完成的数据。换言之,假设有某张csv数据表(几十万条数据),而在这张表里面需要将几万条不…
使用requests+parsel+pandas+mysql完成的一个爬虫示例
一个爬虫示例
目标网址:链家二手房
使用到的库
requests 网络请求parsel 网页解析pandas 数据处理和存储pymysql、dbutils 数据持久化
其中MySQL存储用的是一个封装好的API类
传送门: mysql-client-tools
说明
数据的存储会有两种模式,一种是直接…
pandas列值根据字典批量替换
更多、更及时内容欢迎留意微信公众号: 小窗幽记机器学习
背景
DataFrame数据中一列的值需要根据某个字典批量映射为字典中的value。
方法1:pandas中的df.replace import pandas as pdimport numpy as npdf pd.DataFrame({col2: {0: a, 1: 2, 2: np.n…
按照len长度过滤pandas中值为list类型的数据
背景
pandas中对于值为list的数据,如果想要根据list的长度进行过滤,如何操作?
方案
假设数据集: a b c
1 x y [x]2 x z [c,d]3 x t [e,f,g]想要实现result_df df[len(df[result])>1] 这种功能。比如…

pandas 两列数据合并
背景
有两个字段,想要将其合并成为一个新的字段。比如当标签分散在不同字段时候,想要将各个标签融合一起。
实现
def test():import pdbimport pandas as pddf pd.DataFrame({year: [2019, 2020], quarter: [q1, q2]})df[year_quarter] df[year] &…
7. np.where, np.argwhere, df.where, df.mask
7. np.where, np.argwhere, df.where, df.mask
7.1 np.where
numpy.where(condition[, x, y]) 根据条件选择x或y的元素返回。如果condition为真,返回x的元素;反之返回y的元素
a np.arange(10)a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])np.where(a <…
pandas中对类别属性计数、统计出现的不同类别
Series.unique()返回Series对象中唯一值的NumPy array
pd.Series([2, 1, 3, 3], nameA).unique()
#array([2, 1, 3])Series.value_counts(normalizeFalse, sortTrue, ascendingFalse, binsNone, dropnaTrue)返回一个Series,记录Series对象中唯一值出现的次数。
in…
pandas4 pandas的数据运算
文章目录4.pandas数据运算算术运算函数的应用和映射排序统计汇总4.pandas数据运算
算术运算
如果有相同索引则进行算术运算,如果没有则会进行数据对齐,但会引入缺失值。对于DataFrame类型,数据对齐的操作会同时发生在行和列上。
import pa…

pandas提取数据框其中几列生成新数据框
假设列名如下:
Team Goals Yellow Cards Red Cards数据框:euro2012
要取得其中的yellow cards 和 red cards,形成 新的 数据框new:
new euro2012[[Yellow Cards,Red Cards]]
dataframe 查找的isin()用法
import pandas as pddf pd.read_excel(分类标准-新.xlsx)#list0[7662,7667,7672,7677,7682,7688,7693,7698,7704,7662,7709,7714,7719,7725,7730,7735,7741,7709,7746,7751,7756,7762,7767,7772,7778,7746,7783,7783]
list0[7664,7669,7674,7679,7684,7690,7695,7700,7706,766…
2.pandas统计分析基础(读取数据、dataframe、索引)
笔记说明:本文是我的学习笔记,大部分内容整理自 黄红梅,张良均等.Python数据分析与应用[M].北京:人民邮电出版社,2018,80-130. 还有部分片断知识来自网络搜索补充。
推荐 这个博客帖子https://blog.csdn.net/hhtnan/article/details/80080240 文章目录1…
PysparkNote105---udf的使用
Intro pyspark udf的使用
数据构造
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import DoubleType,IntegerType,StringTypedef get_or_create(app_name):spark (SparkSession.builder.appName(app_name).config(…
Python——第7章 pandas数据分析实战
7.1pandas常用数据类型
7.1.1一维数组与常用操作
import pandas as pd
import matplotlib.pyplot as plt#设置输出结果对齐方式
pd.set_option(display.unicode.ambiguous_as_wide,True)
pd.set_option(display.unicode.east_asian_width,True)#自动创建从0开始的非负整数索引…

Pandas+Matplotlib+Pylab实现填充的双折线图和坐标轴字体旋转
第一步,导入必要的包:
#-- coding : utf-8 --
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
import pylab as pl
mpl.rcParams[font.sans-serif] [SimHei] # 设置字体为黑体
mpl.rcParams[axes.unicode_minus] Fals…

关于数据挖掘的问题之经典案例
依据交易数据集 basket_data.csv挖掘数据中购买行为中的关联规则。
问题分析:
如和去对一个数据集进行关联规则挖掘,找到数据集中的项集之间的关联性。
处理步骤:
首先导入了两个库,pandas 库和 apyori 库。pandas 库是 Pytho…
Pandas+Seaborn+Matplotlib实现不同颜色分组散点图+回归分析
任务:有一个excel表格,想要画第2、3列的散点图,不同物种不同颜色,突出显示均值,并画出回归线。
第一步,导入包:
#-- coding : utf-8 --
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns第二步,防止输出的图片出现乱码,并设置字体为新罗…
Pandas和Matplotlib用excel数据画双y轴折线图
第一步先导入必要的包:
import numpy as np # 导入各个模块
import matplotlib.pyplot as plt
import pandas as pd
from pandas import Series, DataFrame
from pylab import mpl
mpl.rcParams[font.sans-serif] = [&#
python 爬虫之数据清洗
Python爬虫是一项强大的工具,可用于获取大量数据并进行分析和处理。但是,爬取的数据在处理之前需要经过清洗,以消除无用或无效的信息,并确保数据可靠和可用。在本文中,我们将详细讨论Python爬虫数据清洗的过程和技巧&a…
pandas练习(一)
pandas练习(一)
建立一个以 2018 年每一天为索引,值为随机数的 Series
dti pd.date_range(start2018-01-01,end2018-12-31,freqD)
s pd.Series(np.random.rand(len(dti)),indexdti)
s统计s 中每一个周三对应值的和
s[s.index.weekday 2…
数据分析之Pandas的常见用法
一、生成数据表 1、首先导入pandas库,一般都会用到numpy库,
pd.read_csv(filename_path):从CSV文件导入数据 pd.read_table(filename_path):从限定分隔符的文本文件导入数据 pd.read_excel(filename_path):从Excel文件…
python 多线程模拟多用户访问接口
# -- coding: utf-8 --** import threading import requests from urllib.parse import quote # 定义访问接口的函数 def access_api(user_id): params%E4%BB%80%E4%B9%88%E6%98%AF%E5%A2%9E%E5%80%BC%E7%A8%8E chinese_text "什么是增值税" url_encoded_text quot…
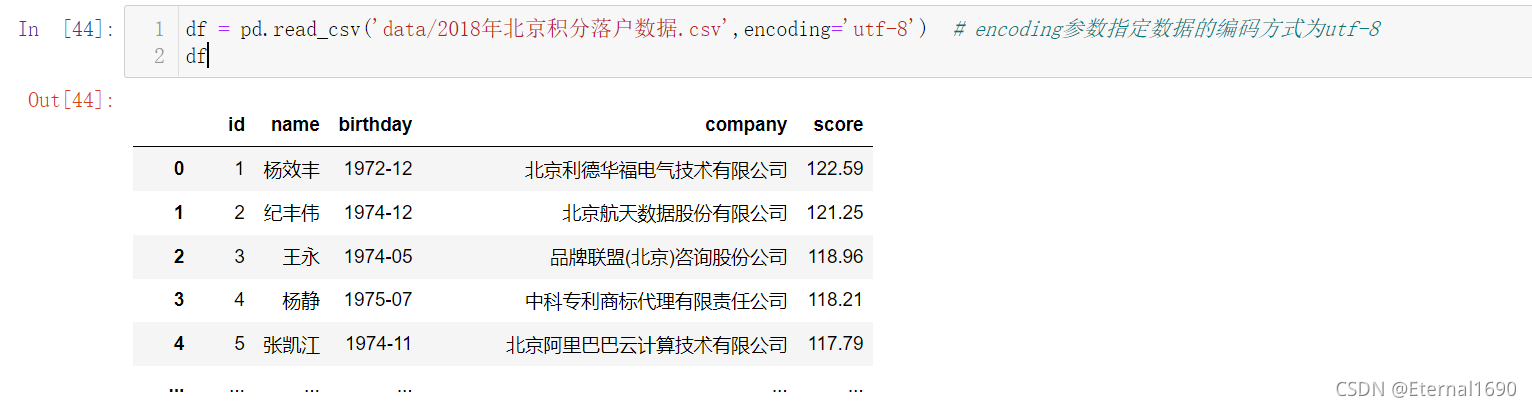
pandas创建DataFrame的几种方式(建议收藏)
pandas创建DataFrame的几种方式
如果你是一个pandas初学者,那么不知道你会不会像我一样。在学用列表或者数组创建DataFrame时理不清怎样用数据生成以及想要形状的的Dataframe,那么,现在,你不用自己琢磨了,我这里给你整…
4.12 Pandas中的DataFrame数据类型API函数参考手册(二) (Python)
Pandas中的DataFrame数据类型API函数参考手册 二 目录前言 一、构造函数(Constructor)二、属性和基础数据(Attributes and underlying data)三、转换(Conversion)1. DataFrame.astype(dtype[, copy, errors])2. DataFrame.convert_dtypes([infer_objects, ...])3. DataFrame.in…

python电商数据预处理
电商数据预处理
今天对电商数据进行了预处理,主要处理了 1. 提取2019年的订单数据 2. 处理业务流程不符的数据(支付时间早于下单时间、支付时长超过30分钟、订单金额小于0、支付金额小于0) 3. 处理渠道为空的数据(补充众数&#…
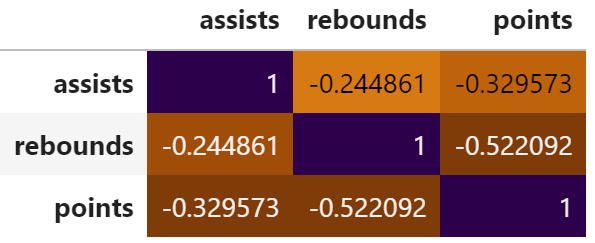
【python】如何在 Python 中创建相关矩阵
目录
一、说明
二、相关理论
2.1 何为相关
2.2 相关的前提
2.3 Correlation Matrix是个啥?
2.4 皮尔逊相关系数
三、Python演示如何创建相关矩阵
四、数据可视化观察
五、后记 一、说明 本教程介绍如何在 Python 中创建和解释相关矩阵。然而,创…
Pandas 高级操作使用技巧总结
前言
在数据分析和数据建模的过程中需要对数据进行清洗和整理等工作,有时需要对数据增删字段。下面为大家介绍Pandas对数据的复杂查询、数据类型转换、数据排序、数据的修改、数据迭代以及函数的使用。 复杂查询
实际业务需求往往需要按照一定的条件甚至复杂的组合…
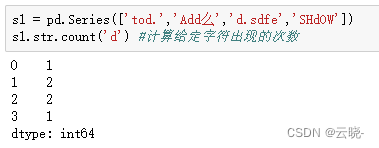
python学习——文本数据处理
目录 1 计算长度 len2 大小写 lower、upper、title、capitalize、swapcase3 字符检索 get、slice4 元素提取 findall、extract5 索引操作 find、index6 字符类型判断,结果一定是True或False7 字符判断 contains、startswith、endswith8 替换 replace9 字符的分割 split、partit…
pandas中query()函数用法
在Pandas中,query函数用于从数据集中查询满足特定条件的行。它接受一个字符串参数,该参数描述了要查询的条件。
以下是使用query函数的基本语法:
df.query(condition)其中,df是要查询的数据集,condition是查询条件。…

python--Pandas高级处理
文章目录Pandas高级处理1. 高级处理-缺失值处理1.1 如何进行缺失值处理两种思路:如何处理nan不是缺失值nan,有默认标记的2. 高级处理-数据离散化one-hot编码&哑变量2.1 什么是数据的离散化2.2 为什么要离散化2.3 如何实现数据的离散化3. 高级处理-合…

Python--Pandas简单了解
文章目录Python--Pandas简单了解1. Pandas介绍1.1 Pandas介绍 - 数据处理工具1.2 为什么使用Pandas1.3 DataFrameDataFrame索引的设置2. 基本数据操作2.1 索引操作2.2 赋值2.3 排序3. DataFrame运算算术运算逻辑运算统计运算自定义运算4. Pandas画图pandas.DataFrame.plot5 文件…
Python数据分析:探索性分析
写在前面
如果你忘记了前面的文章,可以看看加深印象:Pandas数据处理Python数据分析实战:缺失值处理Python数据分析实战:获取数据
然后可以进入今天的正文
一、描述性统计分析
Excel里可以用【数据分析】功能里的【描述统计】功…
![[Pandas] 构建DataFrame数据框](https://img-blog.csdnimg.cn/c01b99c1798248cfa699cc64c16557cc.png)
[Pandas] 构建DataFrame数据框
DataFrame是二维数据结构,数据以行和列的形式排列
构建DataFrame最基本的定义格式如下
df pd.DataFrame(dataNone, indexNone, columnsNone) 参数说明 data: 具体数据 index: 行索引,如果没有指定,会自动生成RangeIndex(0,1,2,...,n) colu…
Python数据分析:缺失值处理
写在前面
上周我们读取完了数据(Python数据分析实战:获取数据),下面就要对数据进行清洗了,首先是对缺失值的处理。缺失值也就是空值,先找出来再处理。
查看缺失值
可以使用isnull方法来查看空值…
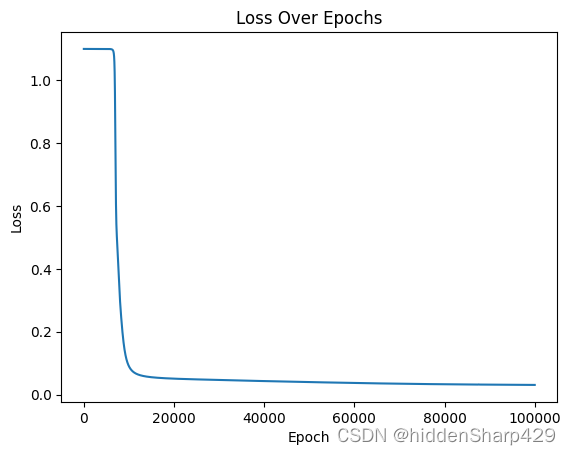
【Python】人工智能-机器学习——不调库手撕深度网络分类问题
1. 作业内容描述
1.1 背景
数据集大小150该数据有4个属性,分别如下 Sepal.Length:花萼长度(cm)Sepal.Width:花萼宽度单位(cm)Petal.Length:花瓣长度(cm)Petal.Width:花瓣宽度(cm)category:类别࿰…
Pandas实战100例 | 案例 42: 数据过滤
案例 42: 数据过滤
知识点讲解
数据过滤是数据处理中的一个基本任务。在 Pandas 中,你可以使用布尔索引来过滤符合特定条件的数据行。
数据过滤: 通过结合条件表达式(例如 df[A] > 2 和 df[B] < 5),可以创建一个布尔索引…
Pandas实战100例 | 案例 16: 字符串操作 - 分割和转换
案例 16: 字符串操作 - 分割和转换
知识点讲解
Pandas 提供了丰富的字符串操作功能,这些功能很大程度上类似于 Python 原生的字符串方法。你可以对 DataFrame 或 Series 中的字符串进行分割、转换、替换等操作。这些操作在处理文本数据时非常有用。
字符串分割: …
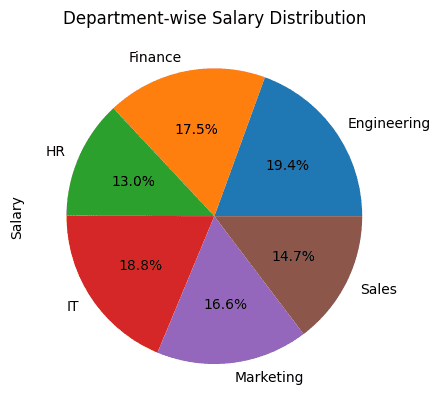
7个Pandas绘图函数助力数据可视化
大家好,在使用Pandas分析数据时,会使用Pandas函数来过滤和转换列,连接多个数据帧中的数据等操作。但是,生成图表将数据在数据帧中可视化,通常比仅仅查看数字更有帮助。
Pandas具有几个绘图函数,可以使用它…
Pandas实战100例 | 案例 44: 添加新列
案例 44: 添加新列
知识点讲解
在数据分析过程中,经常需要基于现有数据计算新的数据列。Pandas 允许你轻松地向 DataFrame 添加新列,并基于现有列进行计算。
添加新列: 直接通过赋值的方式可以向 DataFrame 添加新列。新列的值可以是基于现有列的计算…
Pandas实战100例 | 案例 6: 数据排序 - 对 DataFrame 进行排序
案例 6: 数据排序 - 对 DataFrame 进行排序
知识点讲解
数据排序是数据分析中的一个重要环节,可以帮助我们更好地理解数据的分布和趋势。Pandas 提供了灵活的排序功能,包括按照一列或多列进行升序或降序排序。
示例代码
按单列升序排序
# 按单列升序…

机器学习算法实战案例:时间序列数据最全的预处理方法总结
文章目录 1 缺失值处理1.1 统计缺失值1.2 删除缺失值1.3 指定值填充1.4 均值/中位数/众数填充1.5 前后项填充 2 异常值处理2.1 3σ原则分析2.2 箱型图分析 3 重复值处理3.1 重复值计数3.2 drop_duplicates重复值处理 3 数据归一化/标准化3.1 0-1标准化3.2 Z-score标准化 技术交…
Pandas实战100例 | 案例 54: 日期时间运算
案例 54: 日期时间运算
知识点讲解
当处理带有 datetime 类型数据的 DataFrame 时,Pandas 提供了多种方法来提取和计算日期时间组件。这包括提取年份、月份、日期、星期几以及小时等。
提取日期时间组件: 使用 .dt 访问器,可以从 datetime 类型的列中…

Pandas ------ 向 Excel 文件中写入含有 multi-index 和 Multi-column 表头的数据
Pandas ------ 向 Excel 文件中写入含有 multi-index 和 Multi-column 表头的数据 引言正文 引言
之前在 《pandas向已经拥有数据的Excel文件中添加新数据》 一文中我们介绍了如何通过 pandas 向 Excel 文件中写入数据。那么对于含有多表头的数据,我们该如何将它们…
pandas 常用操作
pandas 常用操作1.pandas列属性操作2. pandas填充值3. pandas重复值操作4. pandas根据值排序5. pandas列值操作6. pandas日期操作7. pandas 均线值8. pandas 数据统计1.pandas列属性操作
修改列名datadata.rename(columns{Dest Country:country,Dest:iata_code,index:from})修…
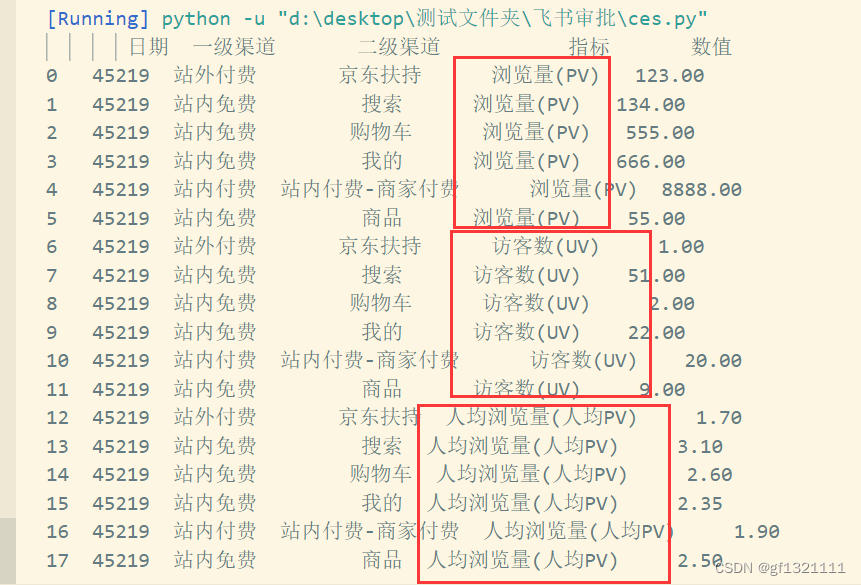
【pandas 将二维表转换成一维】
import pandas as pd # 假设df是您的DataFrame
df pd.DataFrame({ 日期: [45219, 45219, 45219, 45219, 45219, 45219], 一级渠道: [站外付费, 站内免费, 站内免费, 站内免费, 站内付费, 站内免费], 二级渠道: [京东扶持, 搜索, 购物车, 我的, 站内付费-商家付费, 商品]…
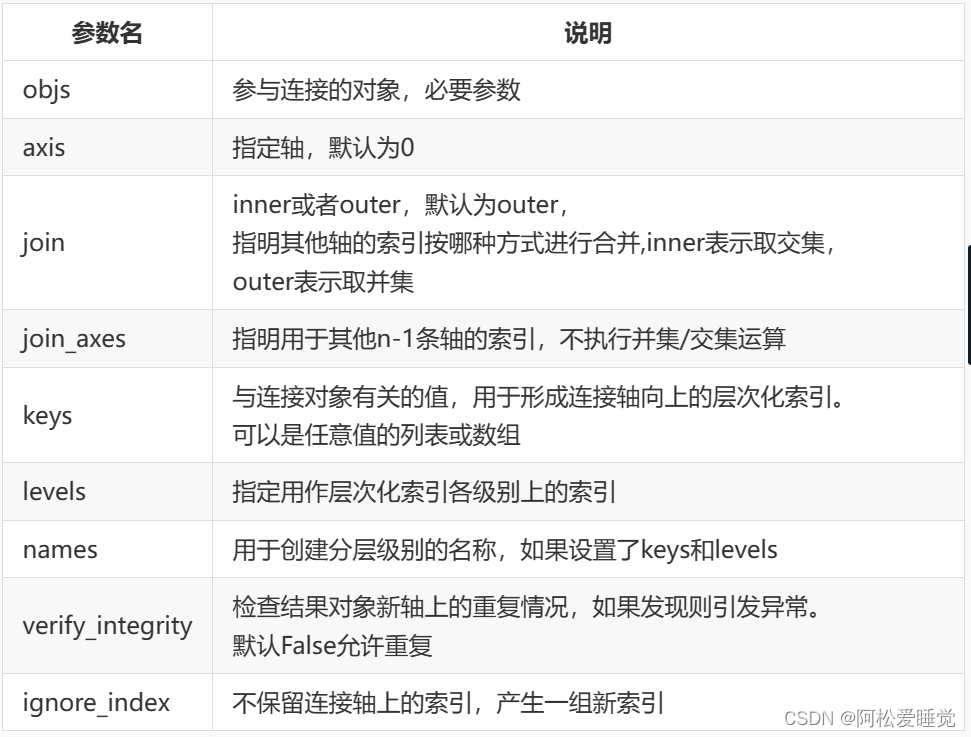
Pandas中Concat与Append_Python数据分析与可视化
Pandas中Concat与Append 合并时索引的处理join和join_axes参数append()方法 在Numpy中,我们介绍过可以用np.concatenate、np.stack、np.vstack和np.hstack实现合并功能。Pandas中有一个pd.concat()函数与concatenate语法类似,但是配置参数更多࿰…
Python Pandas 自定义操作函数`apply()`,`map()`,`applymap()`用法归纳(第17讲)
Python Pandas 自定义函数apply(),map(),applymap()用法归纳(第17讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔…
将一个excel文件里面具有相同参数的行提取后存入新的excel
功能描述:
一个excel里面有很多行数据,其中“交易时间”这一列有很多交易日期,有些行的交易日期是一样的,那么就把所有交易日期相同的行挑出来,形成一个新的以交易日期命名的文件。import pandas as pd
import os# 读取…

合并一个excel文件中的多个sheet
import pandas as pd
#要合并的文件路径
filepath/Users/kangyongqing/Documents/kangyq/202311/班均及合班储备/最后校验/二批次组班/
file1z小班合班方案_2012(1).xlsx
#获取文件d的所有sheet名
df1pd.read_excel(filepathfile1,sheet_nameNone,engine…
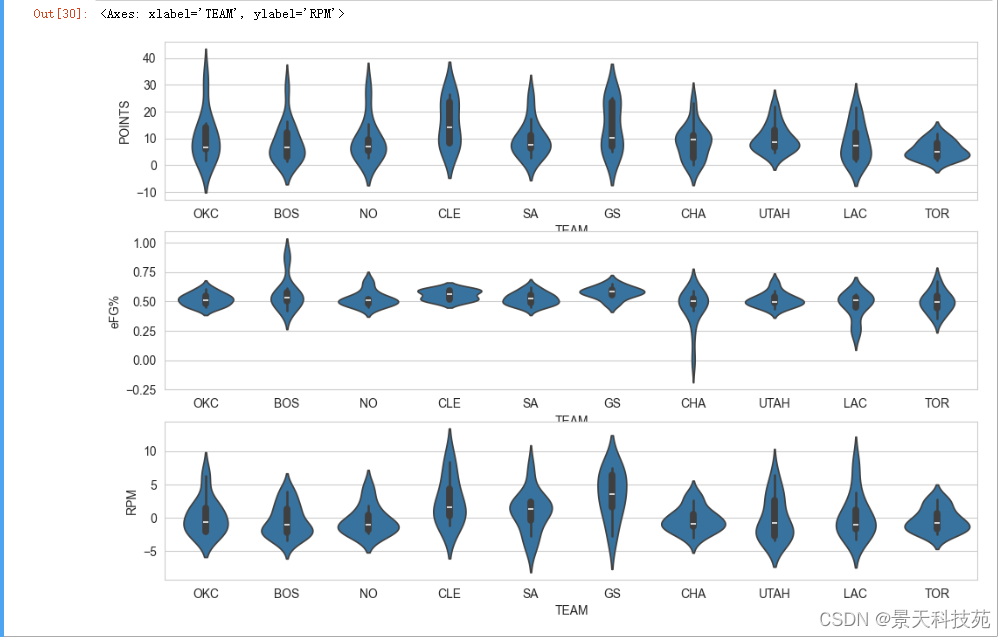
数据分析综合案例讲解,一文搞懂Numpy,pandas,matplotlib,seaborn技巧方法
文章目录 NBA综合案例1 基本数据介绍2.数据相关性3.球员数据分析(1)基本分析(2)薪资最高的10名运动员(3)效率值最高的10名运动员(4)出场时间最高的10名运动员 4.Seaborn常用的三个数…
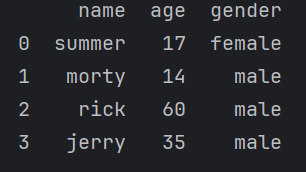
Python中Pandas详解之数据结构
文章目录 Pandas 数据分析Pandas 简介Pandas 安装Series 类型数据Series的创建Series的访问Series 中向量化操作与布尔索引Series的切片Series的缺失值Series的增与删Series的name DataFrame 数据类型DataFrame的创建DataFrame的访问DataFrame的删除DataFrame的添加添加行添加列…
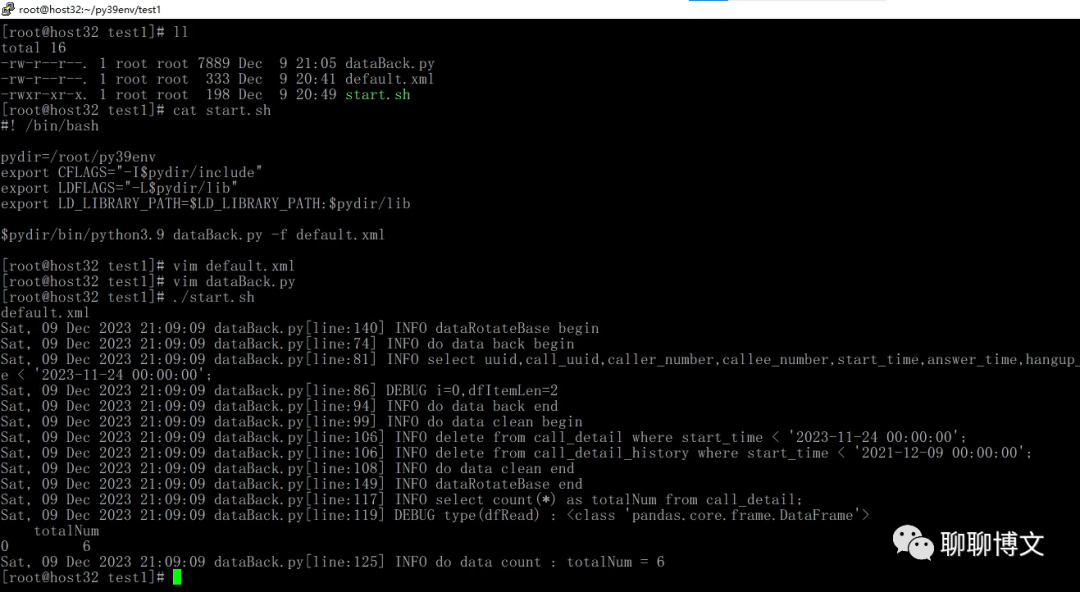
python3使用pandas备份mysql数据表
操作系统 :CentOS 7.6_x64
Python版本:3.9.12
MySQL版本:5.7.38
日常开发过程中,会遇到mysql数据表的备份需求,需要针对单独的数据表进行备份并定时清理数据。
今天记录下python3如何使用pandas进行mysql数据表的备…

2023年12月25日学习总结——MLP
💡我准备每一天都写一个学习总结,周末再把每日的学习总结汇总成专门的文章 🔆我的学习总结主要是为了自己的个人学习,没有商业用途,侵删 okkk开始今日学习 目录 1、今日计划学习内容2、今日学习内容深入学习MLP&#…
pandas用字符串筛选索引发现的问题
import pandas as pd
import numpy as npdf pd.DataFrame({a:np.arange(5),b:np.arange(5),
},index[a,(b),c,b(d),e])df.index.str.contains(b(d))
结果
array([False, False, False, False, False])
奇怪吧,后来查资料说它会把contains里的字符串当做正则表达…
【持更】python数据处理-学习笔记
1、读取excel /csv及指定sheet: pd.read_excel("路径",sheetname"xx") 修改列名df.rename 修改字符串类型到数字 pandas.to_numeric() 2、删除drop、去重drop_duplicates
(1)空值所在行/列 行&am…
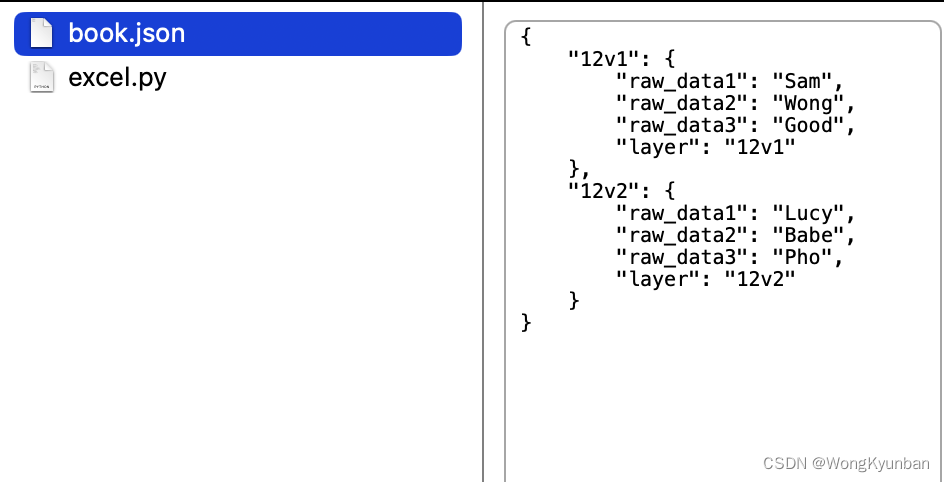
使用pandas将excel转成json格式
1.Excel数据 2.我们想要的JSON格式
{"0": {"raw_data1": "Sam","raw_data2": "Wong","raw_data3": "Good","layer": "12v1"},"1": {"raw_data1": "Lucy…

【神行百里】pandas查询加速之行索引篇
最近进行大数据处理的时候,发现我以前常用的pandas查询方法太慢了,太慢了,真是太慢了,查阅资料,遂发现了一种新的加速方法,能助力我飞上天,和太阳肩并肩,所以记录下来。 1. 场景说明…
python pandas 自用
列1列2列3列4import pandas as pds pd.Series([1, 3, 5, np.nan, 6, 8])pd.DataFrame({A: [1, 2, 3]})dates pd.date_range("20130101", periods6)df pd.DataFrame(np.random.randn(6, 4), indexdates, columnslist("ABCD"))df2 pd.DataFrame( ...: …
【VAR | 时间序列】以美国 GDP 和通货膨胀数据为例的VAR模型简单实战(含Python源代码)
以美国 GDP 和通货膨胀数据为例:
1. 数据集
下载数据我们需要从 FRED 数据库下载美国 GDP 和通货膨胀数据,并将它们存储在 CSV 文件中。可以在 FRED 网站(https://fred.stlouisfed.org/)搜索并下载需要的数据。在这里࿰…
Python数据分析实战:获取数据
这是 利用Excel学习Python 系列的第8篇文章 想用一个完整的案例讲解Python数据分析的整个流程和基础知识,实际上以一个数据集为例,数据集是天池上的一个短租数据集。
先来想一下数据分析的流程,第一步获取数据,因此本节内容就是获…
Python学习笔记(7):数据框
前一篇文章提到了序列,可以理解为Excel里没有列名的一列数据,那么Excel里的由行列组成的表数据是如何对应到Python中的呢?就是今天要说的数据框:DataFrame。
它是由一组数据和一对索引(行索引和列索引)组成的二维数据结构&#x…

作为一名python开发者,想要兼职接单,需要学那些技术?要达到什么水准?为什么要学这些技术?
作为一名Python开发者,学习并且兼职接单可以创造更多的机会和收入。要成为一名具有竞争力的兼职Python开发者,需要学习一系列的技术,并达到一定的水准。本文将详细分析兼职Python开发者需要学习的技术、所需达到的水平,以及为什么…

Python3 df.loc和df.iloc函数用法及提取指定行列位置处数值
关于pandas.dataframe.loc与pandas.dataframe.iloc用法官方说明,见官网。 df.loc和df.iloc函数用法的df,由pandas.read_csv()函数读取文件而来。
1. DataFrame.loc
Access a group of rows and columns by label(s) or a boolean array. .loc[] is pri…
pandas绘图指南
文章目录pandas绘图基本绘图方法plot其他绘图条形图直方图箱型图面积图散点图六边形图饼图绘制缺失数据几个特殊的绘图函数散点图矩阵密度图安德鲁斯曲线平行坐标滞后图自相关图自举图RadViz绘图格式import pandas as pd
import numpy as np
import matplotlib.pyplot as pltpa…
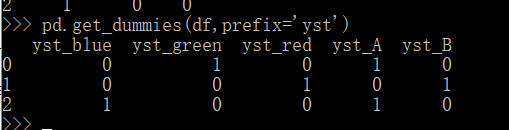
pandas.get_dummies 的使用及含义
get_dummies 是利用pandas实现one hot encode的方式。
get_dummies参数如下:
pandas.get_dummies(data,prefix None,prefix_sep ’_’,dummy_na False,columns None,sparse False…
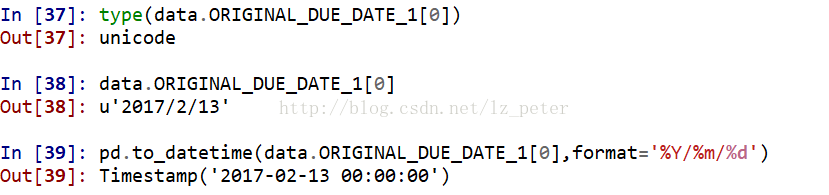
python学习易忘易混淆笔记
文章目录python基础1.range()与np.arange()的区别数据采集(爬虫)可视化matplotlibpyecharts大屏可视化数据预处理pandas时间数据处理pd.to_datetime()建模算法python基础
1.range()与np.arange()的区别
range()返回的是range object,而np.a…
pandas parse_dates参数
parse_dates 表示将某一列设置为 时间类型
df pd.read_csv(comptagevelo20152.csv,\sep,,index_col Date,parse_dates[Date])parse_dates将Date列设置为时间类型 index_col将Date列设置为索引
df.indexDatetimeIndex([‘2015-01-01’, ‘2015-02-01’, ‘2015-03-01’, ‘2…
python学习——字符串序列
目录 1 计算长度 len2 大小写 lower、upper、title、capitalize、swapcase3 字符检索 get、slice4 元素提取 findall、extract5 索引操作 find、index6 字符类型判断,结果一定是True或False7 字符判断 contains、startswith、endswith8 替换 replace9 字符的分割 split、partit…

Pandas 对带有 Multi-column(多列名称) 的数据排序并写入 Excel 中
Pandas 从Excel 中读取带有 Multi-column的数据 正文 正文
我们使用如下方式写入数据:
import pandas as pd
import numpy as npdf pd.DataFrame(np.array([[10, 2, 0], [6, 1, 3], [8, 10, 7], [1, 3, 7]]), columns[[Number, Name, Name, ], [col 1, col 2, co…

Orange3数据转换(数据采样组件)
组件介绍: 固定数据比例(Fixed proportion of data) 返回整个数据的选定百分比
固定样本量(Fixed sample size) 返回选定数量的数据实例,并可以设置 Sample with replacement(替换样本),该替换样本始终从整个数据集中…
LeetCode 2884. 修改列
DataFrame employees ------------------- | Column Name | Type | ------------------- | name | object | | salary | int | ------------------- 一家公司决定增加员工的薪水。
编写一个解决方案,将每个员工的薪水乘以2来 修改 salary 列。
返回结果格式如下示…
深度解析Pandas聚合操作:案例演示、高级应用与实战技巧【第74篇—Pandas聚合】
深度解析Pandas聚合操作:案例演示、高级应用与实战技巧
在数据分析和处理领域,Pandas一直是Python中最受欢迎的库之一。它提供了丰富的数据结构和强大的功能,使得数据清洗、转换和分析变得更加高效。其中,Pandas的聚合操作在数据…
初识Pandas函数是Python的一个库(继续更新...)
学习网页:
Welcome to Python.orghttps://www.python.org/https://www.python.org/https://www.python.org/
Pandas函数库
Pandas是一个Python库,提供了大量的数据结构和数据分析工具,包括DataFrame和Series等。Pandas的函数非常丰富&…
Pandas DataFrame合并a列相同的项,并将相应b列的字符串相加
使用groupby和agg函数合并一个DataFrame中a列相同的项,并将b列的字符串相加,获得一个新的DataFrame,其中:
a列包含原始DataFrame中a列的唯一值,b列包含与每个a值相对应的合并后的b列字符串。
import pandas as pd d…
数据分析-Pandas如何统计数据概况
数据分析-Pandas如何概况的获得统计数据
时间序列数据在数据分析建模中很常见,例如天气预报,空气状态监测,股票交易等金融场景。此处选择巴黎、伦敦欧洲城市空气质量监测 N O 2 NO_2 NO2数据作为样例。
python数据分析-数据表读写到panda…
Pandas.DataFrame.prod() 乘积(累乘积) 详解 含代码 含测试数据集 随Pandas版本持续更新
关于Pandas版本: 本文基于 pandas 2.2.0 编写。
关于本文内容更新: 随着pandas的stable版本更迭,本文持续更新,不断完善补充。
传送门: Pandas API参考目录
传送门: Pandas 版本更新及新特性
传送门&am…
第七章 绘制3D图表和统计地图
7.1 使用mplot3d绘制3D图表
7.1.1 mplot3d概述
mplot3d是matplotlib中专门绘制3D图表的工具包,它主要包含一个继承自Axes的子类Axes3D,使用Axes3D类可以构建一个三维坐标系的绘图区域。matplotlib可以通过两种方式创建Axes3D类的对象:一种方式是Axes3D()方法,另一种方式是…
Python (十四)pandas(二)
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…
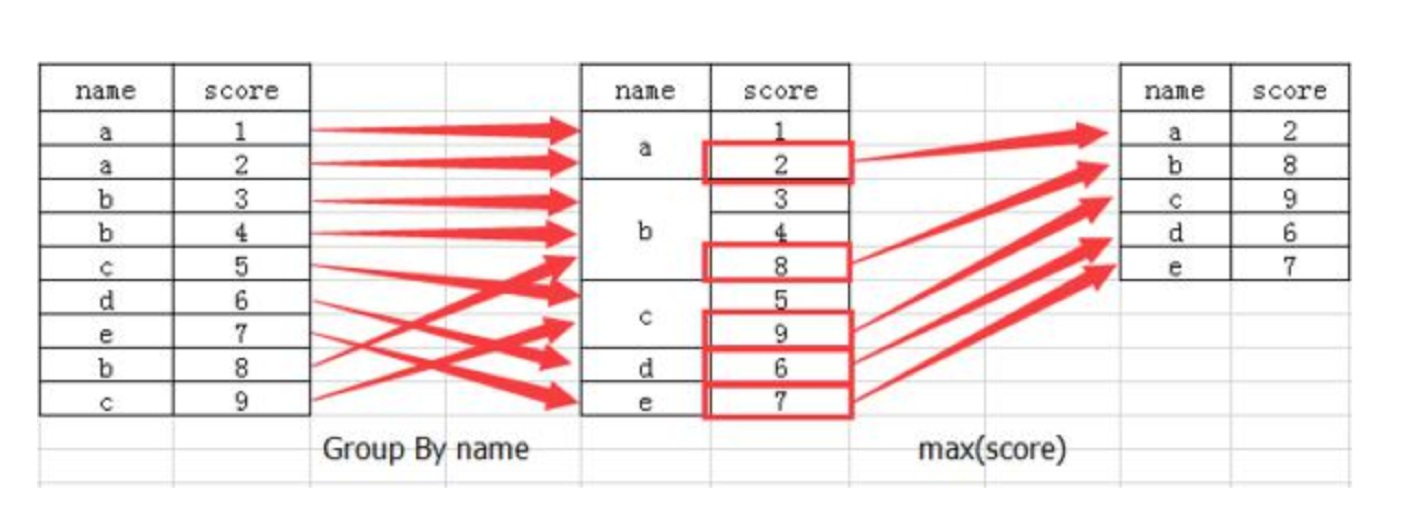
机器学习-pandas(含数据)
pandas
优势:
增强图表可读性便捷的数据处理能力读取文件方便封装了Matplotlib、Numpy的画图和计算
更详细的教程:Pandas 教程 | 菜鸟教程 (runoob.com)
Pandas数据结构
Pandas中一共有三种数据结构,分别为:Series、DataFram…
pandas中merge的用法
https://www.yiibai.com/pandas/python_pandas_merging_joining.html 这个是我在网上看到的最清晰的解释,主要体会例子。
pandas 笔记 date_range
返回固定频率下的datetime
1 使用方法
pandas.date_range(startNone, endNone, periodsNone, freqNone, tzNone, normalizeFalse, nameNone, inclusiveboth, *, unitNone, **kwargs)
2 基本参数
start、end、periods至少需要两个
start生成日期的左边界end生成日期的右边界…

pandas中describe()不采用科学计数法
在pandas中,我们采用pandas中的函数describe()来查询数据的统计信息
data.describe()对于浮点数,describe()查询到的信息往往会用科学计数法显示 为了直观显示数字,不采用科学计数法显示
# 查看数据统计信息
import numpy as np
import pa…
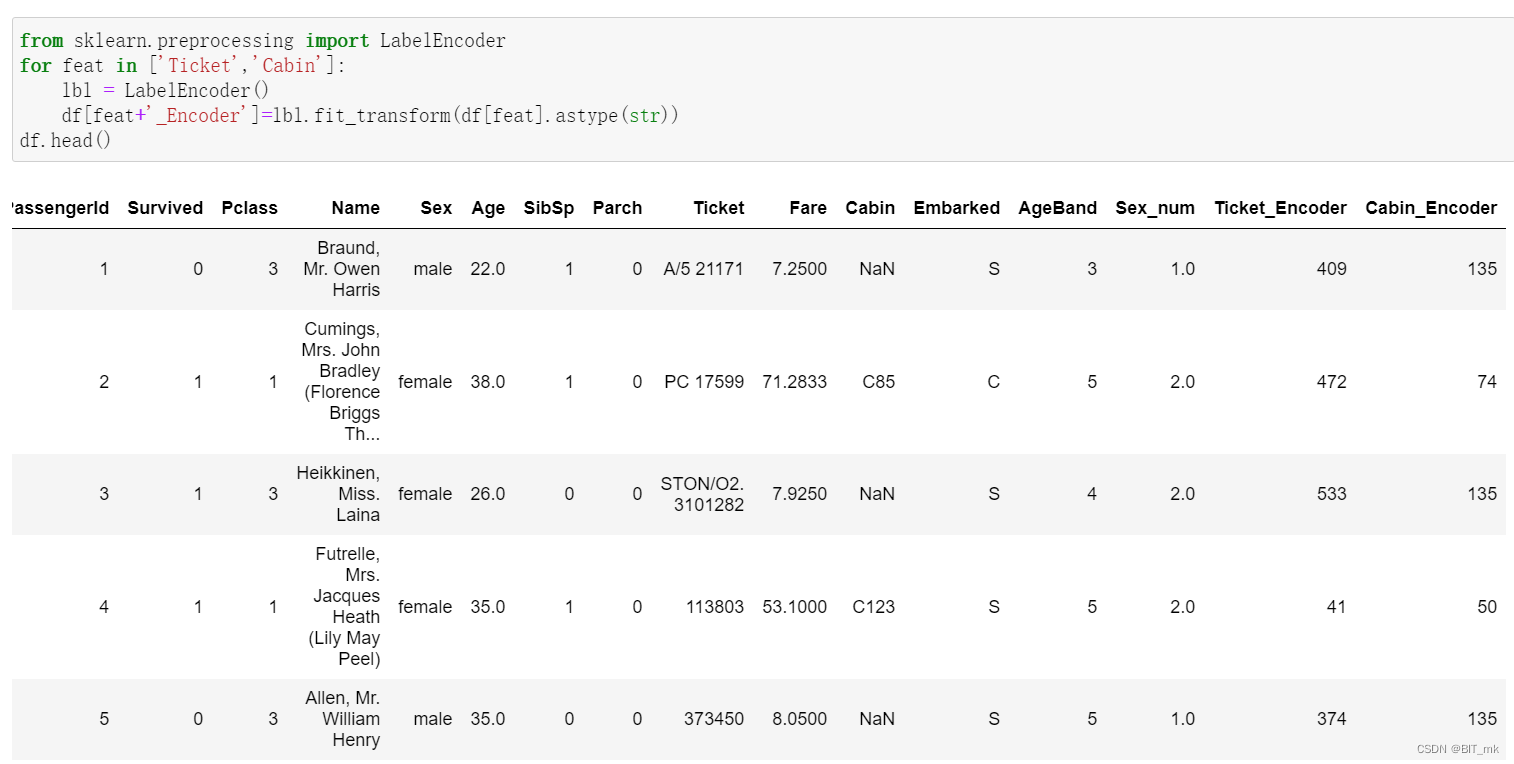
Titanic细节记录一
目录 chunker
header
index_col
names
Series与DataFrame的区别 df.columns
del和drop的区别 reset_index
loc与iloc的区别
不同的排序方式
sort_values
sort_index
DataFrame相加
describe函数查看数据基本信息 查看多个列的数据时使用列表 处理缺失值的几种思路
…

Python自动化办公对每个子文件夹的Excel表加个表头(Excel不同名)(下篇)
点击上方“Python爬虫与数据挖掘”,进行关注 回复“书籍”即可获赠Python从入门到进阶共10本电子书 今 日 鸡 汤 昭阳殿里恩爱绝,蓬莱宫中日月长。 大家好,我是皮皮。 一、前言 上一篇文章,我们抛出了一个问题,这篇文章…
【表格处理】批处理处理Excel文档
这里是记录一下,有可能用到的处理表格的函数以及用法 已知某些参数,想把CVS表格中关于这些数值的这些行保留下来:
import os
import pandas as pd
import torch
import tqdmfile os.listdir(./dataset)#pathname为文件存放位置及文件名称
p…
Pandas 数据清洗和处理
Pandas 数据清洗和处理 文章目录Pandas 数据清洗和处理1 DataFrame 选取奇\偶行1 DataFrame 选取奇\偶行
生成数据:
import pandas as pd
import numpy as np
np.random.seed(1071)
df pd.DataFrame(np.random.randint(1, 30, (7, 2)), columnslist(AB), indexra…
Python 2.x 中如何使用pandas模块进行数据分析
Python 2.x 中如何使用pandas模块进行数据分析
概述: 在数据分析和数据处理过程中,pandas是一个非常强大且常用的Python库。它提供了数据结构和数据分析工具,可以实现快速高效的数据处理和分析。本文将介绍如何在Python 2.x中使用pandas进行数据分析&am…
joblib 并行处理 Pandas 数据
直接使用 apply
import pandas as pddef double_func(data):return pow(data,2)data["double"] data["source"].apply(double_func)并行实现
import pandas as pd
from joblib import Parallel, delayed
from tqdm import tqdm, tqdm_notebooktqdm_note…
Python自动化小技巧16——分类汇总写入excel不同sheet表
案例背景
上了两个月班的社畜博主最近终于有空来总结一下最近写的代码了。
因为上班都是文职工作,天天不是word就是excel就是PPT和pdf....这和什么机器学习还有数据科学不一样,任务更多的是处理实在的文字和表格等格式,按照领导要求来完成&…
如何在控制台查看excel内容
背景
最近发现打开电脑的excel很慢,而且使用到的场景很少,也因为mac自带了预览的功能。但是shigen就是闲不住,想自己搞一个excel预览软件,于是在一番技术选型之后,我决定使用python在控制台显示excel的内容。 具体的需…
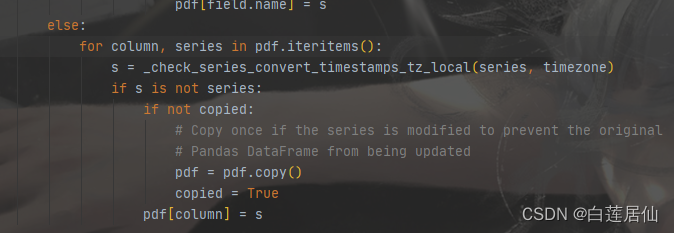
(已解决)PySpark : AttributeError: ‘DataFrame‘ object has no attribute ‘iteritems‘
AttributeError: ‘DataFrame’ object has no attribute ‘iteritems’
原因在使用SparkSession对象中createDataFrame函数想要将pandas的dataframe转换成spark的dataframe时出现的 因为createDataFrame使用了新版本pandas弃用的iteritems(),所以报错 解决办法&…

30 个 Python 技巧,加速你的数据分析处理速度
又到了学习干货的季节~
今天我们就来学习一下python干货~ pandas的下载
使用命令下载:
pip install pandas 或者自行下载whl文件安装
https://www.lfd.uci.edu/~gohlke/pythonlibs/创建DataFrame数据
pd_data pd.DataFrame({"name":["小明&quo…
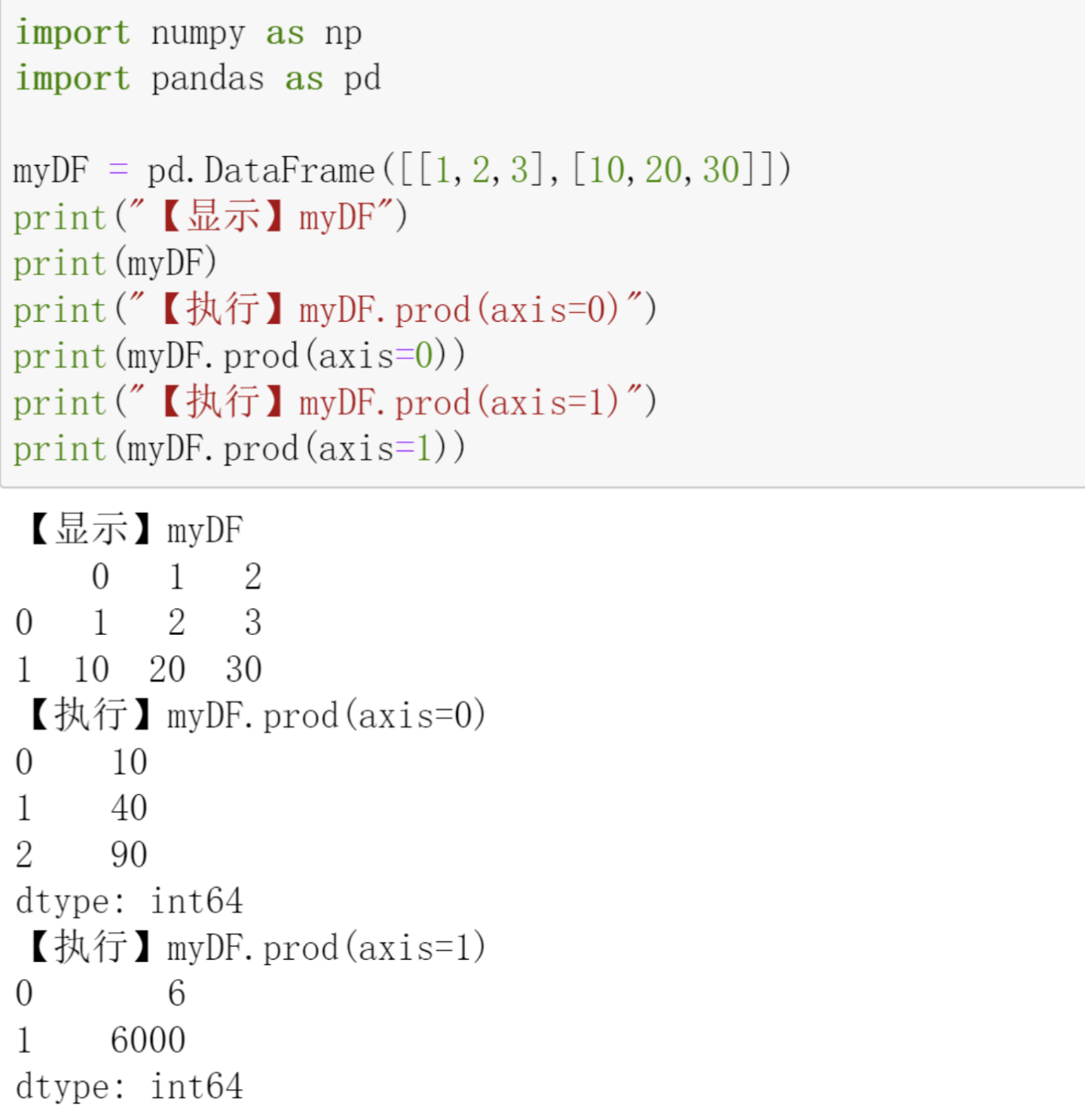
对DataFrame各行列累乘:prod()函数
【小白从小学Python、C、Java】 【Python-计算机等级考试二级】 【Python-数据分析】 对DataFrame各行列累乘 prod()函数
选择题 下列说法错误的是? import numpy as np import pandas as pd myDF pd.DataFrame([[1,2,3],[10,20,30]]) print("【显示】myDF") prin…

数据分析 | Pandas 200道练习题,每日10道题,学完必成大神(5)
文章目录前期准备1. 将create Time列设置为索引2. 生成一个和df长度相同的随机数DataFrame3. 将上一题生成的DataFrame与df合并4. 生成的新的一列new值为salary列减去之前生成的随机数列5. 检查数据中是否含有空值6. 将salary类型转换成浮点数7. 计算salary 大于10000的次数8. …
数据分析——python常用函数(数分入门级框架)
Python(数据分析常用函数)
目录
Python(数据分析常用函数)
一.numpy (数字化python)
1.1数据类型
1.2 ndarry生成
1.3 类型转换
1.4 形状与行列
1.5 数组运算
1.6 逻辑运算
1.7索引与切片&#x…

深入探索Pandas读写XML文件的完整指南与实战read_xml、to_xml【第79篇—读写XML文件】
深入探索Pandas读写XML文件的完整指南与实战read_xml、to_xml
XML(eXtensible Markup Language)是一种常见的数据交换格式,广泛应用于各种应用程序和领域。在数据处理中,Pandas是一个强大的工具,它提供了read_xml和to…
Pandas数据库大揭秘:read_sql、to_sql 参数详解与实战篇【第81篇—Pandas数据库】
Pandas数据库大揭秘:read_sql、to_sql 参数详解与实战篇
Pandas是Python中一流的数据处理库,而数据库则是数据存储和管理的核心。将两者结合使用,可以方便地实现数据的导入、导出和分析。本文将深入探讨Pandas中用于与数据库交互的两个关键方…
pandas/geopandas 笔记:判断地点在不在路网上 不在路网的点和路网的距离
0 导入库
import osimport pandas as pd
pd.set_option(display.max_rows,5)import osmnx as oximport geopandas as gpd
from shapely.geometry import Point
1 读取数据
假设我们有 如下的数据:
1.1 新加坡室外基站位置数据
cell_stationpd.read_csv(outdoor…
python 层次分析(AHP)
文章目录 一、算法原理二、案例分析2.1 构建指标层判断矩阵2.2 求各指标权重2.2.1 算术平均法(和积法)2.2.2 几何平均法(方根法) 2.3 一致性检验2.3.1 求解最大特征根值2.3.2 求解CI、RI、CR值2.3.3 一致性判断 2.4 分别求解方案层…
Pandas读取两个excel并join
Pandas 的 join就是merge,代码如下
import pandas as pd #读取两张表 dfpd.read_excel(“左表”) #读取右表的第三个sheet中的数据 df2pd.read_excel(“右表”,sheet_name“Sheet3”) #以左表为主表,左连接 outpd.merge(df ,df2 ,on‘query’ ,how‘lef…

开源的 Python 数据分析库Pandas 简介
阅读本文之前请参阅-----如何系统的自学python Pandas 是一个开源的 Python 数据分析库,它提供了高性能、易用的数据结构和数据分析工具。Pandas 特别适合处理表格数据,例如时间序列数据、异构数据等。以下是对 Pandas 的简明扼要的介绍,包括…
Python进阶学习:Pandas--向DataFrame中指定位置添加一列或多列
Python进阶学习:Pandas–向DataFrame中指定位置添加一列或多列 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程ὄ…
Pandas学习(完成文件写入、追加写入、读取操作)
问题引入 现在有这么一个需求 我要对我的很多设备进行快照处理,打完快照之后需要记录我的设备IP和快照时间 当我们解决了需求的其他内容,只剩记录信息的时候,可以怎么做呢 这时候就可以引入我们的pandas模块啦,它对数据进行一系列…

04_python数据分析之pandas
python数据分析之pandas1. 为什么要学习 pandas ?2. 什么是 pandas ?3. pandas 的常用数据类型 ?3.1 pandas之Series3.2 panda 之读取外部数据3.3 panda 之 DataFrame3.3.1 DataFrame创建3.3.2 DataFrame的基础属性和常用方法3.3.…
大数据时代BI平台何去何从
信息化时代的高速发展,使得大数据的作用深入人心。大数据也成为当下几大热点词汇之一,企业每天产生数以万计的数据都需要对数据进行处理,数据处理的方法也在不断地与时俱进。就现如今的发展趋势而言,大数据技术的发展如火如荼。大…

Pandas数据清洗和常用函数
数据清洗
数据清洗是对一些没用的数据进行处理的过程。
当数据出现确实、数据格式错误、错误数据或重复数据的情况,如果我们想要分析的更加准确,就要对没用的数据进行处理。
此时我们学习采用菜鸟教程的数据作为案例,如下图所示。 在途中包…
DataFrame.plot函数详解(五)
DataFrame.plot函数详解(五)
散点图和箱体图实例
1. scatter DataFrame.plot.scatter(x, y, sNone, cNone, **kwargs) c: 是每个点的颜色,可以是一个值,也可以是数组值 s: 是每个点的大小,可以…
【LeetCode】30 天 Pandas 挑战
一、笔记
1.对某列进行筛选
df[(df[column1]条件1) | (df[column2]条件2) & (df[column3]条件3)][[columns]]真题: (一)条件筛选——1.大的国家(一)条件筛选——2.可回收且低脂的产品(一)…
pandas创建批量文件夹并拆分文件
import pandas as pd
import numpy as np
from datetime import date
import os
filepath/Users/kangyongqing/Documents/kangyq/202206/季度评级月数据支持/2023年薪改测算/23年薪改文件/file薪资变化教师档案2023-08-25.xlsx
#当前季度的实际级别数据dtpd.read_excel(filepat…
![[Pandas] 求百分比并添加百分(%)号](https://img-blog.csdnimg.cn/5c70489ea9694cd39bb21134e0c805b4.png)
[Pandas] 求百分比并添加百分(%)号
导入数据
import pandas as pddf pd.DataFrame(data{orders: [2130,5102,3256,1297,1918,786],repeat_orders: [73,158,89,30,49,18]})
df df[repetition_rate] df[repeat_orders] / df[orders]
df df[repetition_rate] df[repetition_rate].apply(lambda x: format(x, .2…
Python3 pandas入门
pandas的数据结构介绍
pandas有两个主要数据结构:Series和DataFrame。
Series
Series是一种类似一维数组的对象,由一组数据和与之相关的索引组成。
创建Series
第一种方式,直接传入一个列表或元组等序列数据,如果没有指定索引…

大数据(六):Pandas的基础应用详解(三)
专栏介绍
结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来!
全部文章请访问专栏:《Python全栈教…

Python数据分析案例30——中国高票房电影分析(爬虫获取数据及分析可视化全流程)
案例背景
最近总看到《消失的她》票房多少多少,《孤注一掷》票房又破了多少多少.....
于是我就想自己爬虫一下获取中国高票房的电影数据,然后分析一下。
数据来源于淘票票:影片总票房排行榜 (maoyan.com) 爬它就行。 代码实现
首先爬虫获…
Pandas 之 merge
merge的作用:
merge函数在Python的pandas库中的作用是用来合并两个或多个DataFrame数据表,依据指定的一个或多个键(通常是列名)进行连接操作[1]。
merge函数可以有多种连接类型(如内连接inner、左连接left、右连接ri…

Python利用pandas对数据进行特定排序详解
概要
在数据分析和处理过程中,排序是一项常见而重要的操作。Python中的pandas库提供了丰富的功能,可以方便地对数据进行各种排序操作。本文将详细介绍如何利用pandas对数据进行特定排序,包括基本排序、多列排序、自定义排序规则等方面的内容…
将Lambda函数应用于Pandas DataFrame
在Python Pandas中,我们可以在需要时自由添加不同的函数,如lambda函数,排序函数等。我们可以将lambda函数应用于Pandas数据框的列和行。 语法:lambda参数:表达式 一个匿名函数,我们可以立即传入,…
学会这 29 个 函数,你就是 Pandas 专家
Pandas 无疑是 Python 处理表格数据最好的库之一,但是很多新手无从下手,这里总结出最常用的 29 个函数,先点赞收藏,留下印象,后面使用的时候打开此文 CTRL F 搜索函数名称,检索其用法即可。 文章目录技术提…
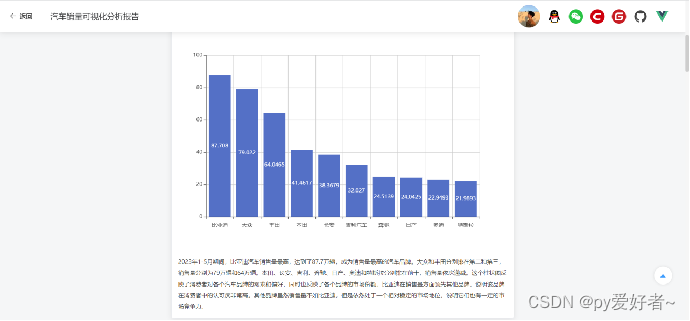
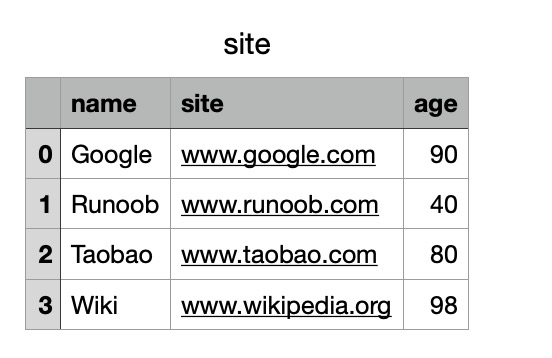
Pandas 数据结构 – Pandas CSV 文件
Pandas CSV 文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、…

Leetcode—2881. 创建新列【简单】
2024每日刷题(一零九)
Leetcode—2881. 创建新列 实现代码
import pandas as pddef createBonusColumn(employees: pd.DataFrame) -> pd.DataFrame:employees[bonus] employees[salary] * 2return employees 运行结果 之后我会持续更新…

《Pandas 简易速速上手小册》第8章:Pandas 高级数据分析技巧(2024 最新版)
文章目录 8.1 使用 apply 和 map 函数8.1.1 基础知识8.1.2 重点案例:客户数据清洗和转换8.1.3 拓展案例一:产品评分调整8.1.4 拓展案例二:地址格式化 8.2 性能优化技巧8.2.1 基础知识8.2.2 重点案例:大型销售数据分析8.2.3 拓展案…
sklearn.preprocessing 标准化、归一化、正则化
文章目录 数据标准化的原因作用归一化最大最小归一化针对规模化有异常的数据标准化线性比例标准化法log函数标准化法正则化Normalization标准化的意义数据标准化的原因 某些算法要求样本具有零均值和单位方差;需要消除样本不同属性具有不同量级时的影响:
① 数量级的差异将导…
Python高级语法与正则表达式
Python提供了 with 语句的写法,既简单又安全。
文件操作的时候使用with语句可以自动调用关闭文件操作,即使出现异常也会自动关闭文件操作。
# 1、以写的方式打开文件
with open(1.txt, w) as f:# 2、读取文件内容f.write(hello world)
生成器的创建方…
sklearn:机器学习 分类特征编码category_encoders
文章目录 category_encoders简介OrdinalEncoder 序列编码OneHotEncoder 独热编码TargetEncoder 目标编码Binary Encoder 二进制编码BaseNEncoder 贝叶斯编码LeaveOneOutEncoder 留一法HashingEncoder 哈希编码CatBoostEncoder catboost目标编码CountEncoder 频率编码WOEEncoder…
数据分析 — Pandas 分组聚合
目录 一、函数应用和映射1、apply2、map 二、汇总和描述统计1、计算平均值2、计算中位数3、计算总和4、找到最小值5、找到最大值6、计算标准差7、计算方差8、计算非空值的数量9、生成摘要统计信息10、计算唯一值的频率 三、str 属性1、str.len()2、str.lower() 和 str.upper()3…
【Pandas 入门-5】Pandas 画图
Pandas 画图
除了结合 matplotlib 与 seaborn 画图外,Pandas 也有自己的画图函数plot,它的语法一般为:
DataFrame.plot(xNone,yNone, kindline,subplotsFalse, titleNone)x横坐标数据y纵坐标数据kind默认是线图,还可以是‘bar’…
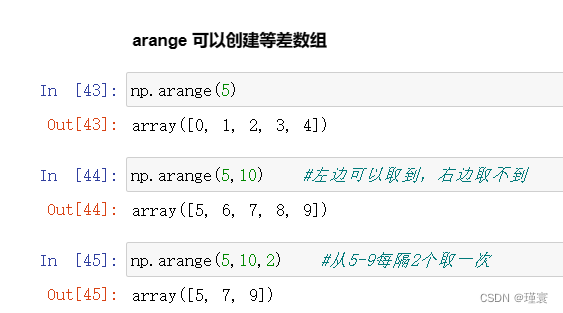
Numpy数组(随时更新)
一、Numpy数组对象的重要属性
#导入库
import numpy as npdata np.arange(12).reshape(4,3)data2 np.arange(24).reshape(3,4,2) #ndim维度个数data.ndimdata2.ndim #shape形状几行几列 数组的维度data.shapedata2.shape#size数组的总个数data.sizedata2.size #dtype数组元素的…

Python学习笔记(3):列表
写在前面
这节内容是Python基础知识中的数据结构,没看过前面内容的童鞋可以复习一下:
从Excel的数据类型说Python
数据结构会分4个小节的内容来写,首先来认识第一种结构——列表。
列表(list),是用方括…

Python3:我低调的只用一行代码,就导入Python所有库!
一行代码导入python所有库1、引言2、Pyforest2.1 Pyforest 介绍2.2 Pyforest 安装与使用2.2.1 安装2.2.2 使用3、总结1、引言
今天我们来分享一个懒人库:Pyforest。 小屌丝:鱼哥,今天啥情况,你突然分享这个库? 小鱼&a…
(3)原神角色数据分析-3
绘图类 在名为“WRITEPHOT.py”的文件中,定义如下绘图方式,则在主页面(app.py)文件中,可通过如下方式调用:
from WRITEPHOTO import WriteScatter,WriteFunnel,WriteBarData,WritePie,WriteLineBar
代码如下:
"…

pandas读取文件的时候出现‘OSError: Initializing from file failed’
报错原因: pandas.read_csv() 报错 OSError: Initializing from file failed,一般由两种情况引起:一种是函数参数为路径而非文件名称,另一种是函数参数带有中文。 原代码:
data pd.read_csv(csv文件.csv)
data导入文…
pandas入门(持续更新)
Python 2.7 IDE Pycharm Pandas 0.18.0 应该每天离目标更近一点首先
推荐一下IDE,用的最顺手的是Pycharm,再配合anaconda2,简直完美,什么科学计算库都有,numpy,scipy,matplotlib应有尽有&…

python读写数据读写csv文件--pandas用法
python中数据处理是比较方便的,经常用的就是读写文件,提取数据等,本博客主要介绍其中的一些用法。Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
…
Python数据攻略-Pandas与API数据交互
API数据在现代数据分析中的究竟有多重要?在当今的数据驱动世界中,API(应用程序编程接口)扮演着至关重要的角色。简单来说API就是一种让两个不同的软件应用进行交流的方式。它们通常用于获取网络上的数据。例如股票分析平台可能会使用API来实时获取股票价格;或者在社交媒体…

Python安装和环境配置教程
进官网根据不同的操作系统,下载适合自己的编译环境(在百度里直接输入Python)
选择安装包(我选择的是3.8.0版本) python官方下载目录中有好多种安装方式,一般情况选择Windows x86-64 executable installer …
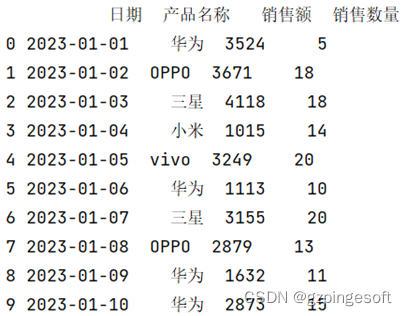
Pandas数据处理分析系列3-数据如何预览
Pandas-数据预览
Pandas 导入数据后,我们通常需要对数据进行预览,以便更好的进行数据分析。常见数据预览的方法如下:
①head() 方法 功能:读取数据的前几行,默认显示前5行 语法结构:df.head(行数)
df1=pd.read_excel("销售表.xlsx",sheet_name="手机销…
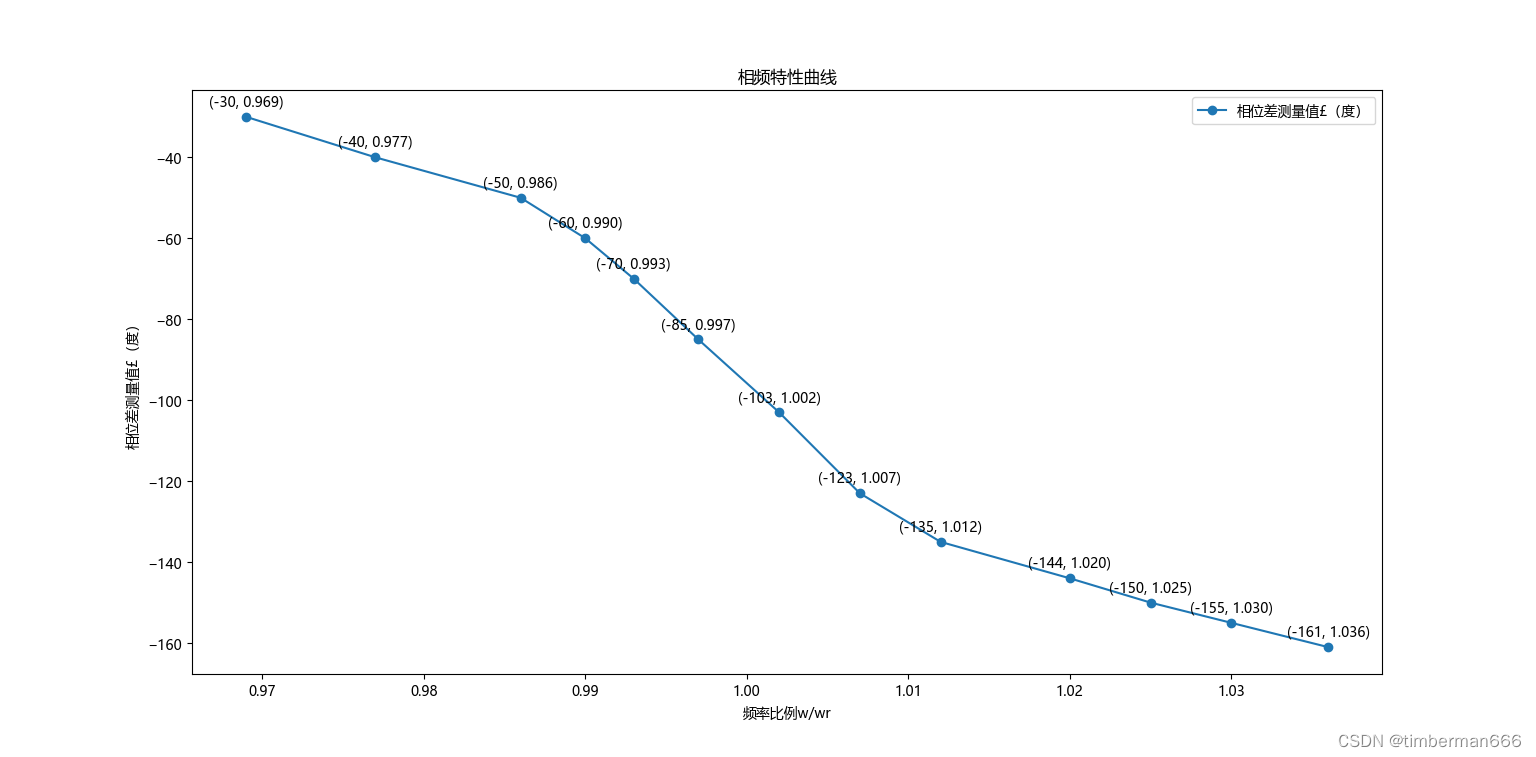
Python Pandas数据处理作图——波尔共振实验
import matplotlib.pyplot as plt
import pandas as pd
from pylab import mplmpl.rcParams["font.sans-serif"] ["SimHei"]data {频率比例w/wr: [1.036, 1.030, 1.025, 1.020, 1.012, 1.007, 1.002,0.997,0.993,0.990,0.986,0.977,0.969],振幅测量值θ&…
Pandas pivot - ValueError: Index contains duplicate entries, cannot reshape
pivot()报错
在使用pivot()进行长表转宽表时,会出现如下错误:
ValueError: Index contains duplicate entries, cannot reshape例:
// For an Example
df pd.DataFrame({"foo": [one, one, two, two],&q…
第九章:最新版零基础学习 PYTHON 教程—Python 元组(第四节 -Python连接元组的方法)
很多时候,在处理记录时,我们可能会遇到需要添加两条记录并将它们存储在一起的问题。这需要串联。由于元组是不可变的,因此这个任务变得不太复杂。让我们讨论执行此任务的某些方法。
目录
Pandas处理异常值的两种方法
使用方法:只需使用pandas读取csv、txt、excel等文件,并调用下列函数即可。
# 一、异常值检测
# 1、使用平均数 - 2 * 标准差 检测异常值def mean_median(df):for i in df.columns:mean df[i].mean()std df[i].std()top_num mean 2 * stdbottom_num …
pandas选择行和列
在Pandas中,选择行和列的基本原理是通过标签或位置进行索引。以下是一些常见的语法: 选择列: 通过列名:data[column_name] 或 data.column_name通过多个列名:data[[column_name1, column_name2]] 选择行: 通过行号:da…
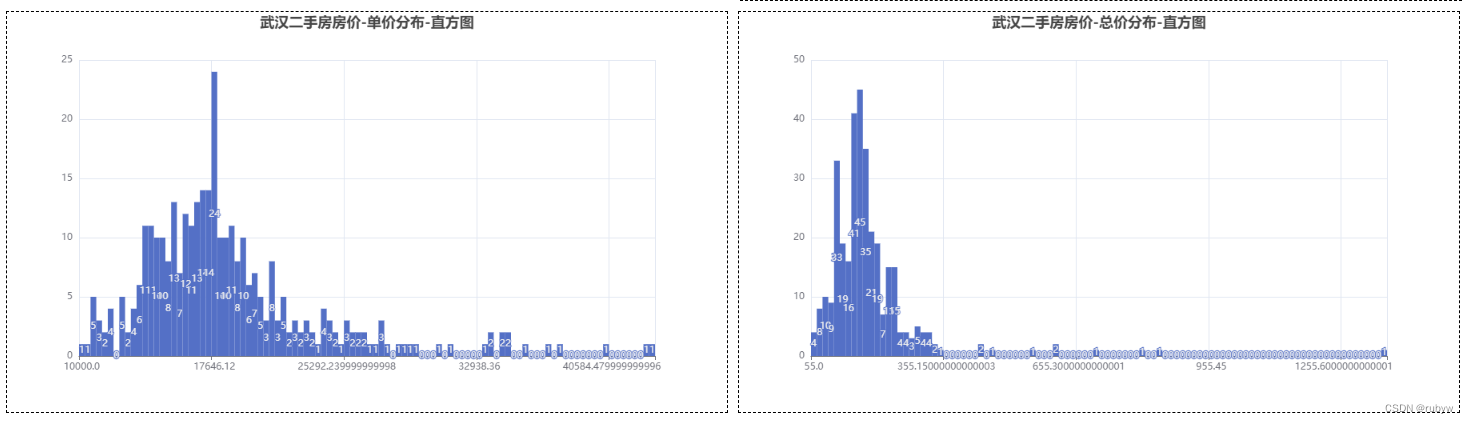
Python通过pyecharts对爬虫房地产数据进行数据可视化分析(一)
一、背景 对Python通过代理使用多线程爬取安居客二手房数据(二)中爬取的房地产数据进行数据分析与可视化展示 我们爬取到的房产数据,主要是武汉二手房的房源信息,主要包括了待售房源的户型、面积、朝向、楼层、建筑年份、小区名称…
sort_values()的用法
sort_values() 是一个用于排序数据的 Pandas 函数,主要用于对 DataFrame 或 Series 中的值进行排序。以下是它的一般用法: 在 DataFrame 上的用法: DataFrame.sort_values(by, axis0, ascendingTrue, inplaceFalse, ignore_indexFalse) 在 Se…
![解决Pandas KeyError: “None of [Index([...])] are in the [columns]“问题](https://img-blog.csdnimg.cn/991e1fa4424b4a2ba2d570da6c868075.png)
解决Pandas KeyError: “None of [Index([...])] are in the [columns]“问题
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…
Python 读写 Excel 文件库推荐和使用教程
文章目录 前言Python 读写 Excel 库简介openpyxl 处理 Excel 文件教程pandas 处理 Excel 文件教程总结 前言
Python 读写 Excel 文件的库总体看还是很多的, 各有其优缺点, 以下用一图总结各库的优缺点, 同时对整体友好的库重点介绍其使用教程…
[黑马程序员Pandas教程]——DataFrame查询数据
目录:
学习目标获取DataFrame子集的基本方法 从前从后取多行数据 默认获取前5行df.head()默认获取倒数5行df.tail()获取一列或多列数据 获取一列数据df[col_name]等同于df.col_name获取多列数据df[[col_name1,col_name2,...]]布尔值向量获取数据行 布尔值列表取出对…
Python numpy数据结构 学习笔记
一、概念介绍
numpy是Python的一个扩充程序库,支持高阶大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
对于数据的运算,用矩阵会比python自带的字典或者列表快好多
主要应用有:数据分析机器学习深度学习二、…
pandas Excelwriter, writer.save() 输出xlsx导致文件只读的问题
writer.save() 已调整过了,请使用 writer.close() writer pd.ExcelWriter(标准集统计情况.xlsx)
xxxxxxx.to_excel(writer,标准集统计情况)
writer.close()
print (已保存标准集统计情况)

【100天精通Python】Day55:Python 数据分析_Pandas数据选取和常用操作
目录
Pandas数据选择和操作
1 选择列和行
2 过滤数据
3 添加、删除和修改数据 4 数据排序 Pandas数据选择和操作 Pandas是一个Python库,用于数据分析和操作,提供了丰富的功能来选择、过滤、添加、删除和修改数据。
1 选择列和行
Pandas 提供了多种…
Python中使用openpyxl和pandas库操作 Excel 表格
在Python中,可以使用多种库来操作Excel表格,其中最常用的是openpyxl和pandas库。下面我将详细解释这两个库的使用方法: openpyxl库: 安装库:使用pip install openpyxl命令安装openpyxl库。导入库:在Python脚…
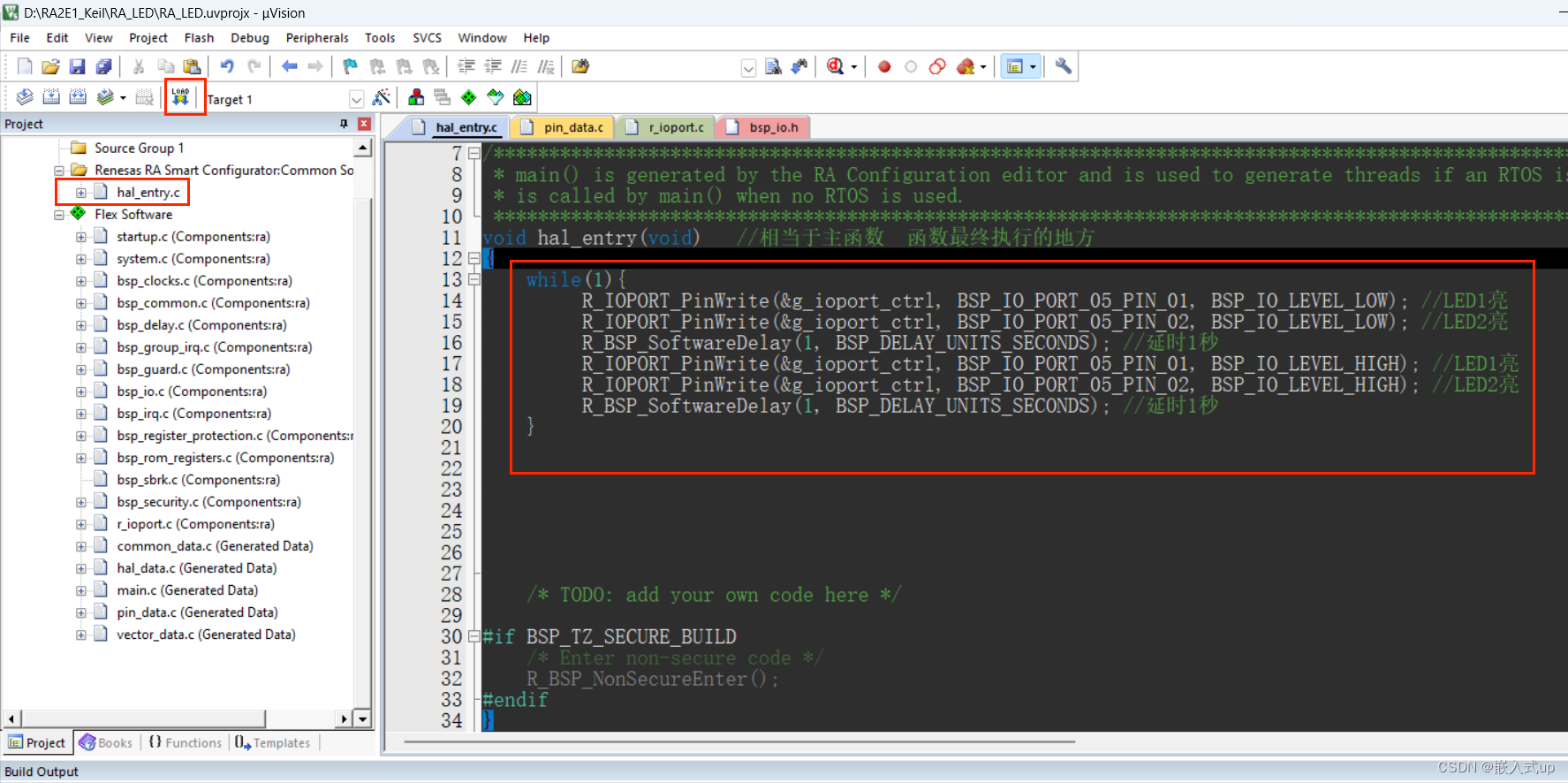
【致敬未来的攻城狮计划】— 连续打卡第十一天:FSP固件库开发点亮第一个灯。
系列文章目录 1.连续打卡第一天:提前对CPK_RA2E1是瑞萨RA系列开发板的初体验,了解一下 2.开发环境的选择和调试(从零开始,加油) 3.欲速则不达,今天是对RA2E1 基础知识的补充学习。 4.e2 studio 使用教程 5.…

Pandas的数据结构
Pandas的数据结构
处理CSV 文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
Pan…
机器学习 - Pandas 练习, 常见功能查阅
机器学习记录
Pandas
安装 pandas 库:
conda install pandas数据
git clone https://github.com/KeithGalli/pandas.git练习
import pandas as pddata_dir "/data_dir"df pd.read_csv(f{data_dir}/pandas/pokemon_data.csv)
df.shape(800, 12)df.head()#NameT…

【数据分析之道-Pandas(一)】Series操作
文章目录 专栏导读1、Series简介2、创建Series3、Series索引4、Series切片 专栏导读 ✍ 作者简介:i阿极,CSDN Python领域新星创作者,专注于分享python领域知识。 ✍ 本文录入于《数据分析之道》,本专栏针对大学生、初级数据分析工…

【建议收藏】Pandas(一)——初见Series
文章目录 📚引言📖库的安装以及一些说明📑库的安装📑一些说明 📖Series📑创建一个Series🔖从列表创建Series🔖从字典创建Series🔖标量创建Series 📑Series的特…
业务数据分析最佳案例!旅游业数据分析!⛵
💡 作者:韩信子ShowMeAI 📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40 📘 本文地址:https://www.showmeai.tech/article-detail/388 📢 声明:版权所有,转…
python pandas怎么修改Excel表格字体颜色?
在pandas中,可以通过样式设置来修改Excel表格的字体颜色。具体步骤如下:
第一步,读取Excel表格数据到DataFrame:
import pandas as pd df pd.read_excel(your_file.xlsx)
第二步,创建一个Styles对象,并设置字体颜色:
fro…
Pandas中你一定要掌握的时间序列相关高级功能
💡 作者:韩信子ShowMeAI 📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40 📘 本文地址:https://www.showmeai.tech/article-detail/389 📢 声明:版权所有,转…
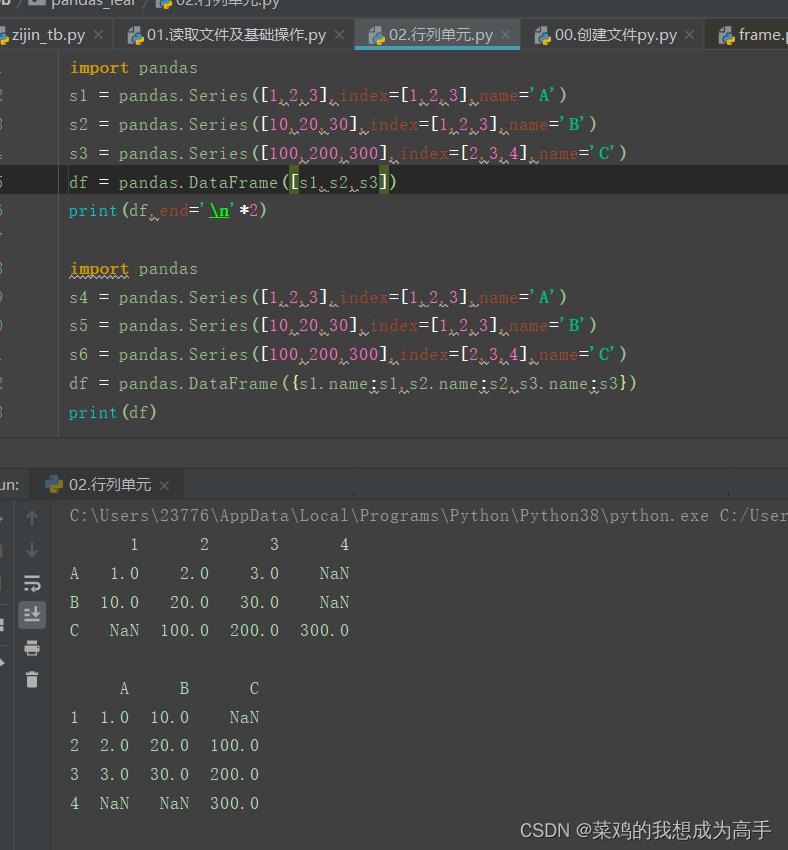
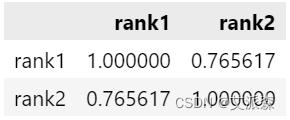
基于五等均分法和Bob Stone法衡量RFM顾客价值
最近学习了衡量RFM模型的两种顾客价值的方法,即五等均分法和Bob Stone法。仅以此博客记录我的学习过程,后序学习到了其他方法再来补充。关于RFM实战案例可参考我的其他文章大数据分析案例-基于RFM模型对电商客户价值分析
大数据分析案例-用RFM模型对客户…

Python~Pandas 小白避坑之常用笔记
Python~Pandas 小白避坑之常用笔记 提示:该文章仅适合小白同学,如有错误的地方欢迎大佬在评论处赐教 文章目录Python~Pandas 小白避坑之常用笔记前言一、pandas安装二、数据读取1.读取xlsx文件2.读取csv文件三、重复值、缺失值、异常值处理、按行、按列剔…

DataFrame API入门操作及代码展示
文章目录DataFrame风格编程DSL风格编程代码示例相关API相关代码示例SQL风格编程代码示例相关API相关代码Fucntions包基于SparkSQL的WordCount代码编写DataFrame风格编程
DataFrame支持两种风格进行编程 DSL风格SQL风格 DSL称之为领域特定语言,其实就是指DataFrame特…

Pandas 替换 NaN 值
替换Pandas DataFram中的 NaN 值
问题
NaN 代表 Not A Number,是表示数据中缺失值的常用方法之一。它是一个特殊的浮点值,不能转换为 float 以外的任何其他类型。NaN 值是数据分析中的主要问题之一。为了得到理想的结果,对 NaN 进行处理是非…
实战四十六:基于LightGBM的广告点击预测 代码+数据
配库:
1. 读取原始数据, 将时间信息分解为天和分钟
2. 特征工程
3. 五折交叉验证训练模型
4. 特征重要性
5. 做出最终预测

实用技巧盘点:Python和Excel交互的常用操作
大家好,在以前,商业分析对应的英文单词是Business Analysis,大家用的分析工具是Excel,后来数据量大了,Excel应付不过来了(Excel最大支持行数为1048576行),人们开始转向python和R这样…
02- pandas 数据库 (数据库)
pandas 数据库重点: pandas 的主要数据结构: Series (一维数据)与 DataFrame (二维数据)。 pd.DataFrame(data np.random.randint(0,151,size (5,3)), # 生成pandas数据 index [Danial,Brandon,softpo,Ella,Cindy], # 行索引 …
Pandas 删除 DataFrame 列,就这么简单!
Pandas 是 Python 中最重要的数据处理库之一,使用 Pandas 我们可以高效地对二维表格型的数据进行处理与分析。在对 DataFrame 进行操作的过程中,常常需要删除某些列。本文将跟读者分享 Pandas 删除 DataFrame 列的几种简单方法。
1. 使用 drop() 方法&a…
Pandas Dataframe 的学习笔记
Pandas Dataframe 的学习笔记 0. Pandas 简介1. 为什么要用 Pandas?2. Series3. DataFrame3-1. 创建 DataFrame3-2. 选择数据3-3. 数据过滤3-4. 修改 DataFrame3-5. 数据清洗3-6. 数据合并3-7. info()3-8. head()3-9. tail()3-10. fillna() 0. Pandas 简介
想象一下…
轻松掌握!Pandas的数据添加技巧,3秒学会更高效的方法
在Pandas中,如果你想高效地向一个DataFrame添加一行数据,千万不要使用.append()方法!因为这种方法需要创建新的对象然后再赋值,效率较低,尤其是DataFrame较大时。 本文将介绍3种Pandas添加一行数据更高效的方法&#x…
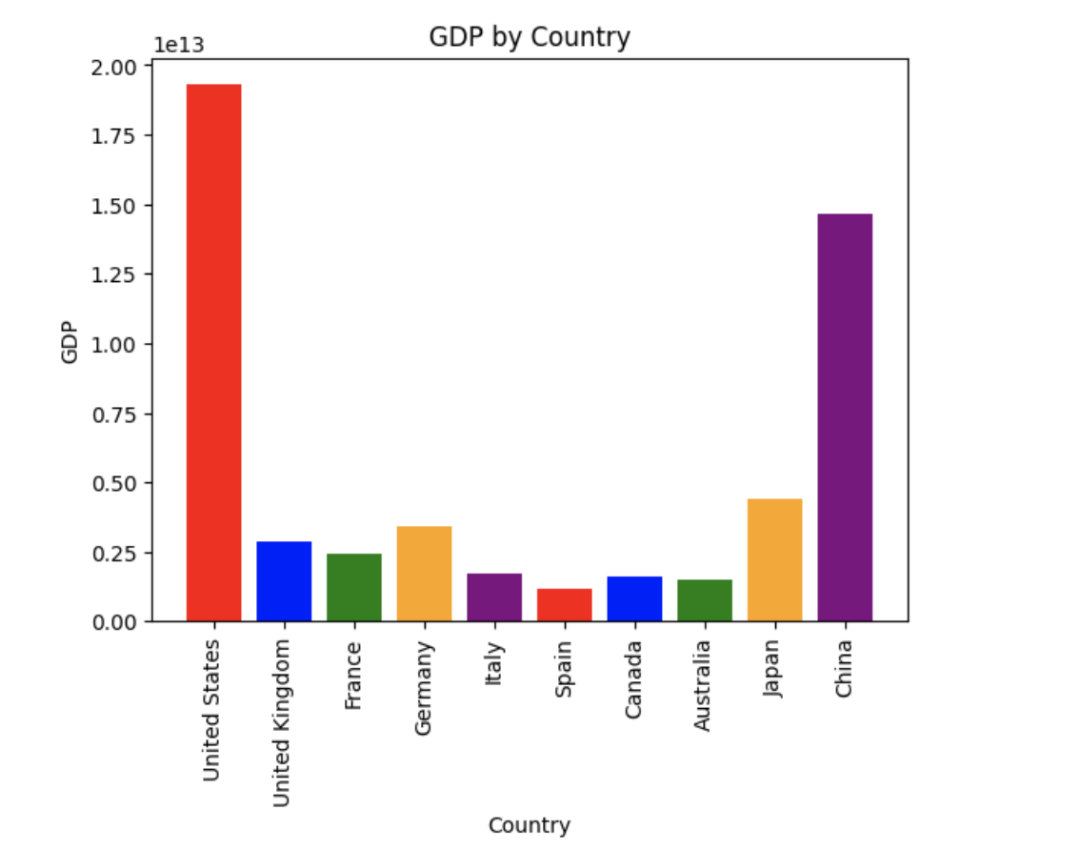
Pandas + ChatGPT 超强组合,pandas-ai :交互式数据分析和处理新方法
Python Pandas是一个为Python编程提供数据操作和分析功能的开源工具包。这个库已经成为数据科学家和分析师的必备工具。它提供了一种有效的方法来管理结构化数据(Series和DataFrame)。 在人工智能领域,Pandas经常用于机器学习和深度学习过程的预处理步骤。Pandas通过…
AI一点通:使用 ColumnTransformer 转换 Pandas DataFrame 的一个或多个列
在处理表格数据时,常常需要对一个或多个列进行转换以使它们更适合于分析或建模。在许多情况下,可以使用 Pandas 库轻松完成这些转换。然而,在处理大型数据集或构建机器学习管道时,使用 scikit-learn 的 ColumnTransformer 类来将转…

【机器学习】数据清洗——基于Pandas库的方法删除重复点
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…
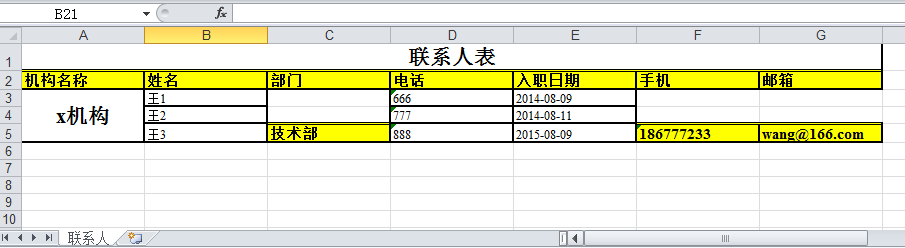
python中第三方库xlrd和xlwt的使用教程
excel文档名称为联系人.xls,内容如下:
一、xlrd模块用法
1.打开excel文件并获取所有sheet
import xlrd# 打开Excel文件读取数据
data xlrd.open_workbook(联系人.xls)sheet_name data.sheet_names() # 获取所有sheet名称
print(sheet_name) # [银…

【100天精通Python】Day57:Python 数据分析_Pandas数据描述性统计,分组聚合,数据透视表和相关性分析
目录
1 描述性统计(Descriptive Statistics)
2 数据分组和聚合
3 数据透视表
4 相关性分析 1 描述性统计(Descriptive Statistics) 描述性统计是一种用于汇总和理解数据集的方法,它提供了关于数据分布、集中趋势和…

pandas读取一个 文件夹下所有excel文件
我这边有个需求,是要求汇总一个文件夹所有的excel文件, 其中有.xls和 .xlsx文件,同时还excel文件中的数据可能还不一致,会有表头数据不一样需要一起汇总。
首先先遍历子文件夹并读取Excel文件: 使用os库来遍历包含子文…
Pandas 数据变形和模型分析
数据概念
数据比对
在本练习中,我们使用灵活的比较技术对不同的DataFrame进行比较
import pandas as pd
import randomrandom.seed(123)
list1 [[A]*3,[B]*5,[C]*7]
charlist [x for sublist in list1 for x in sublist]
random.shuffle(charlist)
ser1 pd.Se…
Axure原型设计累加器计时器设计效果(职业院校技能大赛物联网技术应用项目原型设计题目)
目录
前言
一、本题实现效果
二、操作步骤
1.新建文件
2.界面设计
2.1文本框
2.2 按钮
2.3设计界面完成
3.交互
3.1启动交互设置
3.2 分别设置三个属性
3.2.1 设置值为“0” 3.2.2 文字于文本框 3.2.3 获取焦点时
3.3 停止按钮的交互动作 3.3.1 设置变量值
3.4 重…
pyspark.sql.dataframe.DataFrame 怎么转pandas DataFrame
pyspark.sql.dataframe.DataFrame 怎么转pandas DataFrame
要将 PySpark 的 pyspark.sql.dataframe.DataFrame 转换为 Pandas DataFrame,可以使用 toPandas() 方法。以下是一个示例:
from pyspark.sql import SparkSession# 创建 SparkSession 对象
sp…
Python进阶复习-Pandas库
目录 使用场合对象创建Series对象DataFrame对象Numpy与DataFrame 处理缺失值分组groupby() 函数apply()函数 透视表 使用场合
Pandas库是基于Numpy库建立的为数据添加标签、处理缺失值、分组和透视表方面Pandas更高效
对象创建
Series对象
Series 是…
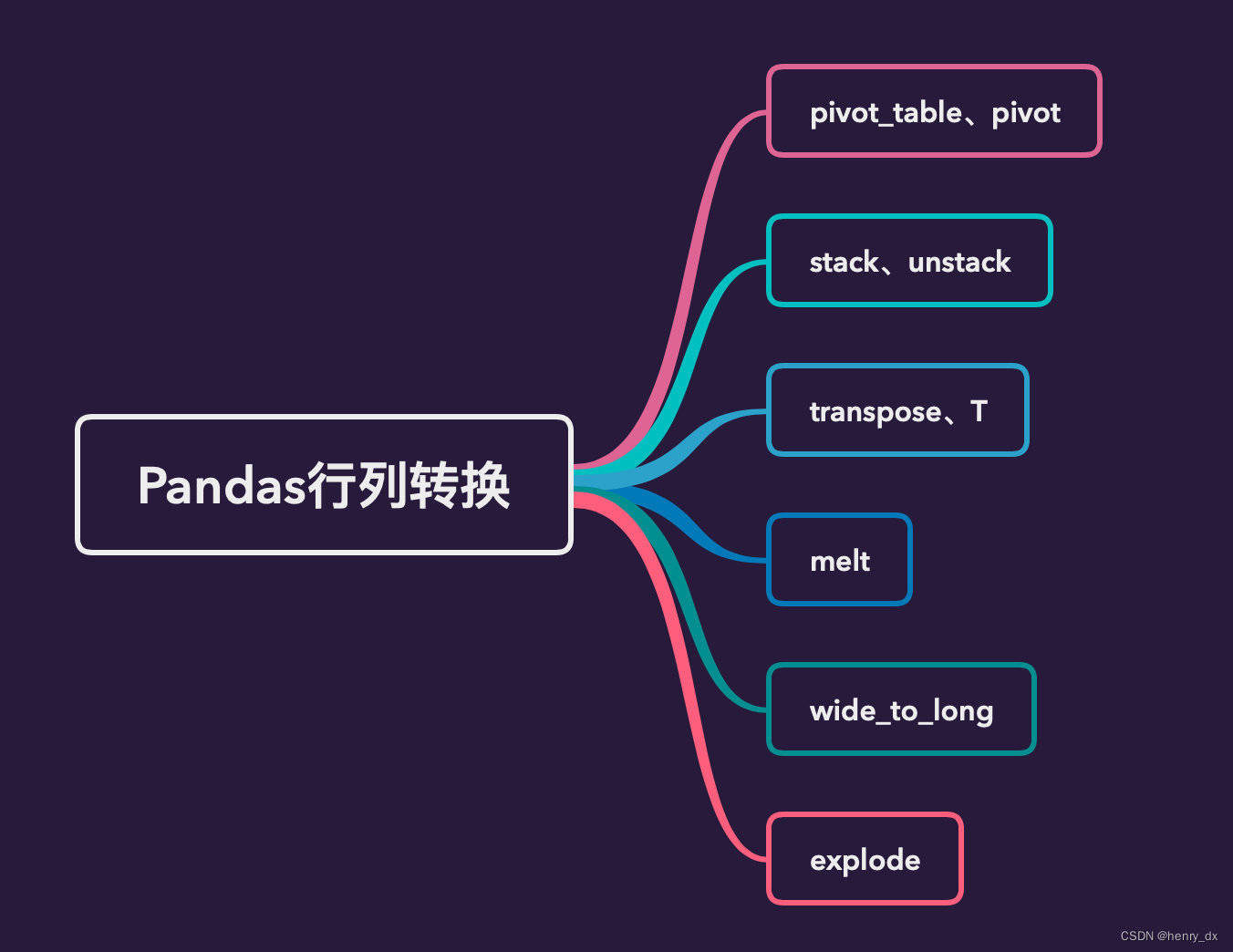
Pandas行列转换
一、问题描述
在实际的数据处理过程中,常常会遇到需要将DataFrame中的列转换为行或将行转换为列的情况。但是,如果使用传统的Python方法,这种操作会非常繁琐且容易出错。因此,我们可以使用pandas库提供的优雅方式来完成列转行或行…
设置小数点后2位,随机保存财富txt,生成随机富翁数
如果想要将生成的随机财富数据保留小数点后两位,可以在写入文件之前使用格式化字符串的方法来控制小数点的位数。以下是修改后的代码示例:
import random# 生成随机财富数据
total_people 100
average_wealth 200 * 10**8 # 平均财富 200亿# 5个人的…
【python数据建模】Pandas库
概述
Pandas库主要提供了三种数据结构: (1)Series:带标签的一维数据 (2)DataFrame:带标签且大小可变的二维表结构 (3)Panel:带标签且大小可变的三维数据 Pan…
vscode pandas无法使用
一、代码内容
import csv
csv_reader csv.reader(open("data.csv"))
for row in csv_reader:print(row)
print(row[2])
二、错误提示
ModuleNotFoundError: No module named pandas
三、安装pandas
然后我安装pandas,因为我的python的版本是python …

Python3,3行代码,把excel转换成任意格式的word文档,老板直接给我涨薪10K!!!
Excel转换任意格式Word1、引言2、excel转换成word2.1 手动转换2.2 自动转换2.2.1 docxtpl 介绍2.2.2 代码实战3、总结1、引言
小屌丝:鱼哥,有一事相求? 小鱼:何事,说来听听! 小屌丝:BOSS让我把…

Python教程:DataFrame数据中使用resample计算月线平均值
在pandas库中,DataFrame可以使用resample()方法来对时间序列数据进行重采样。重采样是将原始数据按照指定的频率进行重新组织,以便进行更细粒度的分析或转换。下面是一个示例,演示如何使用resample()方法:
# Author : 小红牛
# 微…
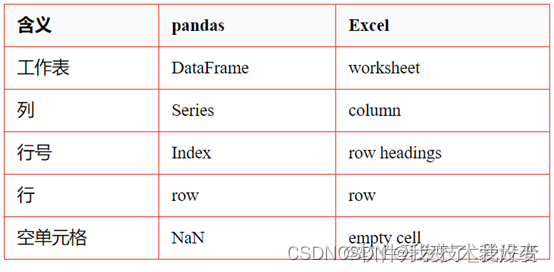
Zhong__Pandas操作Excel表数据
时间:2023.10.16
环境:Windows 10 python3.12
目的:Pandas简单使用
说明:
作者:Zhong QQ交流群:121160124 欢迎加入! 安装
pandas/openpyxl
pip3 install -i https://pypi.douban.com/sim…

Pandas数据处理分析系列5-数据如何提取
Pandas-数据提取
①通过索引提取数据 # 提取前10行数据 df.head(10) # 提取末尾10行数据 df.tail(10) # 通过列名提取数据 df[列名’] # 通过布尔条件提取数据 df[df[列名] > 10] # 多条件过滤 df[(df[列名1] > 10) & (df[列名2] < 20)]
df1=pd.read_excel(&quo…

使用Spyder进行动态网页爬取:实战指南
导语
知乎数据的攀爬价值在于获取用户观点、知识和需求,进行市场调查、用户画像分析,以及发现热门话题和可能的新兴领域。同时,知乎上的问题并回答也是宝贵的学习资源,用于知识图谱构建和自然语言处理研究。爬取知乎数据为决策和…
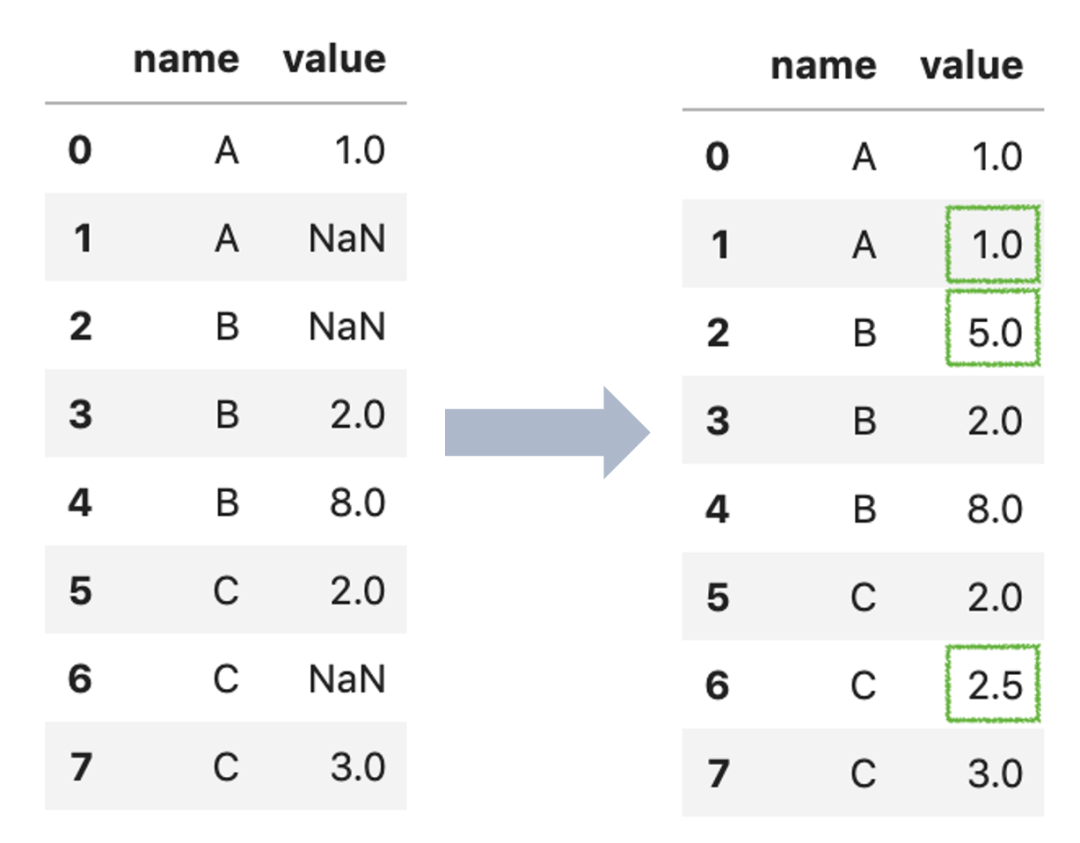
Pandas进阶:transform 数据转换的常用技巧
引言
本次给大家介绍一个功能超强的数据处理函数transform,相信很多朋友也用过,这里再次进行详细分享下。
transform有4个比较常用的功能,总结如下: 转换数值 合并分组结果 过滤数据 结合分组处理缺失值
一. 转换数值
pd.…
Pyrthon中pandas DataFrame对表格数据选取,修改,切片的实现
set_index()函数
在Python Pandas的数据处理中,set_index是一个非常常用的函数,它的作用就是将DataFrame中的一列或多列作为新的索引。使用set_index函数,可以快速地进行数据的筛选和重组。 如何在pandas中使用set_index( )与reset_index( )…
知识图谱05——gspan-mining库进行频繁子图挖掘出现‘DataFrame‘ object has no attribute ‘append‘
在使用gspan-mining库进行频繁子图挖掘时出现下面错误
发生异常: AttributeError
DataFrame object has no attribute append查阅网上资料发现,pandas 2.0以后的库不支持DataFrame的append操作 在终端输入
pip show gspan-mining找到包的位置,打开gspa…
使用pandas处理excel文件【Demo】
一、代码示例
import pandas as pd
from pandas import Series,DataFrame
from pandasql import sqldf
import matplotlib.pyplotidInfos DataFrame(pd.read_excel(home_data.xlsx))print(idInfos.head(2))print(idInfos.dtypes)# print(idInfos[:][姓名])
# 自定义一个函数s…
Pandas教程(非常详细)(第二部分)
接着Pandas教程(非常详细)(第一部分),继续讲述。
七、Pandas使用自定义函数
如果想要应用自定义的函数,或者把其他库中的函数应用到 Pandas 对象中,有以下三种方法:
1) 操作整个 …
[黑马程序员Pandas教程]——索引与列名的操作
目录:
学习目标数据准备获取索引及列名 index查看索引columns查看列名索引及列名的修改方法 指定某列为索引 使用set_index函数读取数据时指定索引列reset_index重置索引赋值修改索引及列名 赋值修改索引赋值修改列名rename函数修改索引和列名 rename函数修改索引r…
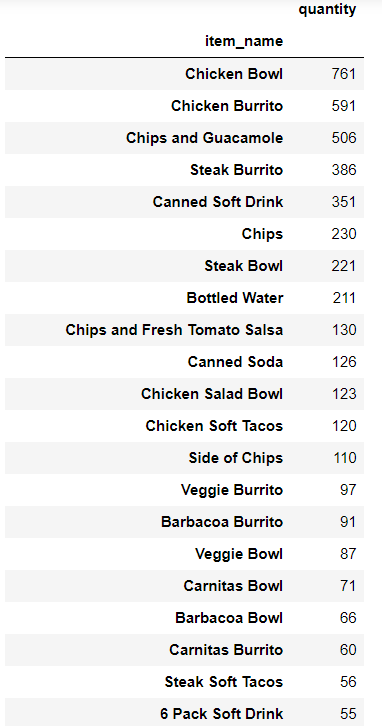
Pandas练手项目
一、chipotle tsv
数据集:chipotle.tsv-数据集
代码:https://download.csdn.net/download/Albert233333/88508819
1 导入数据
# order_id这一列相同的数字表示 一个消费者同一次进行的交易
# 表格中的每一行表示 用户一次购买的某一个品类 购买的数量…
[黑马程序员Pandas教程]——DataFrame数据的增删改操作
目录:
学习目标DataFrame添加列 直接赋值添加列数据删除与去重 删除 df.drop删除行数据df.drop删除列数据数据去重 Dataframe去重Seriers去重修改DataFrame中的数据 直接修改数据replace函数替换数据按条件使用布尔值修改数据执行自定义函数修改数据 Series.apply(…

Python教程:Pandas删除数据的4种情况
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码
开始之前,pandas中DataFrame删除对象可能存在几种情况
1、删除具体列
2、删除具体行
3、删除包含某些数值的行或者列
4、删除包含某些字符、文字的行或者列…
进行词频统计时的停止词和词组统计的用法
不同智库的不同主题进行词频统计并分开存储到不同的 Excel
import os
import string
import pandas as pd
from collections import Counter
import yake
import jieba
import textract# 读取 Excel 文件
df pd.read_excel(rC:\Users\win10\Desktop\2022.xlsx)stop_words[&qu…

pandas之DataFrame基础
pandas之DataFrame基础1. DataFrame定义2. DataFrame的创建形式3. DataFrame的属性4. DataFrame的运算5. pandas访问相关操作5.1 使用 loc[]显示访问5.2 iloc[] 隐式访问5.3 总结6. 单层索引和多层级索引6.1 索引种类与使用6.2 索引相关设置6.3 索引构造6.4 索引访问6.5 索引变…

数据分析-Pandas数据探查初步:离散点图
数据分析-Pandas数据探查初步:离散点图
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律ÿ…
比较系统的学习 pandas(4)
复杂查询
由于不好描述,就举几个栗子吧,不明白的可以私聊我
1、pnadas 支持逻辑计算与位运算
对DataFrame的一列进行逻辑计,会产生一个对应的由布尔值组成的Series,真假值由此位上的数据 是否满足逻辑表达式决定。
data["…
Pandas50个高级高频操作
01、复杂查询 实际业务需求往往需要按照一定的条件甚至复杂的组合条件来查询数据,接下来为大家介绍如何发挥Pandas数据筛选的无限可能,随心所欲地取用数据。 1、逻辑运算 # Q1成绩大于36df.Q1> 36# Q1成绩不小于60分,并且是C组成员~(df.Q1< 60) &a…
Pandas的应用-1
Pandas是一个开源的数据分析工具,它提供了高性能、易于使用的数据结构和数据分析工具。其中,Series是Pandas中最基本的数据结构之一,它是一种类似于一维数组的对象,可以储存任何数据类型。在本文中,我们将介绍Series的…
一文解读pandas_udf
1.函数定义
pyspark.sql.functions.pandas_udf(fNone, returnTypeNone, functionTypeNone) Pandas UDFs are user defined functions that are executed by Spark using Arrow to transfer data and Pandas to work with the data, which allows vectorized operations 使用sp…
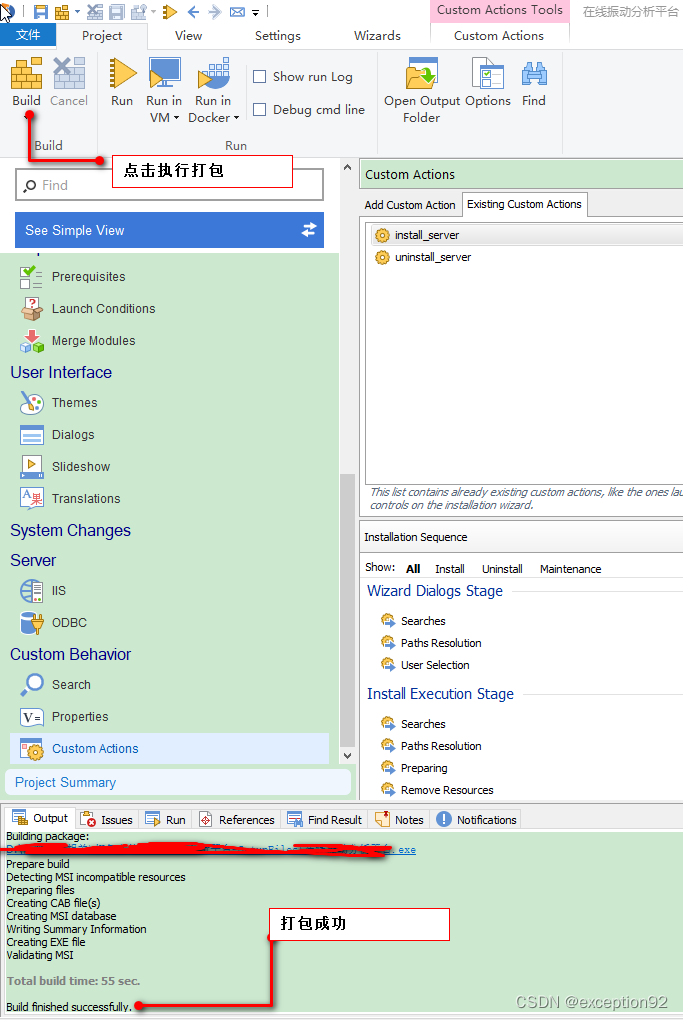
使用Advanced Installer打包程序及运行环境
Advanced Installer 工具版本:20.1.1
设置产品信息 选中右侧【Product Details】输入产品信息 设置文件和文件夹
添加使用VS发布之后的程序文件夹 设置文件夹刷新
选中文件夹,右键选择属性,选中Synchronize标签。启用“Synchronize conten…

2023年美国大学生数学建模A题:受干旱影响的植物群落建模详解+模型代码(二)
前言
资源放CSDN上面过不了审核,都快结束了都没过审真的麻了,订阅专栏的同学直接加我微信直接发你。我只打造优质专栏。专注建模四年,博主参与过大大小小数十来次数学建模,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。此专栏的目的就是为了让零基础快速使…
【Python】特征工程
特征工程1. 数据集质量探索1.1 数据集正确性校验1.2 缺失值检验2. 独热编码(离散变量编码)2.1 原理 & 过程2.2 封装函数3. 连续变量分箱(连续变量编码)3.1 原理3.2 等宽分箱3.3 等频分箱3.4 聚类分箱4. 分组统计特征衍生4.1 分组统计原理4.2 过程4.2.1 数据准备4.2.2 单统计…
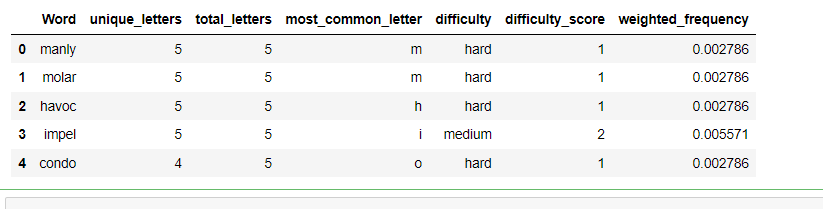
2023美赛C题【分析思路+代码】
以下内容为我个人的想法与实现,不代表任何其他人。 文章目录问题一数据预处理时间序列模型创建预测区间单词的任何属性是否影响报告的百分比?如果是,如何影响?如果不是,为什么不是?问题二问题三难度评估模型…
python删除csv文件中的某几列或行
1. 读取数据
用pandas中的read_csv()函数读取出csv文件中的数据:
import pandas as pddf pd.read_csv("comments.csv")
df.head(2)用drop函数进行文件中数据的删除行或者删除列操作。
2. 删除列操作
方法一:假设我们要删除的列的名称为 ‘观众ID’,‘…

数据分析05——往Pandas中导入数据
1、导入Excel:
注意这种方法可以导入xlsx和xls两种类型的数据读入的数据会以DataFrame的格式显示举例:df pd.read_excel(‘./data/demo_03.xlsx’)还可以导入excel文件中具体的某一个表格:pd.read_excel(‘./data/demo_03.xlsx’, sheet_na…
<2>【深度学习 × PyTorch】pandas | 数据预处理 | 处理缺失值:插值法 | networkx模块绘制知识图谱 | 线性代数初步
你永远不可能真正的去了解一个人,除非你穿过ta的鞋子,走过ta走过的路,站在ta的角度思考问题,可当你真正走过ta走过的路时,你连路过都会觉得难过。有时候你所看到的,并非事实真相,你了解的,不过是浮在水面上的冰山一角。—————《杀死一只知更鸟》 🎯作者主页: 追…
28. Pandas的Categorical数据类型可以降低数据存储提升计算速度
import pandas as pd
import timedf pd.read_csv(./users.dat,sep::,enginepython,headerNone,namesUserID::Gender::Age::Occupation::Zip-code.split(::))
print(df.head())
print(df.info())info() 方法中常用的一些参数包括:verbose(默认值:True)&a…
pandas使用dropna函数删除dataframe数据中多个数据列的内容至少包含一个缺失值的数据行(使用subset参数指定多个数据列)
pandas使用dropna函数删除dataframe数据中多个数据列的内容至少包含一个缺失值的数据行(使用subset参数指定多个数据列) 目录
Jupyter notebook 和 Jupyter lab 的区别
Jupyter Notebook和JupyterLab都是用于交互式计算和数据科学的开源工具
它们都是基于Jupyter项目构建的,提供了一种以笔记本形式创建、运行和共享代码、文本和可视化结果的方式。然而,Jupyter Notebook和JupyterLab在用户界面、功能和扩展性方面存在一些…
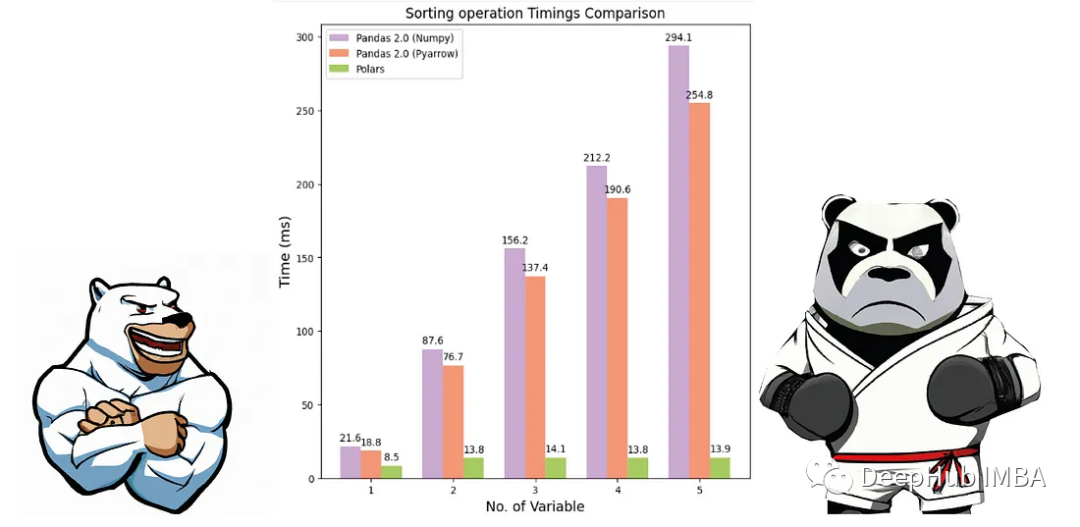
Pandas 2.0 vs Polars:速度的全面对比
前几天的文章,我们已经简单的介绍过Pandas 和Polars的速度对比。刚刚发布的Pandas 2.0速度得到了显著的提升。但是本次测试发现NumPy数组上的一些基本操作仍然更快。并且Polars 0.17.0,也在上周发布,并且也提到了性能的改善,所以我…
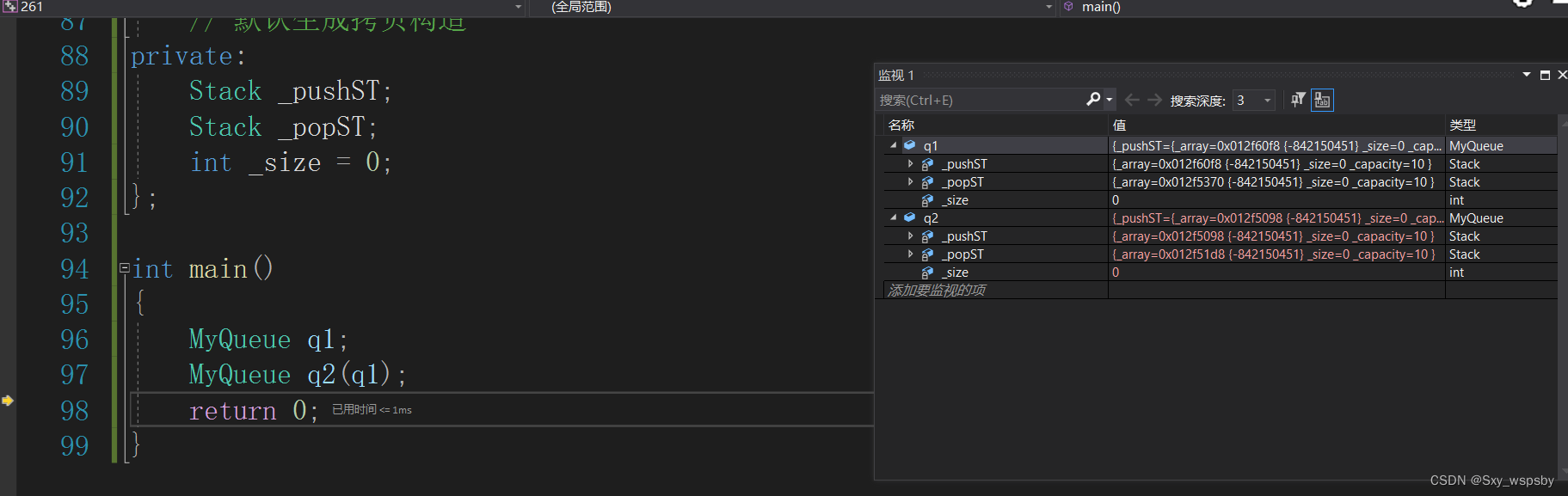
【c++】类和对象:让你明白“面向一个对象有多重要”:构造函数,析构函数,拷贝构造函数的深入学习
文章目录 什么是面向对象?一:类是什么? 1.类的访问限定符 2.封装 3.类的实例化 4.this指针二:类的6个默认成员函数 1.构造函数 2.析构函数 3.拷贝构造函数什么是面向对象?
c语言是面向…

【数学建模相关】matplotlib画多个子图(散点图为例 左右对照画图)
文章目录例题例图代码展示例题
乙醇偶合制备 C4 烯烃
C4 烯烃广泛应用于化工产品及医药的生产,乙醇是生产制备 C4 烯烃的原料。
在制备过程中,催化剂组合(即:Co 负载量、Co/SiO2 和 HAP 装料比、乙醇浓度 的组合)与…
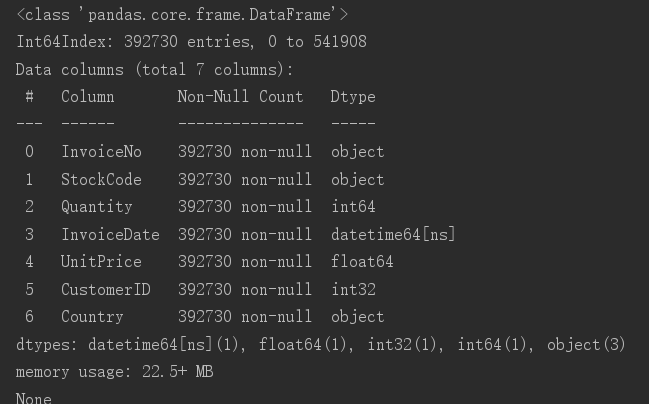
python数据清洗
数据清洗包括:空值,异常值,重复值,类型转换和数据整合这里数据清洗需要用到的库是pandas库,下载方式还是在终端运行 : pip install pandas.首先我们需要对数据进行读取import pandas as pddata pd.read_cs…
Python学习笔记(2)
写在前面
这节内容是python基础知识中的数据类型和运算符,可以回顾一下前两篇文章来复习一下:
利用Excel学习Python:变量
利用Excel学习Python:准备篇
本来想分开写的,但发现好像分不开,所幸内容也不多…
Pandas 学习笔记(一)
1. 创建 DataFrame
可以通过 list、csv、Series、empty DataFrame 等创建
DataFrame 语法结构
pandas.DataFrame(dataNone, indexNone, columnsNone, dtypeNone, copyNone)1.1 通过 list 创建
import pandas as pd
technologies [ ["Spark",20000, "30days…
TOOLS_Pandas groupby 分组聚合常用方法使用示例
TOOLS_Pandas groupby 分组聚合常用方法使用示例
根据给定列中的不同值对数据点(行)进行分组;分组后的数据可以计算生成组的聚合值; 注意:下文仅是常用的一些示例,实际操作时可组合使用的方式要多得多&…
使用Python Pandas库操作Excel表格的技巧
在数据分析和处理中,我们经常需要对Excel表格进行操作。Python Pandas库提供了丰富的API来读取、写入、修改Excel表格。本文将介绍如何使用Python Pandas库操作Excel表格,包括向Excel表格添加新行、创建Excel表格等。
1.向Excel表格添加新行
下面是一个…
pandas空值检测
NaN(Not-A-Number)在pandas里用作空值(NA),并且有函数 isna 和 notna 可以跨 dtypes 使用来检测 NA 值。
# 不要用是否等于None来判断pandas里值是否为空。
pd.NANone
False
pd.isna(pd.NA)
True
pd.isna(None)
True
…
pandas空值类型提升 NaN类型提升
什么是空值提升
当列中有空值时,列的原有类型会被忽略,同时会被提升到一个更『宽』或更『高』的类型来存储空值。 原始类型 提升到的类型用于存储空值(Promotion dtype for storing NAs) floating no change object no chan…
pandas处理大文件
目录
思路一:分而治之
思路二:精简数据
demo 思路一:分而治之
分而治之,分批次加载大文件,每次读取一定行数的数据,读一批处理一批。
此方法简单有效,易实现,但可能适用性不高&…
笔记本 - 数据分析百宝箱
Numpy
一、基本操作:
属性:
improt numpy as np
生成数组:
arraynp.array([[1,2,3],[2,3,4]],dtypenp.int/float)
array.npim: 几维的数组
array.shape: 几行几列;
array.size : 数组内几个元素
anp.zeros/ones( (3,4) )…
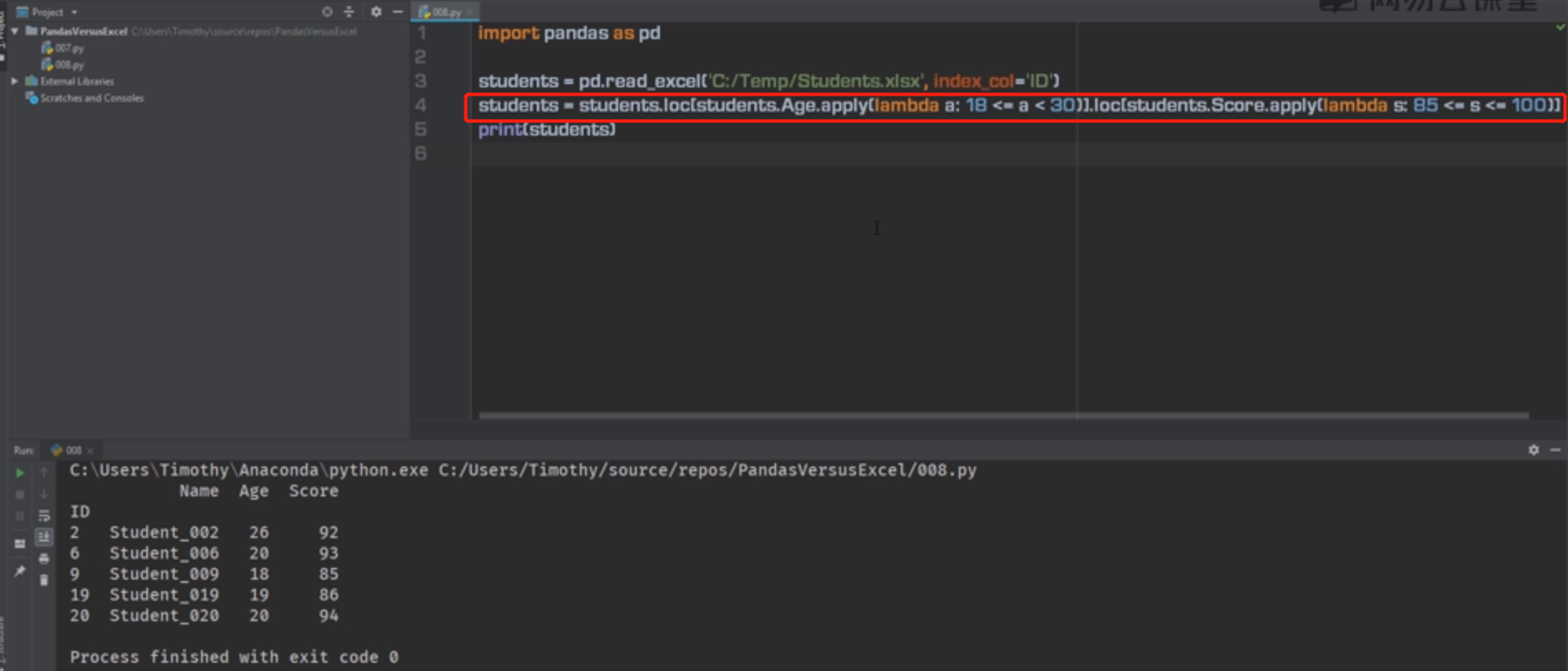
章节2 行走数据江湖,只需一行代码
目录8. 数据筛选、过滤,[绘图前的必备功课]8.1 excel操作8.2 Python操作http://sa.mentorx.net 蔓藤教育8. 数据筛选、过滤,[绘图前的必备功课]
8.1 excel操作
筛选,18<年龄<30的学生的分数状况,且分数>80的学生 全部…
pandas5 数据分组与聚合
文章目录5.数据分组与聚合数据分组数据聚合:对分组后的数据进行计算,产生标量值的数据转换过程。分组运算:包含聚合运算,聚合运算是数据转换的特例。重要技巧:5.数据分组与聚合
数据分组
1.groupby方法:D…
pandas的groupby函数使用lambda作为参数进行分组
使用以下数据集
close_px pd.read_csv(uhttps://gitee.com/pan19/data-source/raw/master/stock_px_2.csv, parse_datesTrue,index_col0)
close_px.info()
close_px.head(10)如果lambda什么也不做,只是打印,可以看到groupby默认使用索引进行分组
show…

爬虫实战进阶版【1】——某眼专业版实时票房接口破解
某眼专业版-实时票房接口破解
某眼票房接口:https://piaofang.maoyan.com/dashboard-ajax
前言
当我们想根据某眼的接口获取票房信息的时候,发现它的接口处的参数是加密的,如下图: 红色框框的参数都是动态变化的,且signKey明显是加密的一个参数。对于这种加密的参数,我们需要…
pandas练习(二)
pandas练习(二)
透视表的创建
df pd.DataFrame({A: [one, one, two, three] * 3,B: [A, B, C] * 4,C: [foo, foo, foo, bar, bar, bar] * 2,D: np.random.randn(12),E: np.random.randn(12)})print(df)pd.pivot_table(df, index[A, B])透视表按指定行…
使用join快速组合字符串,以及使用splite快速分解字符串
如果一个字符串由相同连接符组合而成,例如’2017-02-28‘
date [2017,02,28]
-.join(date)逆操作
val 2017-02-28‘
date [x.strip() for x in val.split(,)]
date
pandas中apply()+value_counts()使用方法
df pd.DataFrame(np.arange(12).reshape((4,3)),\columnslist(abe),\index [wo,shi,shui,ha])formatr lambda x:%.1f %x
df.apply(formatr)pandas 的 apply() 函数可以作用于 Series 或者整个 DataFrame,功能也是自动遍历整个 Series 或者 DataFrame, 对每一个元…

Databend 开源周报第 93 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend
探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。
改进 Databend …


pandas使用重采样函数resample改变时间周期进行聚合
Pandas中的resample,重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。
降采样:高频数据到低频数据
升采样:低频数据到高频数据 data数据集
weekly data.resampl…
pd.DataFrame.melt()函数
对这个函数的理解就是二维变一维,就是逆序数列melt(self, id_varsNone, value_varsNone, var_nameNone, value_namevalue, col_levelNone)Parameters----------id_vars : tuple, list, or ndarray, optionalColumn(s) to use as identifier variables.value_vars : …
pandas之reset_index
适用于拼接数据后重新制作索引 以下数据由三个100行的数据集上下拼接而成,注意索引的从上到下为0-99,0-99,0-99共300个元素 0
0 4
1 4
2 2
3 2
4 3
... ...
95 27321
96 13255
97 12741
98 20067
99 21760300 rows 1 columnsbigm…

pandas中groupby的返回值
假设存在如下数据集drinks: 以continent列进行分组:
drinks.groupby(bycontinent)返回值是个重构格式的DataFrameGroupBy object,没法直接输出
(AF, country beer_servings spirit_servings wine_servings \
2 …
21.Pandas怎样快捷方便的处理日期数据
21.Pandas怎样快捷方便的处理日期数据
Pandas日期处理的作用:将2018-01-01、1/1/2018等多种日期格式映射成统一的格式对象,在该对象上提供强大的功能支持
几个概念:
pd.to_datetime:pandas的一个函数,能将字符串、列…
20.Pandas的stack和pivot实现数据透视
20.Pandas的stack和pivot实现数据透视
经过统计得到多维度指标数据 使用unstack实现数据二维透视 使用pivot简化透视 stack、unstack、pivot的语法
经过统计得到多维度指标数据 非常常见的统计场景,指定多个维度,计算聚合后的指标
实例:统…
Pandas实践经验汇总
目录 DataFrame去重drop_duplicates 加载parquet文件加载XLSX文件报错 DataFrame
去重drop_duplicates
参考:官方文档-pandas.DataFrame.drop_duplicates 参数: subset:按照subset指定的列进行去重,默认为所有列; ke…
chatgpt赋能Python-pycharm中怎么粘贴代码
PyCharm是Python编程领域中最受欢迎的集成开发环境之一。它是由JetBrains开发的一款跨平台IDE软件,旨在优化Python项目的开发过程。PyCharm拥有强大的代码编辑器、调试器、代码跟踪器和内置的版本控制工具,可以帮助开发人员编写高效、优质的Python代码。…

接口自动化【五】(HandleRequests类的封装,及postman上下接口依赖的初步认识)
文章目录 前言一、封装发送请求的操作二、迷惑的知识点三、postman的全局变量机制总结 前言
所有的封装就是一种思想,这种思想能不能想到,其实跟写代码建立思维有很大的关系。
下面也是我学到的一种思想,其中对每个函数有解读。以及易错点的…

数据分析11——Pandas中数据偏移/数据切分/数据结构转换
数据偏移:
1、shift函数:
在 Pandas 中,shift 函数用于将数组的数据向前或向后平移指定的步数。它可以应用于 Series 或 DataFrame 类型的数据中,并返回一个平移后的新数据结构,其中每个元素都被取代为原始序列中对应…
pandas drop 方法
pandas.Series.drop
Series.drop 方法可以返回一个新对象,移除指定的 index labels.
import pandas as pd
import numpy as nps pd.Series(np.arange(5.), index[a, b, c, d, e])
s
"""
a 0.0
b 1.0
c 2.0
d 3.0
e 4.0
dtype: flo…
pandas reindex 方法
pandas.Series.reindex
reindex 方法会创建一个新对象,并根据给定的新 index 对原来 Series 的数据重新组织。如果新 index 中有原来 index 不存在的 label,那么这些 label 对应位置会被填充 NaN:
import pandas as pd
import numpy as nps…
chatgpt赋能python:Python散点图的颜色设置
Python散点图的颜色设置
什么是散点图?
散点图是一种数据可视化的图表类型。它用于观察两个变量之间的关系。通常,x轴表示一个变量,y轴表示另一个变量。每个点表示一个数据点,它在x和y轴上分别具有对应的值。我们可以通过比较散…
chatgpt赋能python:**Python中的SEO:正确与错误**
Python中的SEO:正确与错误
对于任何一个网站,无论其大小和规模,搜索引擎优化(SEO)都是必不可少的。作为一种流行的编程语言,Python也可以用来优化和改进SEO操作。在本文中,我们将探讨Python中对于SEO的正确和错误使用…
chatgpt赋能python:Python实现CSV文件只取某两列的方法详解
Python实现CSV文件只取某两列的方法详解 介绍 CSV是一种常见的数据格式,通常使用逗号或分号分隔不同的字段。在处理CSV文件时,我们经常需要只提取其中的某些列,以便进行进一步的分析或处理。使用Python语言,可以很方便地实现…
Pandas进阶修炼120题
文章目录 Pandas进阶修炼120题第一期 Pandas基础1.将下面的字典创建为DataFrame2.提取含有字符串"Python"的行3.输出df的所有列名4.修改第二列列名为popularity5.统计grammer列中每种编程语言出现的次数6.将空值用上下值的平均值填充通常方法(直接写逻辑&…

pandas---文件读取与存储(csv、hdf、json、excel、sql)
数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的API支持众多的文件格
式,如CSV、SQL、EXCEL、JSON、 HDF5。
1. csv文件
pandas.read_csv(filepath_or_buffer, sep ,, usecols )
filepath_or_buffer:文件路径 sep :…
python学习——pandas数据处理 时间序列案例 matplotlib绘图案例
目录 pandas数据处理1.合并数据1) 堆叠合并2) 主键合并3) 重叠合并 2.分组和聚合3.索引和符合索引4.去除重复值5.处理缺失值6.处理离群值7.标准化数据1) 离差标准化函数2) 标准差标准化函数3) 小数定标差标准化函数 8.转换数据--离散处理9.时间序列【案例】时间序列案例案例1&a…
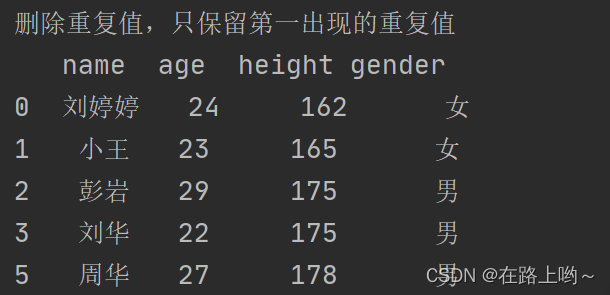
人工智能数据集处理——数据清理1
目录 一、概述
二、缺失值
1、检测缺失值
使用isna() 方法检测na_df中是否存在缺失值
使用natna() 方法
2、缺失值的处理
(1) 删除缺失值
使用删除dropna() 方法删除na_df 对象中缺失值所在的一行数据
删除全为缺失值的行
删除有缺失值的行
(2) 填充缺失值
使用fill…

python绘制热力图,数据来源pandas.dataframe
通过pandas.dataframe绘制热力图,并标出颜色最深即z轴数据最大的点。
import matplotlib.pyplot as plt
import pandas as pd
import numpy as npclass Heatmap:def __init__(self, data, marker*, marker_colorwhite, marker_size10):self.data dataself.size l…

Python:Pandas学习笔记(二)通过DataFrame读写各种类型数据
目录
CSV
文本文件
html
XML
EXCEL
JSON
HDF5
pickle对象序列化
数据库 SQLite MySQL read_X()通常是pandas模块下的,to_X()是dataframe的方法 CSV
读取
使用pandas.read_csv()方法,返回的是一个dataframe
csv默认是以",&qu…
Pandas入门必知!如何轻松设置DataFrame索引?
Pandas是Python最流行的数据分析库,其中的DataFrame是表格型数据的主要数据结构。 Pandas DataFrame默认的索引是整数索引,但是在很多场景下,我们需要设置一个更有意义的索引。 庆幸的是,Pandas提供了非常简便的方法来设置DataFra…
数据分析08——Pandas中对数据进行数据清洗
0、前言:
使用pandas修改数据是否会改变源数据? Pandas 对 DataFrame 的操作通常是针对原始数据本身而不是其副本的。例如,当我们使用 .loc 或 .iloc 方法选择 DataFrame 中的某行或某列并进行修改时,实际上是直接更改了原始数据…
pandas教程:Binary Data Formats 二进制数据格式
文章目录 6.2 Binary Data Formats (二进制数据格式)1 Using HDF5 Format2 Reading Microsoft Excel Files(读取微软的excel文件) 6.2 Binary Data Formats (二进制数据格式)
最简单的以二进制的格式来存储数据的方法(也被叫做serialization…
numpy教程:Universal Functions 通用函数 伪随机数
文章目录 4.2 Universal Functions: Fast Element-Wise Array Functions(通用函数:快速点对点数组函数)4.4 File Input and Output with Arrays(通过数组来进行文件的输入和输出)4.5 Linear Algebra (线性代数)4.6 Pse…
Pandas - 数据合并
DataFrame数据合并主要使用merge()方法和concat()方法。
1.数据合并(merge()方法) Pandas模块的merge()进行数据合并时,两个DataFrame对象必须有相同的列。 1.常规合并
import pandas as pddf1 pd.DataFrame({编号:[mr001,mr002,mr003],语…

Python进阶教程:pandas数据分析实践示例总结
文章目录 前言一、分析数据文件二、数据预处理关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Python学习书籍四、Python工具包项目源码合集①Python工具包②Python实战案例③Python小游戏源码五、面试资料六、Python兼职渠道 前言
在近日的py…

使用Pandas进行数据读写的简易教程
Pandas是一个功能强大且广泛使用的Python库。它提供了一种简单而灵活的方式来读取和写入各种数据格式,包括CSV、Excel、SQL数据库等。本文将介绍如何使用Pandas进行数据的读取和写入操作,帮助你快速上手并高效地处理数据。
一、安装和导入pandas
首先&…
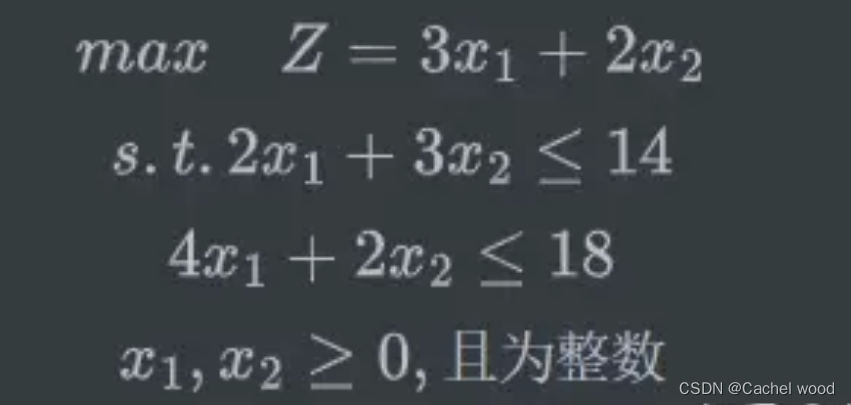
python+gurobi求解线性规划、整数规划、0-1规划
文章目录 简单回顾线性规划LP整数规划IP0-1规划 简单回顾
线性规划是数学规划中的一类最简单规划问题,常见的线性规划是一个有约束的,变量范围为有理数的线性规划。如: 使用matlab的linprog函数即可求解简单的线性规划问题,可以参…
sklearn教程:iris鸢尾花数据集数据分析
文章目录 数据集介绍导入数据集查看数据标签、属性和介绍查看数据整理为dataframe数据indo()查看数据类型和是否缺失describe() 提供数值型变量的描述性统计变量赋值标签编码分割训练集测试集查看X y 维度可视化分析箱线图查看数据分布和异常值直方图查看数值型数据分布密度图查…
dataframe.values.tolist() 举例说明
dataframe.values.tolist() 是将 Pandas DataFrame 中的数据转换为嵌套的 Python 列表(list of lists)。这将返回一个包含 DataFrame 所有行和列的嵌套列表。以下是一个简单的例子:
假设有如下的 DataFrame:
import pandas as p…
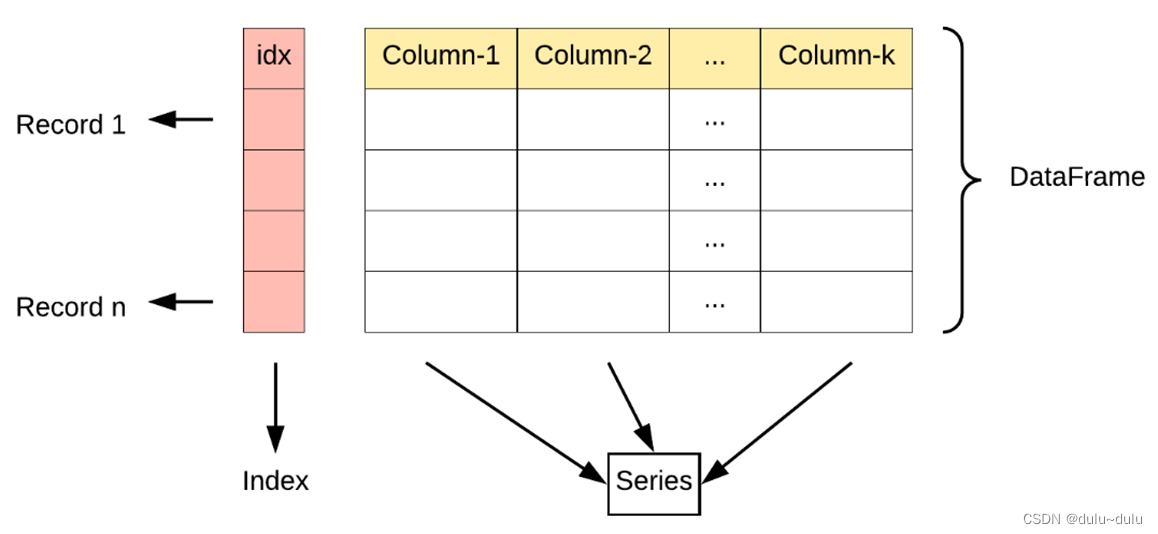
Python----Pandas
目录
Series属性
DataFrame的属性
Pandas的CSV文件
Pandas数据处理 Pandas的主要数据结构是Series(一维数据)与DataFrame(二维数据)
Series属性
Series的属性如下:
属性描述pandas.Series(data,index,dtype,nam…
sklearn教程:titanic泰坦尼克号数据集
文章目录 数据集介绍导入数据集info()显示数据类型和是否缺失describe()数据描述性统计数据可视化-探索性分析EDA填充缺失值之后的可视化类别变量的相关关系数据集介绍
这个数据集是基于泰坦尼克号中乘客逃生的,泰坦尼克号出事故,船上的乘客的一些信息被记录在这张表中。现在…
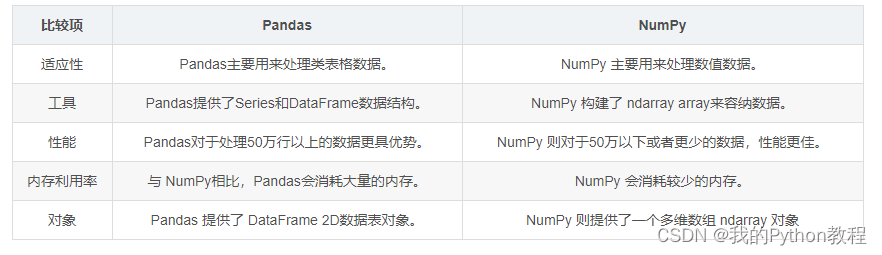
pandas数据转换成ndarray数组
Pandas 和 NumPy 被认为是科学计算与机器学习中必不可少的库,因为它们具有直观的语法和高性能的矩阵计算能力。下面对 Pandas 与 NumPy 进行简单的总结,如下表所示:
要将Pandas DataFrame转换为ndarray数组,您可以使用.values属…
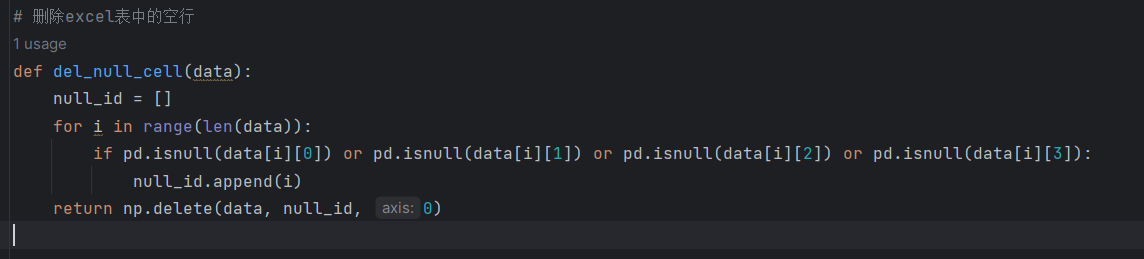
pandas 使用方法(1)
目录
1. excel 表格处理
(1) 读取excel 表格
(2) 抽取excel表部分列数据
(3) 保存数据到excel表格
(4) 保存到 excel 表中的不同sheet
2. 判断二维数组中的某个数值是否为空
3. 删除二维数组中的空行
4. 在列表中添加某列属性 本文是将使用pandas过程中遇到的问题进行了…

pandas查看数据常用方法(以excel为例)
目录 1.查看指定行数的数据head()
2. 查看数据表头columns
3.查看索引index
4.指定索引列index_col
5.按照索引排序
6.按照数据列排序sort_values() 7.查看每列数据类型dtypes
8.查看指定行列数据loc
9.查看数据是否为空isnull() 1.查看指定行数的数据head()
ÿ…

优化pandas运行速度
参考 还在抱怨pandas运行速度慢?这几个方法会颠覆你的看法
1. 将datetime数据与时间序列一起使用的优点
数据样本 date_time energy_kwh
0 1/1/13 0:00 0.586
1 1/1/13 1:00 0.580
2 1/1/13 2:00 0.572
3 1/1/13 3:00 0.596
4 1/1/13 4:00 …

pandas多进程 pandarallel
pandarallel和pandas无缝衔接,是实现多线程的一个非常友好的工具。 安装:pip3 install pandarallel
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from pandarallel import pandarallel
# shm_size_mb 分配…
chatgpt赋能python:Python中取某一列的方法
Python中取某一列的方法
Python是一种易于学习但功能强大的编程语言。它在数据分析、机器学习和Web开发中广泛应用。在这个代码示例中,我们将介绍如何使用Python从数据集中选择某一列。
获取数据集
为了演示如何从数据集中选择某一列,我们将首先使用p…

pandas 匿名函数与聚合函数的使用
1. apply() 匿名函数的使用
1.1 针对“注册日期”列计算已注册天数
备注:这种速度很慢!
# 使用apply()对某一列进行匿名函数映射
try:today datetime.datetime.today()data[reg_days] data[reg_dt].apply(lambda x: (today - datetime.datetime.str…
chatgpt赋能python:用Python创建股票池
用Python创建股票池
介绍
如果你是一位投资者,你一定知道股票池是什么。它是一个包含一组股票的集合,使投资者能够跟踪和管理他们的投资组合。这些股票可以根据各种因素分类,例如行业,市值,收入增长等。
Python是一…
Python学习笔记(5):字典
写在前面 本系列适合0基础的人食用,这是利用Excel学习Python系列的第5篇文章,系列文章可移步:Python数据分析(点击标题可查看) 之前的列表都复习好了吗:python数据结构:列表
are u ready?另一种…
pandas 按行聚合 按列聚合 分组添加汇总行
1.dataframe按行列聚合
对于某个数据,我们经常需要各种聚合操作,比如针对行/列求和,求均值等。下面通过一个例子看在pandas中如何实现。
import pandas as pddef t1():data {name: [a, a, a, b, b, c, c, c],s1: [1, 5, 4, 2, 4, 3, 6, 7]…

Pandas数据分析—对字符串的处理
8.Pandas对字符串的处理 文章目录8.Pandas对字符串的处理前言一、程序演示1.获取Series的str属性,然后使用各种字符串处理函数2.使用str的startwith,contains等bool类Series可以做条件查询3.需要多次str处理的链式操作4.使用正则表达式的处理总结前言
笔者最近正在…
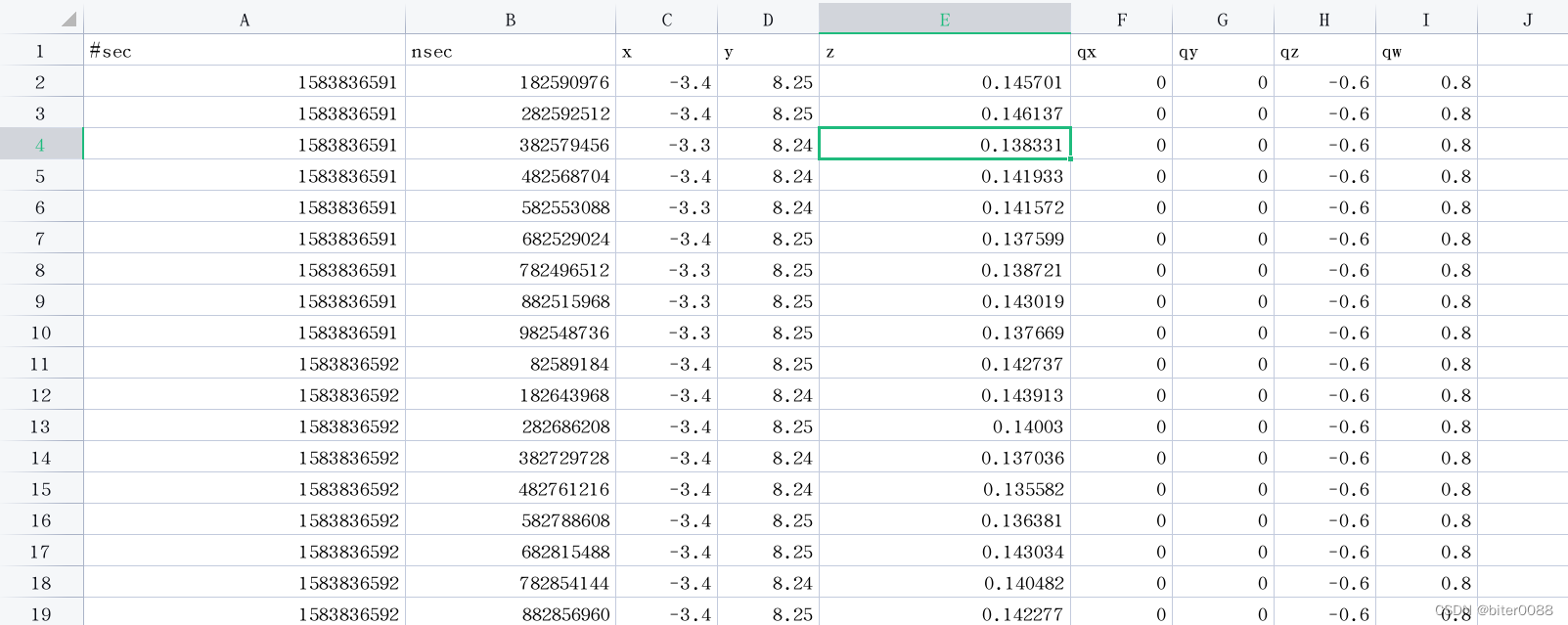
python(11):python读取excel、csv文件
1.python读取excel文件
要读取Excel表格的指定行和列范围,可以使用Python中的第三方库pandas。pandas库提供了强大的数据分析和处理工具,包括读取和处理Excel文件的功能。以下是一个示例代码,演示了如何使用pandas库读取Excel表格中的指定行…
Python Pandas的操作
import pandas as pd1.DataFrame
#取值
##pandas取一列得到Series结构,取两列得到DataFrame结构,此时将列标签看成key,dataframe是字典结构
#dataframe作为字典时,只能用key获得对应的列,不能用类似numpy的切片索引形式(a:b:c 从…
Python的pandas模块的运用之数据处理
pandas之数据处理一、数据导入与导出(一)、csv文件的数据导入与导出(二)、txt和excel文件的数据导入与导出二、数据清洗(一)、数据排序(二)、去除重复数据(三)…
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa3 in position 4: invalid start byte
pandas读取csv文件出现错误: UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xa3 in position 4: invalid start byte 原因是csv文件不是utf-8格式,在读取代码后面加上encoding"ISO-8859-1"即可,或者修改文件的编码格式…
【零基础入门学习Python---Python中数据分析与可视化之快速入门实践】
🚀 零基础入门学习Python🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜…
pandas【groupby函数】用法总结
groupby函数用法 函数定义axis参数的作用level参数的作用as_index参数的作用sort参数的作用group_keys参数的作用squeeze参数的作用observed参数的作用dropna参数的作用 函数定义
pandas中的groupby函数用于根据一个或者多个字段划分分组。 首先了解一下groupby函数的定义&…
pandas的reset_index()和rename()函数分不清?
reset_index()主要用于重置索引 假设如下数据集的索引为date、item
date item
1959-03-31 23:59:59.999999999 realgdp 2710.349infl 0.000unemp 5.800
1959-06-30 23:59:59.999999999 realgdp 2778.801infl …
pandas的stack和unstack详解
frame pd.DataFrame(np.arange(12).reshape((4, 3)),index[[a, a, b, b], [1, 2, 1, 2]])
frame形成一个二维数组 0 1 2
a 1 0 1 22 3 4 5
b 1 6 7 82 9 10 11unstack
unstack先把内层索引逆时针旋转到列索引,内层索引对应几列,就形成…
google colab 下载数据集、挂载自己的google drive
下载数据集:
from google.colab import files
files.download(a.csv)挂载google drive
from google.colab import drive
drive.mount(/content/gdrive)更改运行目录
import os
os.chdir("/content/gdrive/My Drive/Colab Notebooks")或者
import path…

DataFrame.plot函数详解(一)
DataFrame.plot函数详解(一)
1.函数定义
使用pandas.DataFrame的plot方法绘制图像会按照数据的每一列绘制一条曲线,默认按照列columns的名称在适当的位置展示图例 。
DataFrame.plot(xNone, yNone, kindline, axNone, subplotsFalse, shar…
python的dataframe常用处理方法
import pandas as pdclass DataFrameProcessor:staticmethoddef sort_by_column(df, by_column, ascendingTrue):"""根据指定列对DataFrame进行排序。Parameters:df (pd.DataFrame): 要排序的DataFrame。by_column (str): 要排序的列名。ascending (bool): True…

pandas利用日期作为索引再使用groupby聚合
假设存在数据集data: 我们想按年份进行聚合: 首先把索引变成以年份为单位:
data.index.to_period(A)再用年份进行分组
data.groupby(data.index.to_period(A))假设使用均值对每个列进行聚合
data.groupby(data.index.to_period(A)).mean()按月份进行聚…

利用Python进行数据分析 阅读笔记 之 第一章:准备工作
《利用Python进行数据分析》
这是一本非常好的使用python语言进行数据分析的入门书,既有基本理论讲解,也有实战代码示例。
我将认真阅读此书,并为每一章内容做一个知识笔记。
我会摘录一些原书中的关键语句和代码,若有错误请为我指…
os.listdir()读取文件夹下特定命名的文件并合并保存
import pandas as pd
from tqdm import tqdm
import os
# 合并振动信号的所有数据
path D:/code/data/Learning_set/Bearing1_1
acc_csv_files os.listdir(path)acc_data pd.DataFrame()
temp_data pd.DataFrame()
# 逐个读取并合并CSV文件
# tqdm的作用是显示进度条&#…
Pandas数据过滤的多种方式
DataFrame方式
import pandas as pddf pd.read_csv("data.csv", header1, names["index", "id", "url"])
df.dropna(how"any", inplaceTrue)# DataFrame方式
newdf1 df[(df.id 4099963) | (df.id 5181745)]
print(&quo…
Pandas loc和iloc 以及 pivot和melt详解
pandas的iloc和loc是分别使用位置和标签(列名或者行名)进行筛选数据。其中iloc是位置索引,loc是根据标签筛选。pivot和melt是pandas对整个数据表进行更改,其中pivot是将长格式数据列变成宽格式数据列(把某列的数据变成…
【Python】10个你需要知道的Python库
本文类似一个备忘清单,通过这份备忘清单深入了解 Python,其中包含任何 Python用户都需要了解的工具库。 从数据操作到机器学习和创建 Web 应用程序,这些库在日常Python开发中至关重要。
1、Streamlit
Streamlit用于快速构建web应用…
Pandas 中级教程——数据清理与处理
Python Pandas 中级教程:数据清理与处理
Pandas 是一个强大的数据分析库,它提供了广泛的功能来处理、清理和分析数据。在实际数据分析项目中,数据清理是至关重要的一步。在这篇博客中,我们将深入介绍 Pandas 中的一些中级数据清理…
pandas读取Excel表 提取手机号码
需求:在Excel表中,某一个单元格内有姓名、身份证号码、住址等信息,要将手机号码单独提取出来。
问题:有的单元格内没有手机号码,需要打印空行。而且还要考虑手机号码现在有13、14、15、16、17、18、19开头的。
模拟数…
解决pandas写入excel时的ValueError: All strings must be XML compatible报错
报错内容: ValueError: All strings must be XML compatible: Unicode or ASCII, no NULL bytes or control characters 报错背景
用pands批量写入excel文件,发生编码报错。检索了很多方案,都不能解决。
导致报错的原因是存在违法字符&…
Pandas 高级教程——数据可视化
Python Pandas 高级教程:数据可视化
Pandas 提供了强大的数据可视化工具,可以帮助你更好地理解数据、发现模式和进行探索性数据分析。本篇博客将深入介绍 Pandas 中的数据可视化功能,并通过实例演示如何创建各种图表和图形。
1. 安装 Panda…
72_Pandas.DataFrame保存并读取带pickle的系列(to_pickle、read_pickle)
72_Pandas.DataFrame保存并读取带pickle的系列(to_pickle、read_pickle)
要将 pandas.DataFrame、pandas.Series 对象保存为 pickle 文件,请使用 to_pickle() 方法,并使用 pd.read_pickle() 函数读取保存的 pickle 文件。
在此对…
pandas读写json的知识点
pandas对象可以直接转换为json,使用to_json即可。里面的orient参数很重要,可选值为columns,index,records,values,split,table A B C x 1 4 7 y 2 5 8 z 3 6 9 In [236]: dfjo.to_json(orient"columns")
Out[236]: {"A":{"x&qu…
Python从入门到熟练
文章目录 Python 环境Python 语法与使用基础语法数据类型注释数据类型介绍字符串列表元组集合字典 类型转换标识符运算符算数运算符赋值运算符复合运算符 字符串字符串拼接字符串格式化 判断语句bool 类型语法if 语句if else 语句if elif else 语句 循环语句while循环for 循环r…
头歌:Pandas分组聚合与透视表的创建
第1关 Pandas分组聚合
import pandas as pd
import numpy as np# 返回最大值与最小值的和
def sub(df):########## Begin #########resultdf.max()-df.mean()########## End #########
def jicha(arr):resultarr.max()-arr.min()return result
# 得到目标DataFrame
def main()…

100天精通Python(实用脚本篇)——第111天:批量将PDF转Word文档(附上脚本代码)
文章目录 专栏导读1. 将PDF转Word文档需求2. 模块安装3. 模块介绍4. 注意事项5. 完整代码实现6. 运行结果书籍推荐 专栏导读
🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教…
Seaborn 可视化
Seaborn简介
Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seabor…

流量预测中文文献阅读(郭郭专用)
目录 基于流量预测的超密集网络资源分配策略研究_2023_高雪亮_内蒙古大学(1)内容总结(2)流量预测部分1、数据集2、结果对其中的一个网格的CDR进行预测RMSE和R2近邻数据和周期数据对RMSE的影响 (3)基于流量预…

2. seaborn-可视化分类数据
在seaborn中,有几种不同的方法可以对分类数据进行可视化。类似于relplot()与scatterplot()或者lineplot()之间的关系,有两种方法可以制作这些图。有许多axes-level函数可以用不同的方式绘制分类数据,还有一个figure-level接口catplot()&#…
Pandas实战100例 | 案例 21: 条件运算
案例 21: 条件运算
知识点讲解
在 Pandas 中进行条件运算可以用于创建新的列或修改现有的列,基于一定的条件逻辑。这些运算通常结合布尔索引或 apply 方法进行。
布尔条件运算: 可以根据列之间的比较生成布尔值列。apply 方法进行条件运算: 使用 apply 方法可以在…
数据分析-Pandas如何转换产生新列
数据分析-Pandas如何转换产生新列
时间序列数据在数据分析建模中很常见,例如天气预报,空气状态监测,股票交易等金融场景。此处选择巴黎、伦敦欧洲城市空气质量监测 N O 2 NO_2 NO2数据作为样例。
python数据分析-数据表读写到pandas
经典…
数据可视化|Python之Pyecharts将“爬虫数据”绘制饼状图
前言 本文是该专栏的第40篇,后面会持续分享python数据分析的干货知识,记得关注。
在项目中,可能有些同学或多或少遇见这样的需求。将爬虫采集下来的数据,进行图像可视化处理,方便其他业务线进行数据分析处理。
而本文,笔者将以某个爬虫案例的采集数据为例子,使用Pytho…
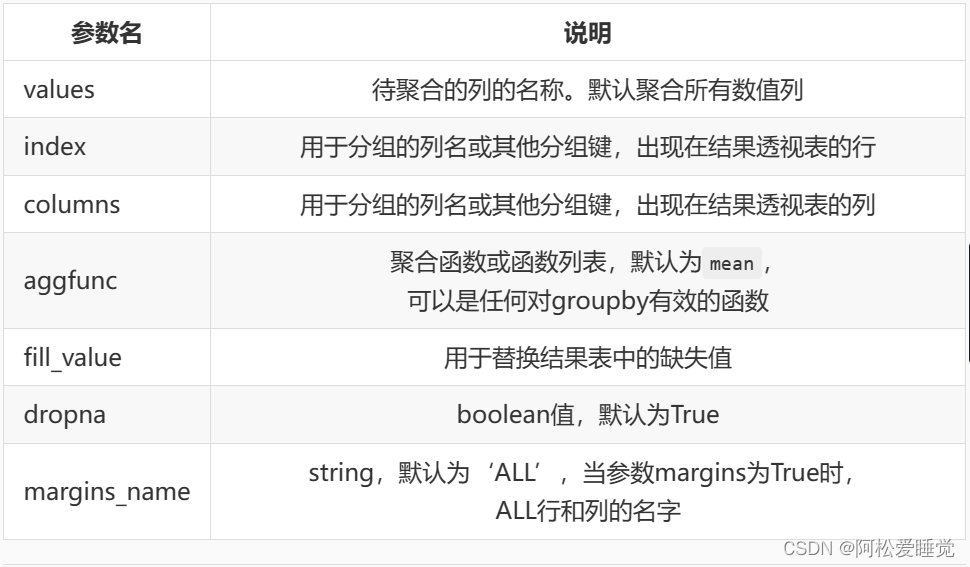
Pandas透视表与交叉表_Python数据分析与可视化
这里写目录标题 透视表交叉表 透视表
透视表是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行聚合,并根据行和列上得分组建将数据分配到各个矩形区域中。在 pandas 中,可以通过 pivot_table 函数创建透视表…
Python爬虫实战-批量爬取豆瓣电影排行信息
大家好,我是python222小锋老师。
近日锋哥又卷了一波Python实战课程-批量爬取豆瓣电影排行信息,主要是巩固下Python爬虫基础
视频版教程:
Python爬虫实战-批量爬取豆瓣电影排行信息 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取豆瓣…
Pandas实战100例 | 案例 57: 执行不同类型的连接操作
案例 57: 执行不同类型的连接操作
知识点讲解
Pandas 提供了强大的数据连接功能,类似于 SQL 的 JOIN 操作。你可以根据一个或多个键将不同的 DataFrame 结合在一起。连接的类型包括内连接、左连接、右连接和外连接。 内连接 (Inner Join): 只保留两个 DataFrame 都有的键。左…
pandas dataframe写入excel的多个sheet页面
pandas根据dataframe生成一个excel文件:
Dataframe保存新文件
直接把dataframe格式的数据保存到多个sheet页程序如下:
excel_file "导出excel文件.xlsx"
if os.path.exists(excel_file):os.remove(excel_file)# 生成一个新文件
with pd.Ex…
python爬虫——抓取表格pandas当爬虫用超简单
pandas还能当爬虫用,你敢信吗?而且超级简单,两行代码就趴下来
只要想提取的表格是属于<table 标签内,就可以使用pd.read_html(),它可以将网页上的表格都抓取下来,并以DataFrame的形式装在一个列表中返回…

大数据处理,Pandas与SQL高效读写大型数据集
大家好,使用Pandas和SQL高效地从数据库中读取、处理和写入大型数据集,以实现最佳性能和内存管理,这是十分重要的。 处理大型数据集往往是一项挑战,特别是在涉及到从数据库读取和写入数据时。将整个数据集加载到内存中的传统方法可…
python sklearn labelencoder、OneHotEncoder和get_dummies的区别
文章目录 labelencoderOneHotEncoderget_dummiesLabelBinarizer labelencoder
LabelEncoder 将不连续的数字or文本进行编号
import numpy as np
import pandas as pd
data pd.DataFrame({"学号":[1001,1002,1003,1004],"性别":["男","女…
数据分析-Pandas如何处理表格中的文本数据
数据分析-Pandas如何处理表格中的文本数据
数据分析和处理中,难免会遇到文本数据,比如人名,地名,还有其他的场景描述等等。金融数据,风控数据,营销数据等等,莫不如此。如何用pandas处理文本数据…
70_Pandas中获取最大最小值的行名和列名
70_Pandas中获取最大最小值的行名和列名
使用 idxmax() 和 idxmin() 方法获取 pandas.DataFrame 和 pandas.Series 中每列和行的最大值和最小值元素的行名和列名。
pandas.DataFrame 和 pandas.Series 都有 idxmax() 和 idxmin() 方法。 在此对以下内容进行说明。
获取最大值…
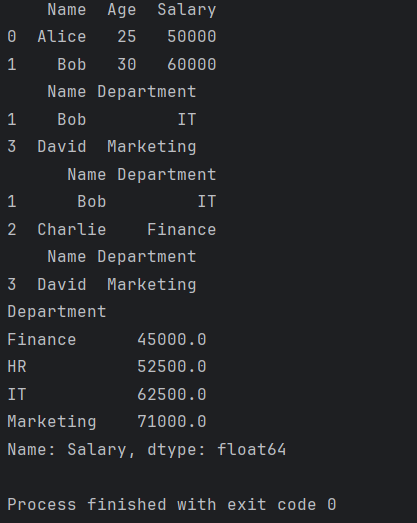
掌握Pandas数据筛选方法与高级应用全解析【第70篇—python:数据筛选】
文章目录 掌握Pandas:数据筛选方法与高级应用全解析1. between方法2. isin方法3. loc方法4. iloc方法5. 查询复杂条件的结合应用6. 避免inplace参数7. 利用Lambda函数进行自定义筛选8. 处理缺失值9. 多条件排序10. 数据统计与分组 总结: 掌握Pandas&…
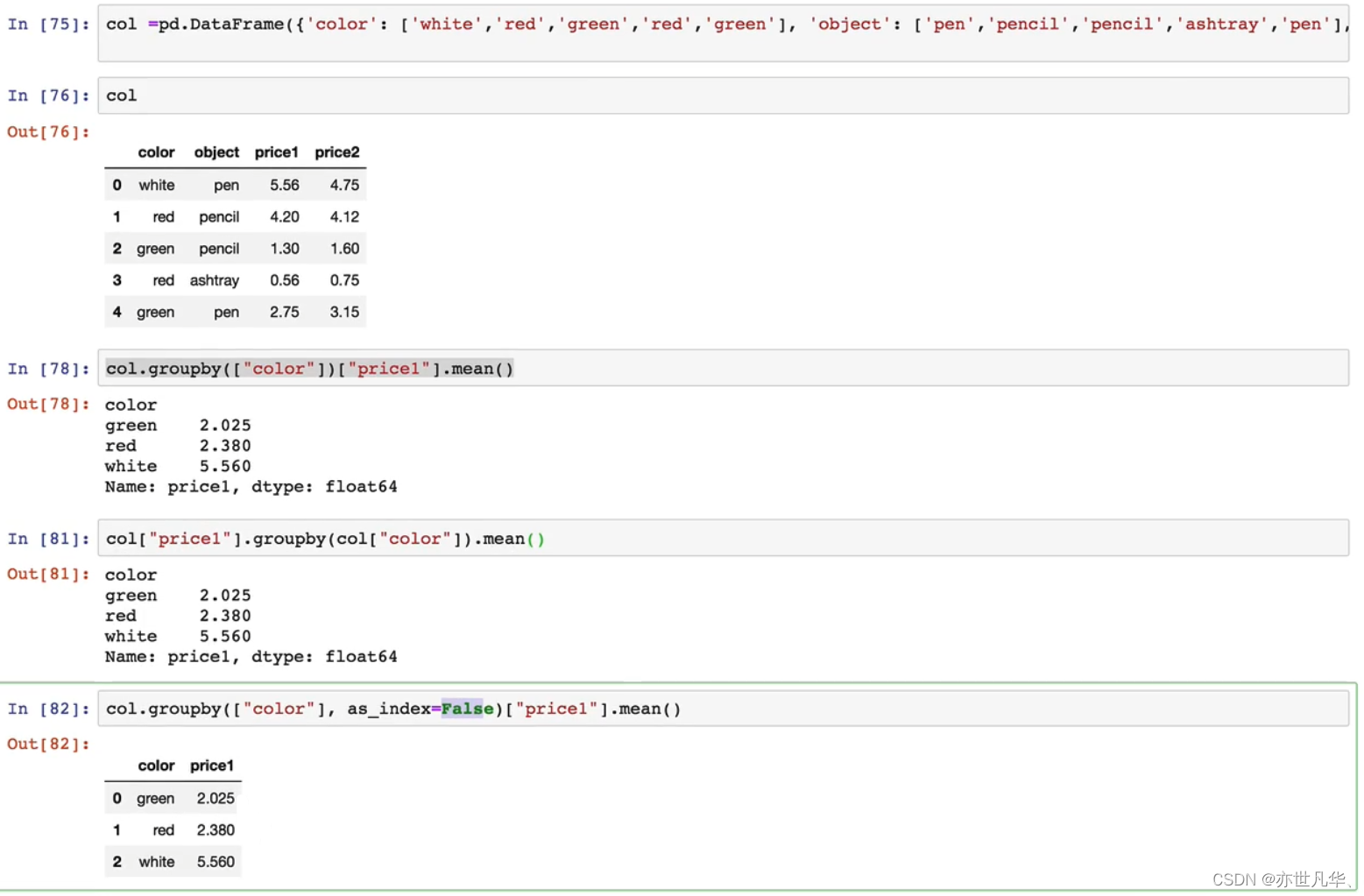
机器学习 | 利用Pandas进入高级数据分析领域
目录
初识Pandas
Pandas数据结构
基本数据操作
DataFrame运算
文件读取与存储
高级数据处理 初识Pandas
Pandas是2008年WesMcKinney开发出的库,专门用于数据挖掘的开源python库,以Numpy为基础,借力Numpy模块在计算方面性能高的优势&am…

使用文件读取的open 函数,让你的csv pandas 尾部插入快如闪电
文章目录 简介1. pandas loc 尾部插入方法loc 尾部插入的速度 2. open 方法open方法 处理csv的速度open方法 处理csv代码 简介
笔者在处理稍大型(几十万条)的csv文件时,发现在csv文件中,使用panda的loc方法进行拼接,速度太过于缓慢。 笔者提…
Pandas Series 的学习笔记
Pandas Series 的学习笔记 0. Pandas 简介1. Series 学习1-1. 创建 Series1-2. 索引1-3. 选择数据1-4. 修改 Series1-5. Series 的操作 2. 结论 0. Pandas 简介
想象一下,你有一张超级大的餐桌,上面放满了各种各样的食物。Pandas 就像是这张餐桌&#x…
数据分析 — Pandas 数据处理
目录 一、简介1、概念2、特点3、引用 二、数据结构1、Series2、DataFrame 三、常见操作1、数据合并2、数据删除3、创建多层索引4、数据对齐5、排序6、DataFrame 和 Series 之间的运算 四、应用 一、简介
1、概念
Pandas(Python Data Analysis Library)…

数据分析 — Pandas 数据加载、存储和清洗
目录 一、文件读取1、常见文件读取函数2、read_csv()3、read_table()4、read_excel()5、read_json()6、read_html()7、大文件读取 二、数据保存1、csv2、excel3、json4、html5、MySQL1、连接数据库2、MySQL 存储到本地3、本地存储到 MySQL 三、数据清洗1、处理缺失值1、判断数据…
数据分析Pandas专栏---第三章<Pandas合并list和字典>
正文:
在处理数据时,经常会遇到需要操作和转换DataFrame的场景。特别是当涉及到从单个或多个字典合成DataFrame,以及合并多个DataFrame时,适当的方法和技巧可以极大地简化程序逻辑并提高代码的可读性与效率。此外,数据操作过程中…

Python3,除Pandas、Numpy之外,有一款受到数据科学家和数据分析师青睐的库。
orange3 1、引言2、orange3介绍2.1 定义2.2 特点2.3 常用功能2.3.1 安装2.3.2 数据可视化2.3.3 数据导入2.3.4 机器学习建模 3、总结 1、引言
**小屌丝:**鱼哥,你看这是啥。
小鱼: 小砂糖橘,是广西的吗。 小屌丝:……

Pandas实践指南:从基础到高级数据分析
Pandas实践指南:从基础到高级数据分析 引言Pandas基础1. 安装和基本配置2. DataFrame和Series的基础3. 基础数据操作 数据清洗与预处理1. 缺失值处理2. 数据转换3. 数据过滤 数据分析与操作1. 数据聚合和分组操作2. 时间序列数据处理3. 条件逻辑和数据分割 高级数据…
如何多个excel中的数据分发到多个excel中去
这个问题之前有一个文章我写了这个方法,但是后来发现效率太低了,于是再次更新一下对应的技术方案,提速5000倍。
一下代码主要实现的功能:
我有5000多个excel文件,每个文件是一只股票从上市至今的日K交易数据࿰…

比较 pandas 和 Polars 的处理速度和易用性
如果使用 Python,肯定会使用的库之一就是 pandas。 这是一个优秀的库,可以轻松处理表数据,其中一个后继者的库是 Polars。
尤其是在速度方面比pandas有优势,可以看作是能够解决pandas的弱点。
这次,想测量一下 panda…

【数据分析】pandas (三)
基本功能
在这里,我们将讨论pandas数据结构中常见的许多基本功能 让我们创建一些示例对象: index pd.date_range(“1/1/2000”, periods8) s pd.Series(np.random.randn(5), index[“a”, “b”, “c”, “d”, “e”]). df pd.DataFrame(np.random.…
【Pandas】学习笔记之groupby()、agg()、transform()
在数据分析过程中经常需要对数据集进行分组,并且统计均值,最大值等等。那么 groupby() 的学习就十分有必要了 groupby(): 分组
官方文档:
DataFrame.groupby(byNone, axis0, levelNone, as_indexTrue, sortTrue, group_keysTrue, observedF…
pandas 索引常用操作
索引操作
建立索引 df.set_index(‘name’) # 设置name列为索引 df.set_index([‘name’,‘team’]) #设置层级索引 df.set_index([df.name.str[0],‘name’]) #设置层级索引 df.set_index(‘name’,inplaceTrue) #设置 inplaceTrue参数可以直接修改原df spd.Series(i for i i…
(2)原神角色数据分析-2
功能一:
得到某个属性的全部角色,将其封装在class中
"""各元素角色信息:一对多"""
from pandas import DataFrame, Series
import pandas as pd
import numpy as npclass FindType:# 自动执行,将…
Streamlit 入门教程:构建一个Dashboard
Streamlit 是一个用于创建数据科学和机器学习应用程序的开源 Python 库。它的主要目标是使开发人员能够以简单的方式快速构建交互式的数据应用,而无需过多的前端开发经验。Streamlit 提供了一种简单的方法来转换数据脚本或分析代码为具有可视化界面的应用程序&#…
【Pandas 入门-1】数据的创建/读取/存储/查看/修改
文章目录 1.1 创建,读取与存储数据1.1.1 创建数据1.1.2 读取数据1.1.3 存储数据 1.2 查看与修改数据1.2.1 查看单行,单列,单元格数据1.2.2 查看多行,多列数据1.2.3 修改数据 pandas 是 Python 做统计分析时最重要的数据分析工具之…

(6)所有角色数据分析-6
http://t.csdn.cn/KrurEhttp://t.csdn.cn/KrurE
(5)中的页面,倾向于向用户展示所有数据,但却没有对数据进行比较、分析,用户不能直观的感受到各种数据之间的关系与变化幅度,所以,下面将向用户提…
NumPy和Pandas库的基本用法,用于数据处理和分析
当涉及到数据处理和分析时,NumPy和Pandas是两个非常常用的Python库。下面是它们的基本用法:
NumPy(Numerical Python):
导入NumPy库:在代码中使用import numpy as np导入NumPy库。
创建NumPy数组:使用np.array()函数可以创建一个NumPy数组。例如,arr = np.array([1,…

百日筑基篇——Pandas学习三(pyhton入门八)
百日筑基篇——Pandas学习三(pyhton入门八) 文章目录 前言一、数据排序二、字符串处理三、数据合并方法1. merge方法2. concat方法 四、分组数据统计五、数据重塑1. stack2. pivot 总结 前言
上一篇文章介绍了一下pandas库中的一些函数,而本…
【Leetcode 30天Pandas挑战】学习记录 下
题目列表: 数据统计:2082. The Number of Rich Customers1173. Immediate Food Delivery I1907. Count Salary Categories 数据分组1741. Find Total Time Spent by Each Employee511. Game Play Analysis I2356. Number of Unique Subjects Taught by Each Teacher…

pandas数据分析39——数据透视表简单实现
案例实现
其实就是两个分类变量,组成多少种出现的情况,类似于混淆矩阵,交叉表。 代码实现
df pd.DataFrame({时间: [*AABBBA],地区: [*xxyzzz]})
df[值]np.random.randint(1,3,size(6,))
df 时间地区是我给的样例名称,还可以是…
RESTful API 主流API风格
RESTful 入门
一、什么是Restful
REST 是 Representational State Transfer 的缩写,如果一个架构符合 REST 原则,就称它为 RESTful 架构RESTful 架构可以充分的利用 HTTP 协议的各种功能,是 HTTP 协议的最佳实践 RESTful API 是一种软件架…
记一次减少Pandas DataFrame在科学计算中的内存占用
代码:
废话不多说直接上代码验证这个方法。详细内容可以看后面的说明。
import pandas as pd
import psutildef mem_usage(pandas_obj):if isinstance(pandas_obj,pd.DataFrame):usage_b pandas_obj.memory_usage(deepTrue).sum()else: # 我们假设这不是一个df&a…

【python】一些常用的pandas技巧
有了gpt之后,确实很多代码都可以让gpt给改错。嘎嘎香 merge多个dateframe
https://stackoverflow.com/questions/44327999/how-to-merge-multiple-dataframes
data_net [a,b,c,d]
net_merged reduce(lambda left,right: pd.merge(left,right,on[key column],ho…
【机器学习6】数据预处理(三)——处理类别数据(有序数据和标称数据)
处理类别数据 🌱简要理解处理类别数据的重要性☘️类别数据的分类☘️方便研究——用pandas创建包含多种特征的数据集🍀映射有序特征🍀标称特征标签编码🍀标称特征的独热编码🌱独热编码的优缺点 🌱简要理解…
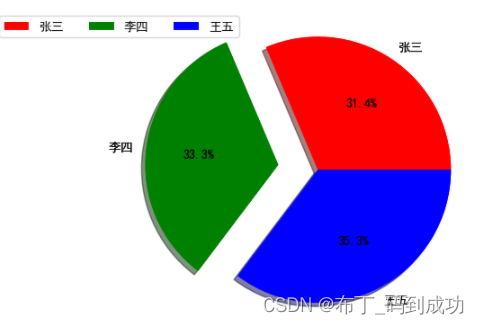
「缤纷色彩的饼状图」:通过使用matplotlib库绘制饼状图,让读者期待在这个色彩缤纷的图表中探索数据的美丽。
嘿,大家好!今天我要带你们探索一个有趣的话题:使用matplotlib库绘制饼状图。虽然这听起来可能有些复杂,但我会用轻松幽默的语言给大家讲解!准备好了吗?让我们开始吧! 首先,我们需要导…
python pandas常用数据处理方法
pandas 1、header 0 不同于 header Noneheader 0 表示 第0行为列header None 表示读取的时候 认为没有标题,全是数据可以用 skiprows 1 跳过列名2、pandas 获取指定的行列数据df.iloc[0:2,[0,3]] #读取 第 [0,2)行的第[0,3)列3、创建 df DataFram(data,index…
pyspark融入pandas的优势,真香!
近期,在使用spark的时候,发现spark在python下的使用,pyspark还挺好用的。
你甚至可以把它当作pandas来使用,众所周知,pandas在数据处理方面是很强大的,不谈性能,它提供了许多的内置方法&#x…
pandas 学习笔记
读者只需浏览一下本文的目录结构,我相信就已经掌握了1到2成的 pandas 知识。
本文的目的是建立一个大概的知识结构
在数据挖掘python阅读源码时,断断续续查阅了些 pandas 资料,并在源码中大致感受到了 pandas 在数据清理方面的方便性。
先…
63_Pandas中数字的四舍五入
63_Pandas中数字的四舍五入
要对 pandas.DataFrame、pandas.Series 的数字进行四舍五入,请使用 round() 方法。 round() 方法舍入为偶数而不是四舍五入。
如果要四舍五入,请将标准库十进制模块的 quantize() 应用于每个元素。
本示例代码中的各个版本…

【工程实践】使用pandas的记录
前言 工作中处理数据时,经常需要使用pandas,记录一些工作中使用pandas的习惯。 1. 合并数据
#读取原始数据
data1 pd.read_excel(/home/zhenhengdong/WORk/Classfier/Dates/Original/1.xlsx)
data2 pd.read_excel(/home/zhenhengdong/WORk/Classfier/…
pandas 的apply返回多列
网上有一些解决方案:
1:使用apply 的参数result_type 来处理
2:使用zip打包返回结果来处理
具体方法在这里:pandas 的apply返回多列,并赋值 - 简书 还有一种思路比较简单直接:
def func(df):return 0, …
大数据(八):Pandas的基础应用详解(五)
专栏介绍
结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来!
全部文章请访问专栏:《Python全栈教…
python基础操作笔记
一,pickle读写json格式文件pkl
k
Out[15]: {k1: 2, k3: 4}with open("test822.pkl","wb") as f:pickle.dump(k,f,) with open("test822.pkl","rb") as f:kk=pickle.load(f)kk==k
Out[20]: True
二、docker删除image
docker rmi …
【Python】【Fintech】解决用pandas_datareader从yahoo下载股票数据时出错
【背景】
要做一个预测投资组合portfolio未来收益的python脚本,类似的功能需要从数据源获取相关指数和股票的数据,一直以来都是用pandas_datareader从yahoo上面拿,但是后来忽然发现不能用了,这篇就说明一下遇到此问题的walk around.
【分析】
由于数据源是yahoo那边的,…
【Pandas 入门-2】增加,删除与合并数据 concat, merge
文章目录 1.3 增加,删除与合并数据1.3.1 增加数据1.3.2 删除数据1.3.3 合并数据 1.3 增加,删除与合并数据
1.3.1 增加数据
在原数据末尾增加一列时,语法为 df[‘新列名] 某个值或某个元素个数与 DataFrame 列数相同的列表,例如…
大数据(四):Pandas的基础应用详解
专栏介绍
结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来!
全部文章请访问专栏:《Python全栈教…
Titanic--细节记录二
目录 merge、join以及concat的方法的不同以及相同 merge
join
concat stack函数
agg函数
countplot--计算条形统计图 FacetGrid
kdeplot--核密度估计图
facet.set facet.add_legend()
折线图表示年龄分布情况
为什么所有的曲线都被添加到同一个图上:
填充…
pandas读取csv文件——你真的了解pandas.read_csv的参数吗?
pandas.read_csv 所有参数 pandas.read_csv参数详解1. filepath_or_buffer(目标数据)2. sep(分隔符)3. delimiter(同sep,分隔符)4. header(决定列名)5. names(…
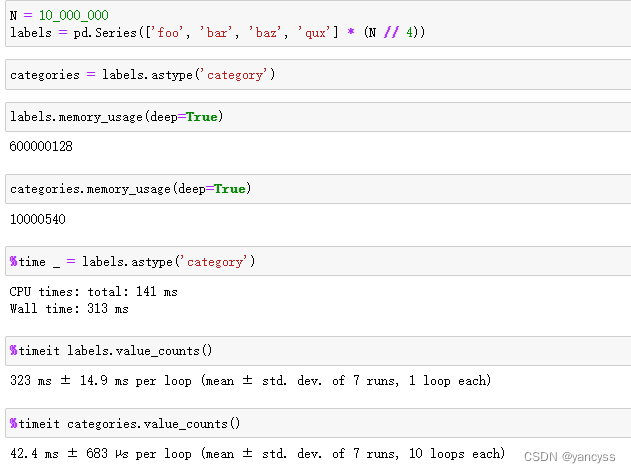
Pandas-02-数据清洗预处理
pandas-02-数据清洗&预处理 A.缺失值处理1. Pandas缺失值判断2. 缺失值过滤2.1 Series.dropna()2.2 DataFrame.dropna() 3. 缺失值填充3.1 值填充3.2 向前/向后填充 B. 数据处理1. 重复值处理2. map逐元素转换3. 值替换4. 改变索引值5. 离散化与分箱6. 检测过滤异常值7. 排…
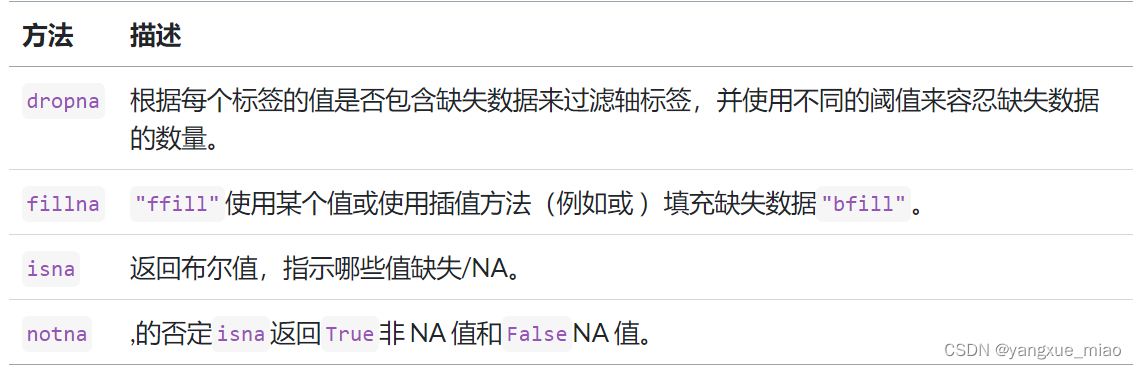
pandas数据分析教程-数据清洗-缺失值处理
pandas-02-数据清洗&预处理 A.缺失值处理1. Pandas缺失值判断2. 缺失值过滤2.1 Series.dropna()2.2 DataFrame.dropna()3. 缺失值填充3.1 值填充3.2 向前/向后填充文中用S代指Series,用Df代指DataFrame 数据清洗是处理大型复杂情况数据必不可少的步骤,这里总结一些数据清…
Pandas由入门到精通-组合与合并数据
采集的数据存储后通常会分为多个文件或数据库,如何将这些文件按需拼接,或按键进行连接十分重要。这节将介绍数据索引的复杂操作如分层索引,stack,unstack,seet_index,reset_index等帮助重构数据,数据的拼接如merge,join,concat,combine_first等帮助连接数据,以及数据透视表…
如何使用NumPy和Pandas库进行数据合并和连接操作?
使用NumPy和Pandas库进行数据合并和连接操作可以方便地组合和整合多个数据集。下面是使用这两个库进行数据合并和连接的基本方法:
NumPy:
NumPy库主要用于数组操作,它提供了一些函数来进行简单的数组合并操作。
使用np.concatenate()函数可以按照指定的轴将多个数组沿该轴…
【Pandas】pd.concat和pd.merge的区别
前言
最近做了一个数据挖掘的项目,里面涉及到大量dataframe拼接的操作。在这个过程中,我主要使用过两种拼接方法:pd.merge和pd.concat。其中遇到过一些坑,在这里记录一下。
简介
首先给出pandas官方文档对于这两种方法的介绍&a…

python,pandas ,openpyxl提取excel特定数据,合并单元格合并列,设置表格格式,设置字体颜色,
python,pandas ,openpyxl提取excel特定数据,合并单元格合并列,设置表格格式,设置字体颜色,
代码
import osimport numpy
import pandas as pd
import openpyxl
from openpyxl.styles import Font
from op…
pandas由入门到精通-pandas的数据结构
pandas数据分析-pandas的数据结构 pandas 数据结构Series1. 创建Series数组2. 性质3. 索引4. 运算DataFrame1. 创建Df数组2. 性质3.索引4. 对列进行增删改Index Objects本文介绍pandas中一些常用的属性方法的概述,给读者提供快速学习的架构和思路。表格中提供的一些参数方法没…

【数据分析入门】Jupyter Notebook
目录 一、保存/加载二、适用多种编程语言三、编写代码与文本3.1 编辑单元格3.2 插入单元格3.3 运行单元格3.4 查看单元格 四、Widgets五、帮助 Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。 …
chatgpt赋能python:Python编译成二进制文件:优化代码执行效率
Python编译成二进制文件:优化代码执行效率
介绍
随着Python编程的不断普及,越来越多的开发者选择Python作为开发工具。然而,Python解释器需要读取并解释源代码,这种解释方式在执行效率上存在瓶颈。为了提高执行效率,…
牛客周赛 Round 30(A~E)
A A题签到题直接输出0和2即可
#include <bits/stdc.h>
#define rep(i,a,b) for(int i (a); i < (b); i)
#define fep(i,a,b) for(int i (a); i > (b); --i)
#define ls p<<1
#define rs p<<1|1
#define PII pair<int, int>
#define ll long …
自动化报告pptx-python|如何将pandas的表格写入PPTX(二)
本篇延续:自动化报告的前奏|使用python-pptx操作PPT(一) 因为在pptx-python中使用table,需要单个cell逐一输入,于是在想有没有pandas可以直接读入的方式, 有两个开源项目有类似的功能: PandasToPowerpointmspandas其中mspandas写的比较复杂,PandasToPowerpoint比较易懂…
Pandas.DataFrame.var() 方差 详解 含代码 含测试数据集 随Pandas版本持续更新
关于Pandas版本: 本文基于 pandas2.2.0 编写。
关于本文内容更新: 随着pandas的stable版本更迭,本文持续更新,不断完善补充。
传送门: Pandas API参考目录
传送门: Pandas 版本更新及新特性
传送门&…
Pandas.Series.var() 方差 详解 含代码 含测试数据集 随Pandas版本持续更新
关于Pandas版本: 本文基于 pandas2.2.0 编写。
关于本文内容更新: 随着pandas的stable版本更迭,本文持续更新,不断完善补充。
传送门: Pandas API参考目录
传送门: Pandas 版本更新及新特性
传送门&…

Python之Numpy 和 Pandas
目录
2.1 numpy import numpy as np
array np.array([[1,2,3],[2,3,4]])
print(array)
print(number of dim:,array.ndim)
print(shape:,array.shape)
print(size:,array.size)pandas
1,pandas 基本介绍 df2 pd.DataFrame({A:1.,B:pd.Timestamp(20130102),C:pd.Series(1,i…
pandas按行按列遍历Dataframe的三种方式
遍历数据有以下三种方法:
简单对上面三种方法进行说明:
iterrows(): 按行遍历,将DataFrame的每一行迭代为(index, Series)对,可以通过row[name]对元素进行访问。
itertuples(): 按行遍历,将DataFrame的每一行迭代为元…
Pandas实战100例 | 案例 29: 时间序列分析 - 滚动窗口计算
案例 29: 时间序列分析 - 滚动窗口计算
知识点讲解
时间序列数据分析是数据科学中的一个重要领域。Pandas 提供了处理时间序列的强大功能,包括滚动窗口计算。滚动窗口计算可以用于平滑时间序列数据,识别趋势和模式。
滚动窗口计算: 使用 rolling 方法…

像用Excel一样用Python:pandasGUI
文章目录 启动数据导入绘图 启动
众所周知,pandas是Python中著名的数据挖掘模块,以处理表格数据著称,并且具备一定的可视化能力。而pandasGUI则为pandas打造了一个友好的交互窗口,有了这个,就可以像使用Excel一样使用…
数据分析Pandas专栏---第五章<Pandas缺失值的处理(1)>
前言: 当进行数据清洗和处理时,缺失值处理是一个非常重要的步骤。缺失值是指在数据集中某些位置缺少数值或信息。处理缺失值的目标是确保数据的完整性和准确性,以便能够进行后续的分析和建模。
正文:
I. 简介 A. 什么是缺失值
当某个特定数据点未能被…
从新手到高手:用NumPy学习网站打造你的数据处理超能力!
介绍:NumPy是一个用于数值计算的Python库,特别擅长处理多维数组和矩阵。以下是对NumPy的详细介绍: 起源和发展:NumPy由Travis Oliphant在2005年创建,它是基于原来的Numeric模块和Numarray模块发展而来的。它的大部分代…
从Pandas到Polars :数据的ETL和查询
对于我们日常的数据清理、预处理和分析方面的大多数任务,Pandas已经绰绰有余。但是当数据量变得非常大时,它的性能开始下降。
本文将介绍如何将日常的数据ETL和查询过滤的Pandas转换成polars。
图片
Polars的优势 Polars是一个用于Rust和Python的Data…
Python数据处理实战(5)-上万行log数据提取并分类进阶版
系列文章:
0、基本常用功能及其操作
1,20G文件,分类,放入不同文件,每个单独处理
2,数据的归类并处理
3,txt文件指定的数据处理并可视化作图
4,上万行log数据提取并作图进阶版
…

数据分析-Pandas两种分组箱线图比较
数据分析-Pandas两种分组箱线图比较
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&am…
【相关问题解答1】bert中文文本摘要代码:import时无法找到包时,几个潜在的原因和解决方法
【相关问题解答1】bert中文文本摘要代码 写在最前面问题1问题描述一些建议import时无法找到包时,几个潜在的原因和解决方法1. 模块或包的命名冲突解决方法: 2. 错误的导入路径解决方法: 3. 第三方库的使用错误解决方法: 4. 包未正…
数据分析Pandas专栏---第七章<Pandas缺失值的处理(3)>
前言:
数据分析Pandas专栏---第五章<Pandas缺失值的处理(1)>-CSDN博客
数据分析Pandas专栏---第六章<Pandas缺失值的处理(2)>-CSDN博客
正文:
A. 数据预处理技术的选择
在利用Pandas处理数据时,首先了解数据集的基…
保存带 numpy.ndarray 的 dataframe
# 创建 DataFrame
texts ["hi", "hello", "you"]
embeddings [np.random.randn(10,) for i in range(3)]
df pd.DataFrame({"text":texts, "embedding":embeddings})type(df.embedding.values[0]) # numpy.ndarray# 保存…
数据分析Pandas专栏---第七章<Pandas缺失值的处理(4)>
前言:
数据分析Pandas专栏---第五章<Pandas缺失值的处理(1)>-CSDN博客
数据分析Pandas专栏---第六章<Pandas缺失值的处理(2)>-CSDN博客
数据分析Pandas专栏---第七章<Pandas缺失值的处理(3)>-CSDN博客
…
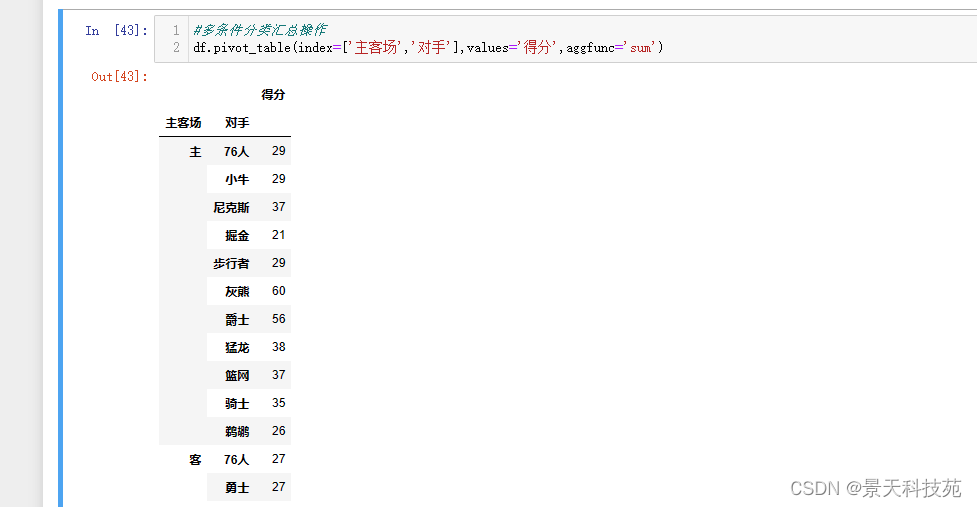
Pandas进阶--map映射,分组聚合和透视pivot_table详解
文章目录 1.Pandas的map映射(1)映射(2)map充当运算工具 2.数据分组和透视(1)分组统计 - groupby功能 是pandas最重要的功能(2)聚合agg 3.透视表pivot_table(1)…
数据分析Pandas专栏---第十二章<Pandas数据聚合与分组(2)>
前言:
继续上一章数据分析Pandas专栏---第十一章<Pandas数据聚合与分组(1)>-CSDN博客
正文:
数据分组与聚合的高级应用
多级分组操作和索引层级
多级分组操作是指在数据分析中,我们可以根据多个列的值进行分组,并形成索引层级…
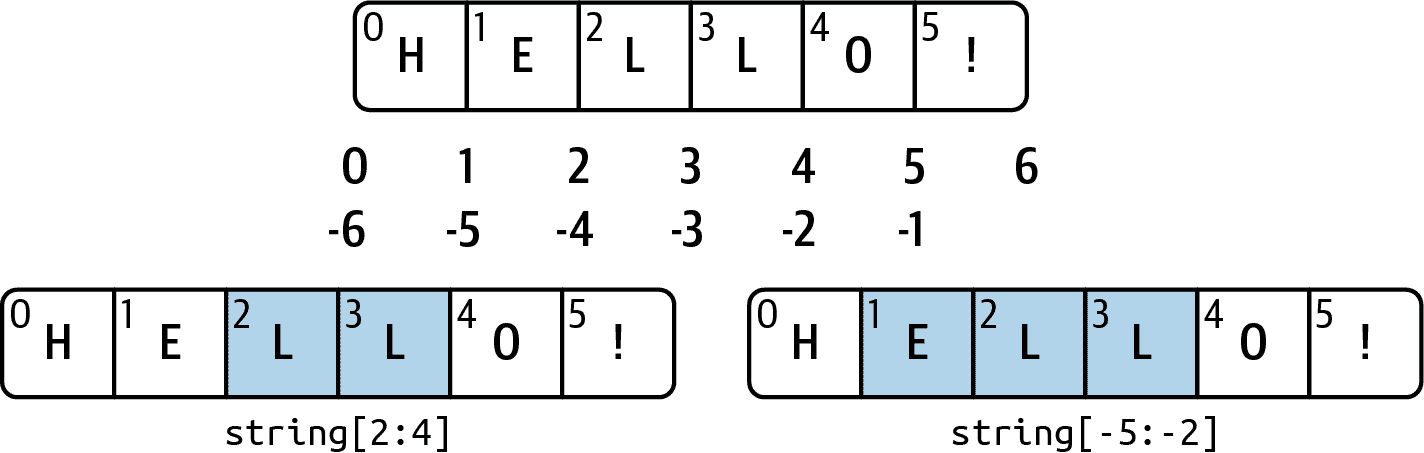
Python 数据分析(PYDA)第三版(一)
原文:wesmckinney.com/book/ 译者:飞龙 协议:CC BY-NC-SA 4.0 关于开放版本
第 3 版的《Python 数据分析》现在作为“开放获取”HTML 版本在此网站wesmckinney.com/book上提供,除了通常的印刷和电子书格式。该版本最初于 2022 年…
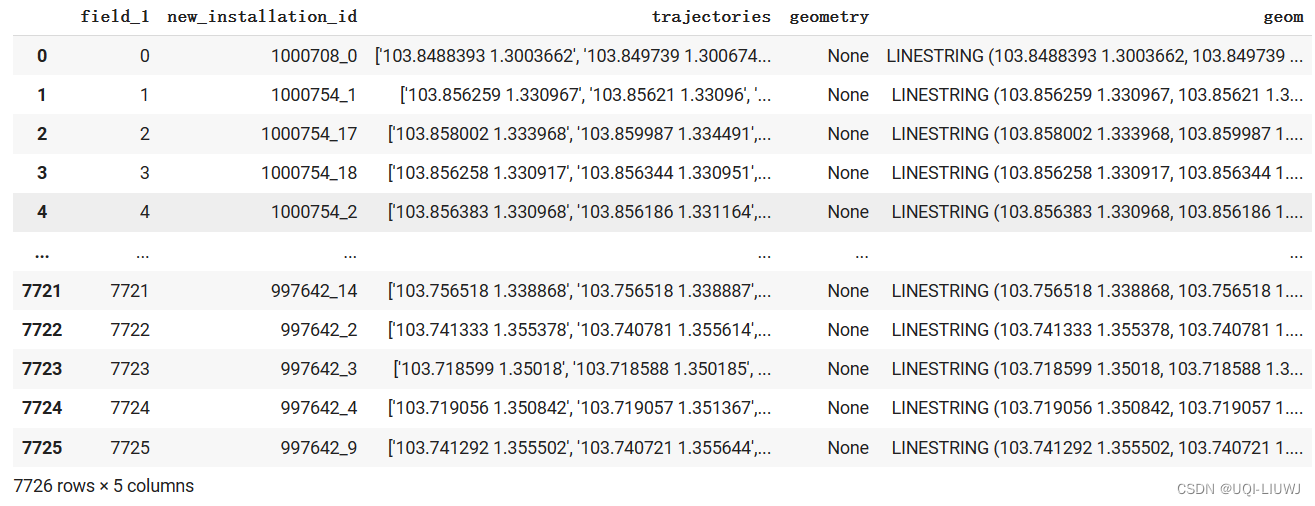
pandas/geopandas 笔记:逐record的轨迹dataFrame转成逐traj_id的轨迹dataFrame
我们现在有这样的一个dataframe,名字为dart 我们需要这样一个DataFrame,每一行有两列,一列是new_installation_id,表示这个轨迹的id;另一列就是这个new_installation_id的轨迹
dart_new dart[[new_installation_id]]…

数据分析-Pandas数据的探查面积图
数据分析-Pandas数据的探查面积图
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&…
Pandas-滑动窗口知识点总结及数据可视化展示
前言 本文是该专栏的第42篇,后面会持续分享python数据分析的干货知识,记得关注。
众所周知,pandas作为一款功能强大的数据分析处理工具,它的高级用法为数据科学领域提供了非常丰富且便捷的分析方法,在现在数据大爆炸的时代,pandas大大提高了数据处理的效率。而在本文中,…

1. import pandas as pd 导入库
【目录】 文章目录 1. import pandas as pd 导入库1. pandas库的概念2. 导入pandas库2.1 常规导入2.2 别名导入 3. 别名的作用4. 课堂练习 【正文】 1. import pandas as pd 导入库
【学习时间】
10分钟
1. pandas库的概念
pandas:熊猫panda的复数, …
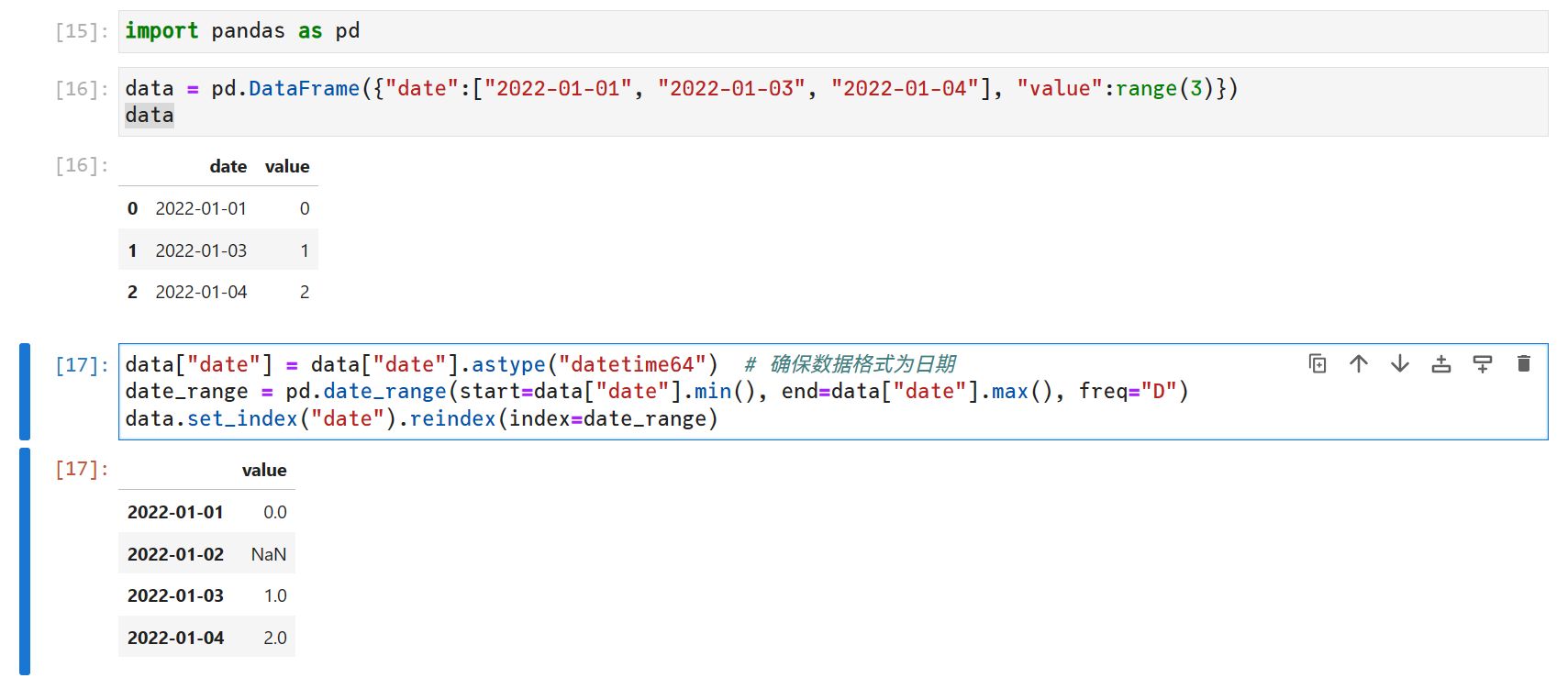
pandas数据分析——groupby得到分组后的数据
groupbyagg分组聚合对数据字段进行合并拼接
Pandas怎样实现groupby聚合后字符串列的合并(四十)
groupby得到分组后的数据
pandas—groupby如何得到分组里的数据
date_range补齐缺失日期
在处理时间序列的数据中,有时候会遇到有些日期的数…

pandas读取excel,再写入excel
需求是这样的,从一个表读取数据,然后每次执行创建一个新表将值写入
读取这个表 写入到这个表 分别对应的是e、h列数据,代码如下:
import pandas as pd
import openpyxl
import datetime
dfpd.read_excel(rC:\Users\admin\Deskt…
数学建模——校园供水系统智能管理
import pandas as pd
data1pd.read_excel("C://Users//JJH//Desktop//E//附件_一季度.xlsx")
data2pd.read_excel("C://Users//JJH//Desktop//E//附件_二季度.xlsx")
data3pd.read_excel("C://Users//JJH//Desktop//E//附件_三季度.xlsx")
data4…
python-数据分析-numpy、pandas、matplotlib的常用方法
一、numpy
import numpy as np1.numpy 数组 和 list 的区别
输出方式不同
里面包含的元素类型
2.构造并访问二维数组
使用 索引/切片 访问ndarray元素
切片 左闭右开
np.array(list) 3.快捷构造高维数组 np.arange() np.random.randn() - - - 服从标准正态分布- - - …
机器学习基础-Pandas学习笔记
Pandas Python的数据分析库,与Numpy配合使用,可以从常见的格式如CSV、JSON等中读取数据。可以进行数据清洗、数据加工工作。数据结构Series,Pandas.Series(data,index,dtype,name,copy) data类型是Numpy的ndarray类型,index指定下…
pandas 读取excel和csv表格数据常见问题及解决
目录 问题一、后缀不对导致无法读取问题二、编码方式不对导致无法读取问题三、pandas怎么追加写入excel ?问题四、pandas无法从指定单元格开始写入excel问题五、pandas写入excel时,无法给后缀添加写入时间问题六、pandas 无法实时的查看表问题七、pandas…
使用Python构造VARIMA模型
简介
VARMA(p,q)结合了VAR和VMA模型,其中p是向量自回归(VAR)模型的滞后期数,q是VMA模型的移动平均的阶数。
VARMA是ARMA的推广,它将ARMA模型扩展到多个时间序列变量的情况,通过VAR和VMA的线性组合来描述多个时间序列变量之间的联…
pandas教程:Hierarchical Indexing 分层索引、排序和统计
文章目录 Chapter 8 Data Wrangling: Join, Combine, and Reshape(数据加工:加入, 结合, 变型)8.1 Hierarchical Indexing(分层索引)1 Reordering and Sorting Levels(重排序和层级排序)2 Summa…

Python的pandas库来实现将Excel文件转换为JSON格式的操作
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…
pandas(四十四)pandas100个神仙级用法
一、如何将一个列表转成Pandas的数据框
列表类型,需要指定列名columns;不指定默认 0、1、2my_friend [[zhangsan, 18, 男], [lisi, 17, 女]]
df pd.DataFrame(my_friend, columns[unasename, age, gender])
df字典,可不指定列名columns&am…

Pandas中at、iat函数详解
前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐 at 函数:通过行名和列名来取值(取行名为a, 列名为A的值) iat 函数:通过行号和列号来取值(取第1行,第1列的值)
本文给出at、iat常见的…
pandas notes 25
1.显示已安装的版本
pd.__version__
pd.show_versions() 2.创建示例DataFrame 3.更改列名
df df.rename({ col one : col_one , col two : col_two }, axis columns )
df.columns [ col_one , col_two ]
如果你需要在列名中添加前缀或者后缀,你可以使用add…

Numpy和Pandas简介
推荐:使用NSDT场景编辑器快速搭建3D应用场景
如果您正在从事数据科学项目,Python 包将简化您的生活,因为您只需要几行代码即可执行复杂的操作,例如操作数据和应用机器学习/深度学习模型。
在开始你的数据科学之旅时,…
GIS小技术分享(一):python中json数据转geojson或者shp
1.环境需求
geopandspandasshapelyjsonpython3
2.输入数据(path字段,线条)
[{"id": "586A685D568311B2A16F33FCD5055F7B","name": "普及江","path": "[[116.35178835446628,23.57…
【案例+操作+演示】20分钟带你入门Pandas,掌握数据分析科学模块,附带上百个案例练习题【含答案】
二十分钟入门pandas,学不会私信教学!
有需要pyecharts资源的可以点击文章上面下载!!!
需要本项目运行源码可以点击资源进行下载
资源
#coding:utf8
%matplotlib inline这个一篇针对pandas新手的简短入门࿰…
如何使用 Python 中 Pandas 进行数据分析?
Pandas是Python中一个常用的数据分析库,它提供了丰富的数据结构和工具,可以轻松地进行数据分析和处理。下面是一些使用Pandas进行数据分析的示例:
1、加载数据
在进行数据分析之前,我们需要加载数据。Pandas提供了多种方法来加载…

08-pandas 入门-pandas的数据结构
要使用pandas,你首先就得熟悉它的两个主要数据结构:Series和DataFrame。虽然它们并不能解决所有问题,但它们为大多数应用提供了一种可靠的、易于使用的基础。
一、Series
Series是一种类似于一维数组的对象,它由一组数据&#x…
Pandas 入门指南
当涉及到数据处理和分析的任务时,Pandas(Python Data Analysis Library)是一款不可或缺的工具。Pandas提供了强大的数据结构和数据操作功能,使得处理和分析结构化数据变得更加容易。在这篇技术博客中,我们将总结Pandas…
01-jupyter notebook的使用方法
一、Tab补全
在shell中输入表达式,按下Tab,会搜索已输入变量(对象、函数等等)的命名空间: 除了补全命名、对象和模块属性,Tab还可以补全其它的。当输入看似文件路径时 (即使是Python字符串&…
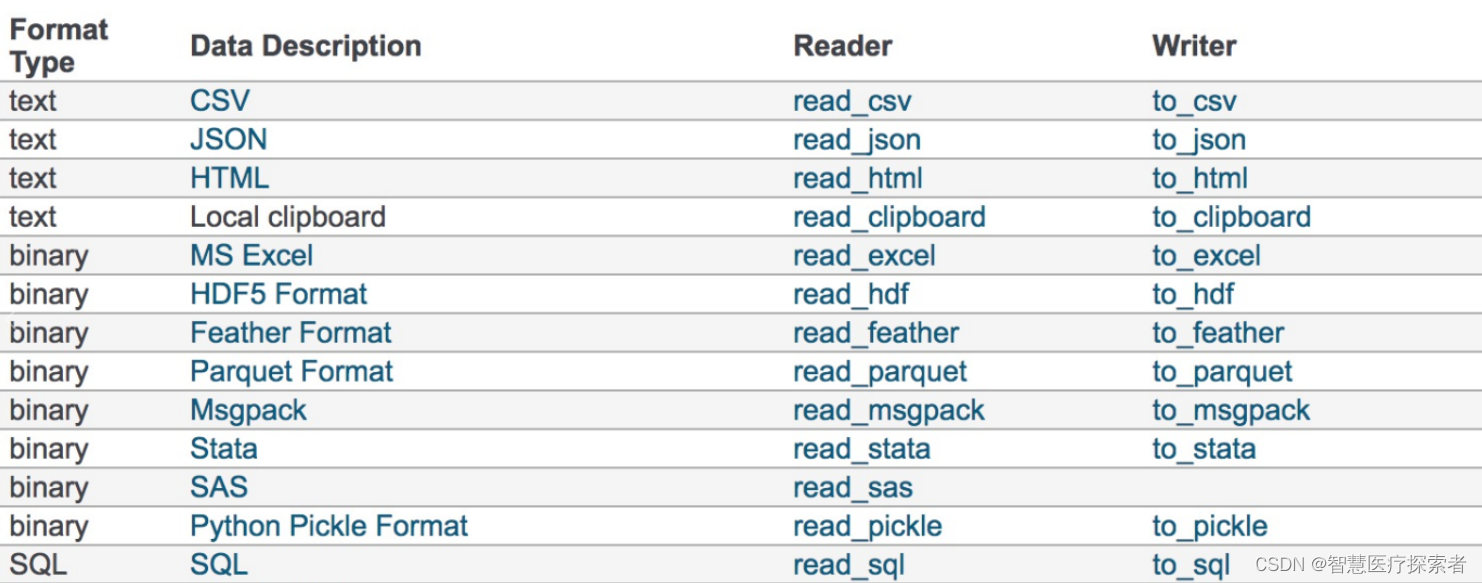
数据分析三剑客之一:Pandas详解
目录 1 Pandas介绍
2 Pandas的安装与导入
2.1 Pandas模块安装
2.2 Pandas模块导入
3 pandas数据结构及函数
3.1 Series结构
3.1.1 ndarray创建Series对象
3.1.2 dict创建Series对象
3.1.3 标量创建Series对象
3.1.4 位置索引访问Series数据
3.1.5 标签索引访问Series…
pandas_使用总结(1)
取值操作
常用方式
df[‘Q1’] # 选择‘Q1’列,同df.Q1,返回一个Seriesdf[[‘name’,‘Q1’]] # 选择多列,注意括号df[0:3] # 取前三行df[0:10:2] # 0到前10行中每两行取一次数据(python 切片操作: start : end : st…

在pandas中使matplotlib动态画子图的两种方法【推荐gridspec】
先上对比图,
第一种方法,这里仅展示1个大区,多个的话需要加一层循环就可以了,主要是看子图的画法
当大区下面的国家为1个或2个时,会进行报错
# 获取非洲国家列表
african_countries df[df[大区] 南亚大区][进口国…

python监控ES索引数量变化
文章目录 1, datafram根据相同的key聚合2, 数据合并:获取采集10,20,30分钟es索引数据脚本测试验证 1, datafram根据相同的key聚合
# 创建df1 > json {key:A, value:1 } {key:B, value:2 }
data1 {key: [A, B],
value: [1, 2]}
df1 pd.DataFrame(data1)# 创建d…
【Python】进阶学习:pandas--groupby()用法详解
📊【Python】进阶学习:pandas–groupby()用法详解 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈…

数据分析-Pandas数据的直方图探查
数据分析-Pandas数据的直方图探查
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&…
【Python】进阶学习:pandas--query()用法详解
📚【Python】进阶学习:pandas–query()用法详解 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希…

数据分析-Pandas数据的画图设置
数据分析-Pandas数据的画图设置
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&#x…
Python3 交叉编译 numpy pandas scipy scikit-learn
1. 概述
由于需要将Python3.7 和一些软件包交叉编译到 armv7 平台硬件,如果是arm64位的系统,很多包都有预编译好的版本,可直接下载。本文主要在基于 crossenv(https://github.com/benfogle/crossenv)环境下交叉编译。
2. 编译环境搭建
创建…
使用 Python 快速开始机器学习
🔗 快速开始 PyTorch|使用 Python 建立深度学习模型
认识 PyTorch 1.1 Torch 与 PyTorch 1.2 安装 PyTorch 1.3 验证安装并查看 PyTorch 版本PyTorch 深度学习模型的建立范式 2.1 准备数据 2.2 定义模型 2.3 训练模型 2.4 评估模型 2.5 做出预测为预测任…
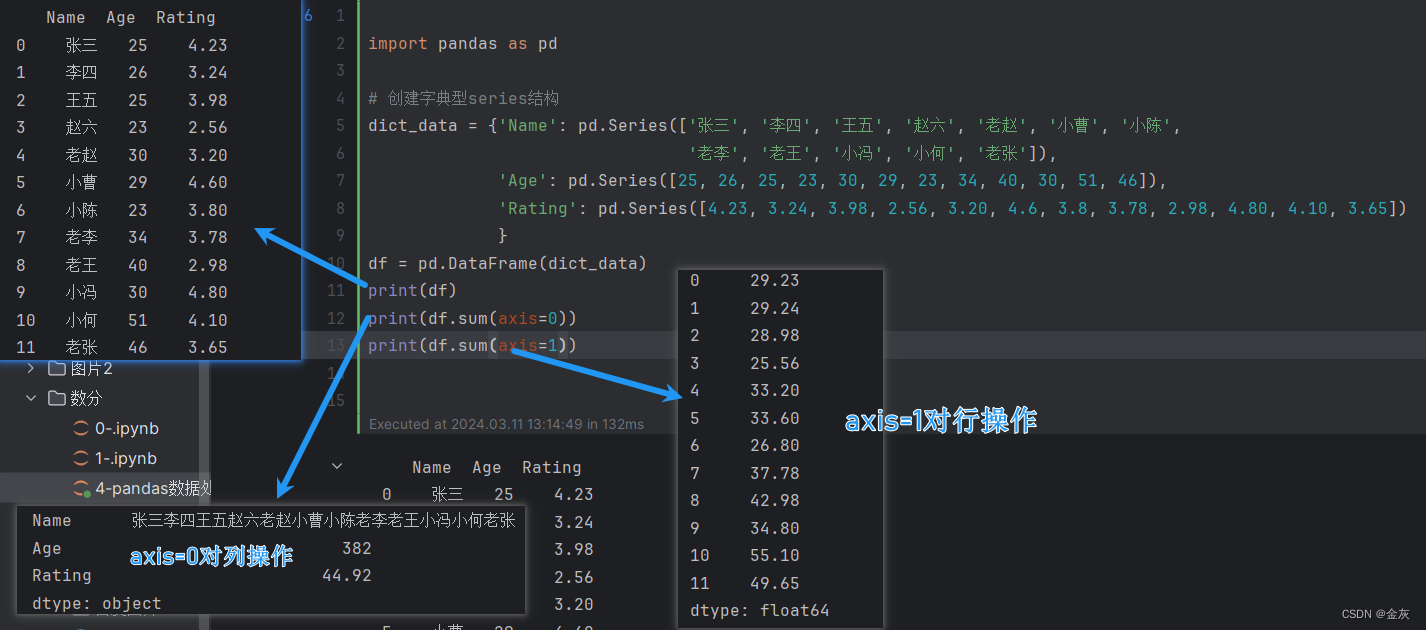
四.pandas数据处理
目录
四.pandas数据处理
1.Pandas数据计算
演示代码
1-sum()求和
2-mean()求均值
3-std()求标准差
4-max()求最大值
5-median()中位数
2.reindex重置索引
1-重置行、列标签
2-重命名标签-rename()
3-设置索引列
3.so…
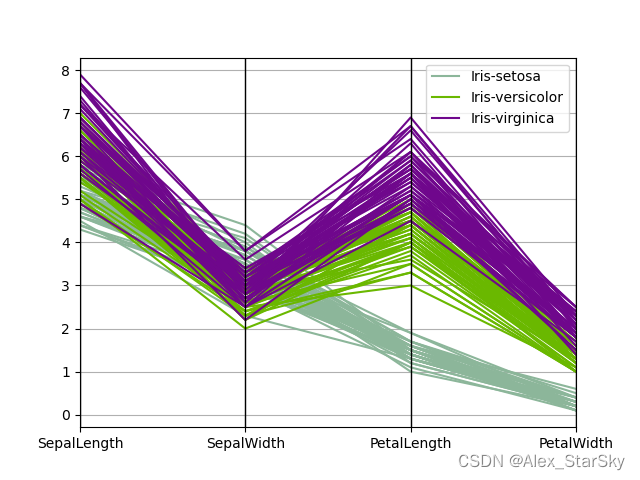
数据分析-Pandas多维数据平行坐标可视化
数据分析-Pandas多维数据平行坐标可视化
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表…

数据分析-Pandas的直接用Matplotlib绘图
数据分析-Pandas的直接用Matplotlib绘图
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表…

【小沐学AI】数据分析的Python库:Pandas AI
文章目录 1、简介2、安装2.1 Python2.2 PandasAI 3、部署4、功能4.1 大型语言模型 (LLM)4.1.1 BambooLLM4.1.2 OpenAI 模型4.1.3 谷歌 PaLM4.1.4 谷歌 Vertexai4.1.5 Azure OpenAI4.1.6 HuggingFace 模型4.1.7 LangChain 模型4.1.8 Amazon Bedrock 模型4…

数据分析-Pandas序列时间移动窗口化操作
数据分析-Pandas序列时间移动窗口化操作
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表…

数据分析-Pandas序列滑动窗口配置参数
数据分析-Pandas序列滑动窗口配置参数
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&…
Python 利用pandas和mysql-connector获取Excel数据写入到MySQL数据库
如何将Excel数据插入到MySQL数据库中
在实际应用中,我们可能需要将Excel表格中的数据导入到MySQL数据库中,以便于进行进一步的数据分析和处理。本文将介绍如何使用Python将Excel表格中的数据插入到MySQL数据库中。
导入必要的库
首先,我们…
【数据分析】Pandas内容补充
Pandas内容补充
1.lambda函数
①f lambda x:x ** 2
f lambda( x:x ** 2)
print(f(100)) # 10000②f lambda x:fun1(x)
def fun1(x):return str(x) "hahla"
f lambda x:fun1(x)
print(f(100)) # 100hahla③f (lambda x,y:x y)(32,23)
f (lambda x,y:x y…

数据分析-Pandas数据探查初步圆饼图
数据分析-Pandas数据探查初步圆饼图
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&am…
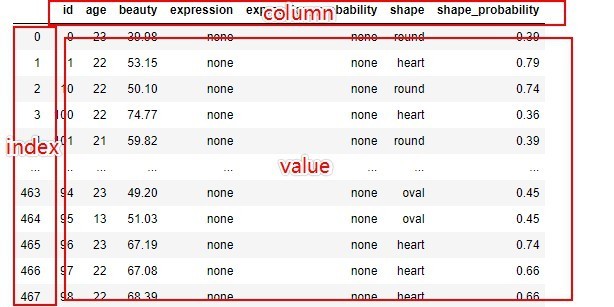
pandas读写excel,csv
1.读excel
1.to_dict() 函数基本语法 DataFrame.to_dict (self, orientdict , into ) --- 官方文档 函数种只需要填写一个参数:orient 即可 ,但对于写入orient的不同,字典的构造方式也不同,官网一共给出了6种,…
【Python】进阶学习:pandas--read_excel()函数的基本使用
【Python】进阶学习:pandas–read_excel()函数的基本使用 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希…
Pandas教程16:DataFrame列标题批量重命名+空df数据判断+列名顺序重排
---------------pandas数据分析集合--------------- Python教程71:学习Pandas中一维数组Series Python教程74:Pandas中DataFrame数据创建方法及缺失值与重复值处理 Pandas数据化分析,DataFrame行列索引数据的选取,增加,…

数据分析-Pandas的Andrews曲线可视化解读
数据分析-Pandas的Andrews曲线可视化解读
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据…
数据分析-Pandas数据分类处理
数据分析-Pandas数据分类处理
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表ÿ…
pytorch 图像数据集管理
目录
1.数据集的管理说明
2.数据集Dataset类说明
3.图像分类常用的类 ImageFolder 1.数据集的管理说明 pytorch使用Dataset来管理训练和测试数据集,前文说过
torchvision.datasets.MNIST 这些 torchvision.datasets里面的数据集都是继承Dataset而来,…
数据分析-Pandas数据分类的转换控制
数据分析-Pandas数据分类的转换控制
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&am…
mac笔记本检查是否安装成功pandas
要检查 pandas 是否成功安装,你可以打开 Python 解释器并尝试导入 pandas 模块。以下是在 Python 中检查 pandas 安装情况的步骤:
打开终端(Terminal)。输入 python 进入 Python 解释器。
python在 Python 解释器中,…
Pandas 2.1中的新改进和新功能
大家好,Pandas 2.1于2023年8月30日发布,跟随本文一起看看这个版本引入了哪些新内容,以及它如何帮助用户改进Pandas的工作负载,包含了一系列改进和一组新的弃用功能。
Pandas 2.1在Pandas 2.0中引入的PyArrow集成基础上进行了大量…
Scipy库提供了多种正态性检验和假设检验方法
Scipy库提供了多种正态性检验和假设检验方法。以下是一些常用的检验方法的列表:
正态性检验方法:
Shapiro-Wilk检验:scipy.stats.shapiroAnderson-Darling检验:scipy.stats.andersonKolmogorov-Smirnov检验:scipy.st…

15np+pandas+matplotlib
numpy
维数
一维:shape(4,)二维:shape(4,5)三维:shape(4,5,6)
创建ndarray–np.array() # 可以是数组[1,2,3] 元组(1,2,3) 迭代对象range(n)
np.array([1,2,3,4,5])列表中元素类型不同,会使用元素类型最大的作为ndarray类型 指定维度ndim 赋值操作 赋值ÿ…
连接两个dataframe
concat
import pandas as pd
df1 pd.DataFrame({‘A’: [1, 2, 3], ‘B’: [4, 5, 6]}) df2 pd.DataFrame({‘A’: [7, 8, 9], ‘B’: [10, 11, 12]})
result pd.concat([df1, df2]) # 在行上连接
merge
import pandas as pd
df1 pd.DataFrame({‘key’: [‘A’, ‘B…
datetime把日/月/年的时间数据格式转化成年/月/日
如果你想要在 Python 中转化时间数据格式,你可以使用 Python 的内置函数 datetime.strptime 和 datetime.strftime。
下面是一个例子:
from datetime import datetime# 将日/月/年格式的字符串转化为日期对象
date_string = "10/01/2023"
date_object = datetime…
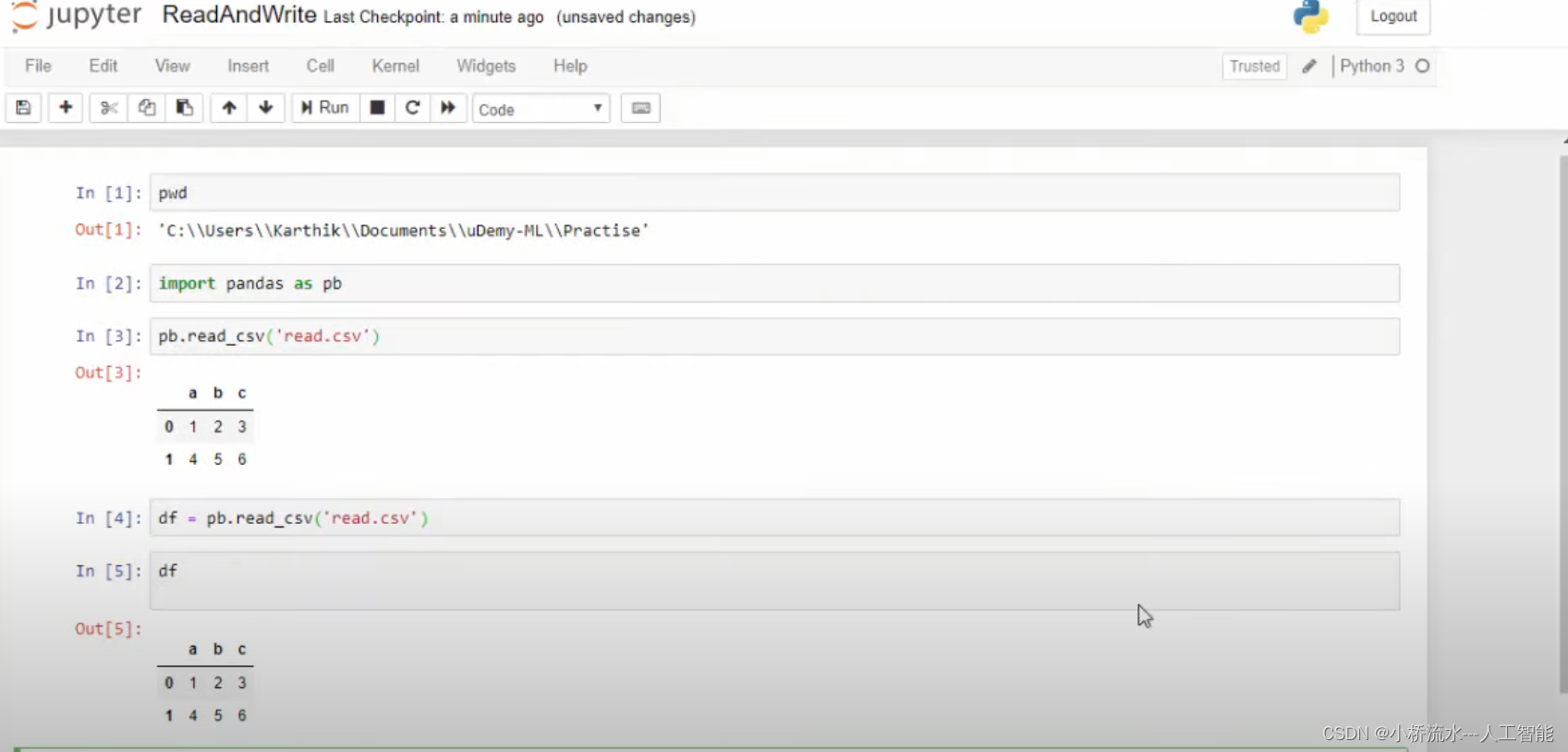
三分钟学习一个python小知识8-----------我的对python中pandas的理解--补充,
文章目录 一、利用pandas读入excel表,包括csv,xlsx等格式二、利用pandas读取没有表头的表格1.引入库 三、利用pandas读取有表头的表格四、利用pandas读取表格中的第一列五、利用pandas导出为excel数据总结 一、利用pandas读入excel表,包括csv,xlsx等格式…

数据分析:数据分析篇
文章目录 第一章 科学计算库Numpy1.1 认识Ndarray1.2 Ndarray的属性1.3 Numpy中的数据类型1.4 Numpy数组1.4.1 Numpy数组的创建1.4.2 Numpy数组的基本索引和切片1.4.3 Numpy布尔索引1.4.4 数组运算和广播机制1.4.5 Numpy数组的赋值和Copy复制1.4.6 Numpy数组的形状变换1.4.7 Nu…
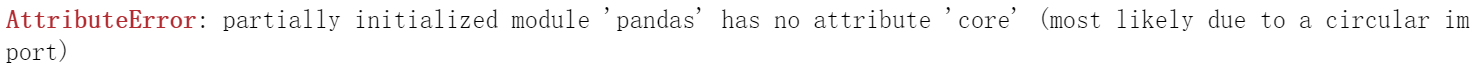
AttributeError: partially initialized module ‘pandas‘ has no attribute ‘core‘
在使用jupyter notebook学习动手学深度学习时,出现以下错误:
%matplotlib inline
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lbatch_size, num_steps 32, 35
train_iter, voca…
Python数据攻略-Pandas在大数据处理中的应用
大数据时代下的数据处理是什么样的?在现代社会,数据无处不在。从社交媒体到医疗记录,从游戏数据到实时交通,我们都处在一个“大数据”的时代。Pandas库在这里起到了关键的作用,特别是当需要处理大小超过内存的数据文件。但是Pandas本身也有其局限性,尤其是在处理超大规模…
Pandas进阶修炼120题-第四期(当Pandas遇上NumPy,81-100题)
目录 往期内容:第一期:Pandas基础(1-20题)第二期:Pandas数据处理(21-50题)第三期:Pandas金融数据处理(51-80题)第四期:当Pandas遇上NumPy…
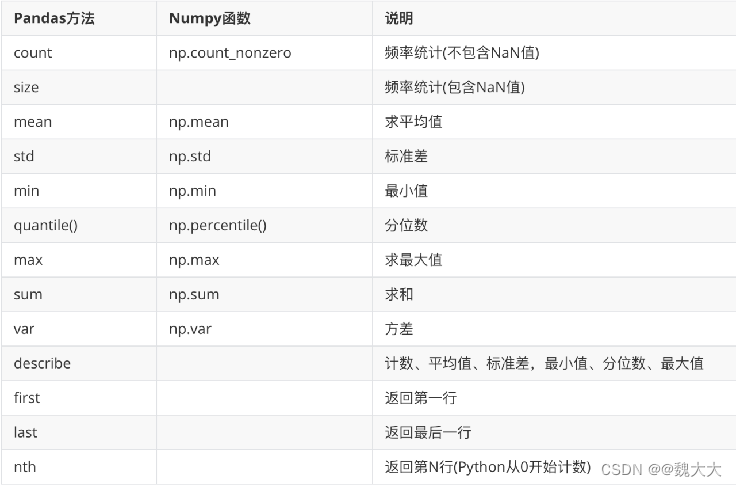
【Pandas】数据分组groupby
本文目标:
应用groupby 进行分组对分组数据进行聚合,转换和过滤应用自定义函数处理分组之后的数据 文章目录 1. 数据聚合1.1 单变量分组聚合1.2 Pandas内置聚合方法1.3 聚合方法使用Numpy的聚合方法自定义方法同时计算多种特征向agg/aggregate传入字典 2. 数据转换…
pandas教程:Handling Missing Data 处理缺失数据
文章目录 Chapter 7 Data Cleaning and Preparation 数据清洗和准备7.1 Handling Missing Data 处理缺失数据1 Filtering Out Missing Data(过滤缺失值)2 Filling In Missing Data(填补缺失值) Chapter 7 Data Cleaning and Prepa…
【Python】进阶学习:pandas--info()用法详解
【Python】进阶学习:pandas–info()用法详解 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订…
【Python数据分析系列】读取Excel文件中的多个sheet表(案例+源码)
这是我的第231篇原创文章。
一、引言 在Python中,您可以使用pandas库来便捷地读取Excel文件中的多个sheet。假如我有一个光谱响应函数.xlsx的excel文件,里面有多个sheet表: 一个excel文件相当于一个数据库,存着一张或多张数据表&…
Python数据处理实战(0)-常用功能以及操作
系列文章: 0、基本常用功能及其操作(本文操持更新)
1,20G文件,分类,放入不同文件,每个单独处理
2,数据的归类并处理
3,txt文件指定的数据处理并可视化作图
4…
数据分析-Pandas分类数据的类别排序和顺序
数据分析-Pandas类别的排序和顺序
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&…

025—pandas 根多列判断不在其他列的数据
思路
是有两个相同结构的数据表,已知第二个表是第一个表的部分数据,需要以其中两列为单位,判断在第一个表中存在,在另外一个表中不存在的数据。
思路: 我们先将 df1 和 df2 的 x、y 列取出,组合为元组形成…

数据分析-Pandas如何画图验证数据随机性
数据分析-Pandas如何画图验证数据随机性
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表…

python读取大型csv文件,降低内存占用,提高程序处理速度
文章目录 简介读取前多少行读取属性列逐块读取整个文件总结参考资料 简介
遇到大型的csv文件时,pandas会把该文件全部加载进内存,从而导致程序运行速度变慢。 本文提供了批量读取csv文件、读取属性列的方法,减轻内存占用情况。
import pand…

数据分析-Pandas最简单的方法画矩阵散点图
数据分析-Pandas直接画矩阵散点图
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&…
Pandas教程15:多个DataFrame数据(保存+追加)为Excel表格数据
---------------pandas数据分析集合--------------- Python教程71:学习Pandas中一维数组Series Python教程74:Pandas中DataFrame数据创建方法及缺失值与重复值处理 Pandas数据化分析,DataFrame行列索引数据的选取,增加,…
Python中Pandas常用函数及案例详解
Pandas是一个强大的Python数据分析工具库,它为Python提供了快速、灵活且表达能力强的数据结构,旨在使“关系”或“标签”数据的操作既简单又直观。Pandas的核心数据结构是DataFrame,它是一个二维标签化数据结构,可以看作是一个表格…
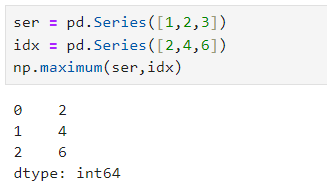
一口气说完Pandas数据结构简介
接下来我将对 pandas 的基本数据结构进行快速、非全面的概述,以帮助您入门。有关数据类型、索引、轴标签和对齐的基本行为适用于所有对象。首先,导入 NumPy 并将 pandas 加载到您的命名空间中:
import numpy as npimport pandas as pd从根本…
pandas的综合练习
事先说明:
由于每次都要导入库和处理中文乱码问题,我都是在最前面先写好,后面的代码就不在写了。要是copy到自己本地的话,就要把下面的代码也copy下。
# 准备工作import pandas as pd
import numpy as np
from matplotlib impor…
Pandas------操作CSV文件
介绍
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文…

人工智能三剑客NumPy、pandas、matplotlib和Jupyter四者之间的关系
NumPy
主要用途:NumPy(Numerical Python的缩写)主要用于处理大型多维数组和矩阵的科学计算。它提供了一个高性能的多维数组对象,以及用于数组操作的工具。与其他三者的联系:NumPy是pandas和matplotlib的基础库之一。许…

038—pandas 重采样线性插补
前言
在数据处理时,由于采集数据量有限,或者采集数据粒度过小,经常需要对数据重采样。在本例中,我们将实现一个类型超分辨率的操作。
思路:
首先将原始数据长度扩展为 3 倍,可以使用 loc[] 方法对索引扩…

数据处理库Pandas数据结构DataFrame
Dataframe是一种二维数据结构,数据以表格形式(与Excel类似)存储,有对应的行和列,如图3-3所示。它的每列可以是不同的值类型(不像 ndarray 只能有一个 dtype)。基本上可以把 DataFrame 看成是共享…
pytorch笔记篇:pandas之数据预处理(更新中)
pytorch笔记篇:pandas之数据预处理 pytorch笔记篇:pandas之数据预处理(更新中)测试例代码相关的算子 pytorch笔记篇:pandas之数据预处理(更新中)
测试例代码
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
# (※1) 为什么test_da…
基于PyTorch深度学习实战入门系列-张量计算
Torch的使用-张量计算 比较函数
函数功能allclose()比较两个元素是否接近eq()逐元素比较是否相等equal()判断两个张量是否具有相同的形状和元素ge()逐元素比较是否大于等于gt()逐元素比较是否大于le()逐元素比较是否小于等于lt()逐元素比较是否大于ne()逐元素比较不等于isnan(…
Pandas合并数据集
第1关:Concat与Append操作
import pandas as pd"""
data.csv和data1.csv是两份与各国幸福指数排名相关的数据,为了便于查看排名详情,所以需要将两份数据横向合并。数据列名含义如下:列名 说明
Country (region…
pandas在循环中多次写入数据到一个excel防止锁定的方法
啥都不说,都是泪,直接上代码:
# 在循环中多次写入数据
for i in range(10):# 创建一个新的DataFramedf pd.DataFrame({A: [i],B: [i * 2]})# 每次写入后保存文件with pd.ExcelWriter(example.xlsx, engineopenpyxl, modea, if_sheet_existsoverlay) as…
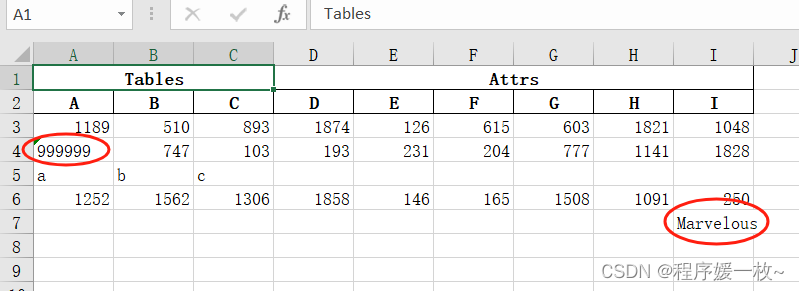
Pandas操作MultiIndex合并行列的Excel,写入读取以及写入多余行及Index列处理,插入行,修改某个单元格的值,多字段排序
Pandas操作MultiIndex合并行列的excel,写入读取以及写入多余行及Index列处理,多字段排序尽量保持原来的顺序 1. 效果图及问题2. 源码参考 今天是谁写Pandas的 复合索引MultiIndex,写的糊糊涂涂,晕晕乎乎。 是我呀…
记录下&#…
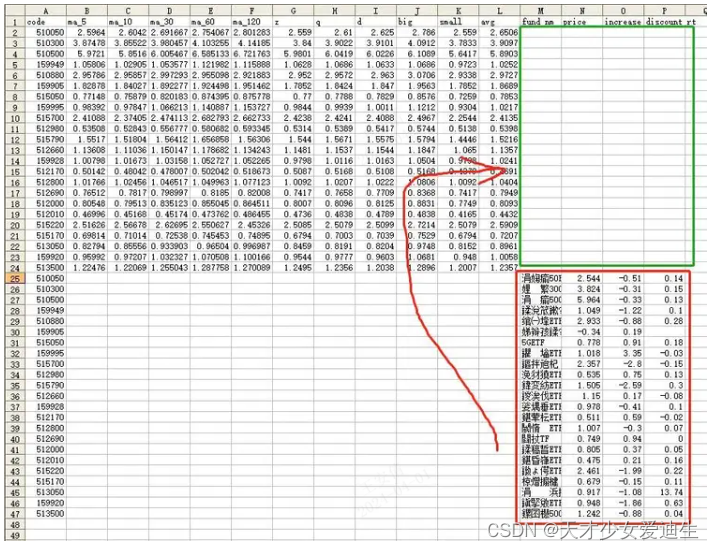
解决pandas的concat表格错位问题。表格拼接错误。
两个表格横向拼接但没拼到一块儿 如图: 图片来源:https://m.163.com/dy/article/HM6T6DRQ0516W3V7.html
拼接错位了。 解决方法:重置左边表格索引。
import pandas as pd
df1df1.reset_index(dropTrue)
df_newpd.concat([df1,df2],axiis1)…
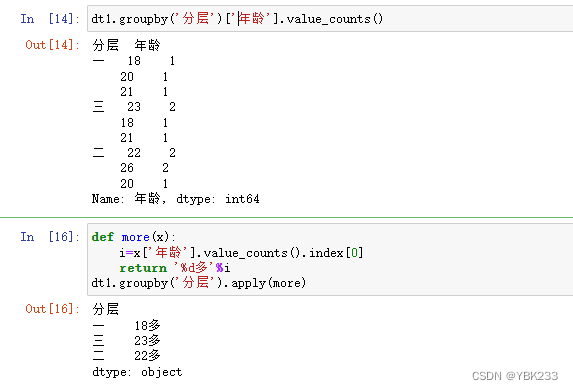
Python基础之pandas:文件读取与数据处理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、文件读取1.以pd.read_csv()为例:2.数据查看 二、数据离散化、排序1.pd.cut()离散化,以按范围加标签为例2. pd.qcut()实现离散化3.排序4.…
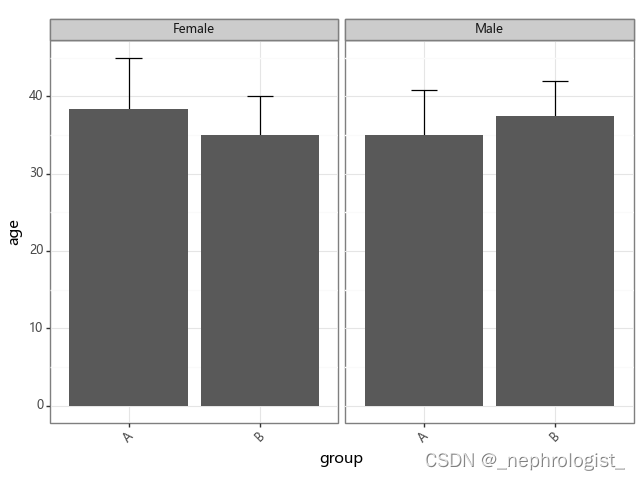
pandas.DataFrame.to_excel:在同一个sheet内追加数据
参考了这篇文章的方法 pandas to_excel:写入数据,在同一个sheet中追加数据,写入到多个sheet里,基本逻辑是: 通过数据框获取到该Excel表的行数 df_rows,然后将需要存储的数据,限制开始写入的行数,…
pandas教程:Data Transformation 数据变换、删除和替换
文章目录 7.2 Data Transformation(数据变换)1 删除重复值2 Transforming Data Using a Function or Mapping(用函数和映射来转换数据)3 Replacing Values(替换值)4 Renaming Axis Indexes(重命…

Pandas和Pyecharts带你揭秘最近热播好剧的主题和题材趋势
在电视剧领域,热播好剧的主题和题材趋势一直备受关注。为了揭秘这个秘密,我们将使用Python中的Pandas和Pyecharts库抓取爱奇艺热播剧的数据,并通过数据分析和可视化展示,带你一起探索最近热播好剧的主题和题材趋势。 在我们开始之…
pandas教程:Essential Functionality 索引 过滤 映射 排序
文章目录 5.2 Essential Functionality(主要功能)1 Reindexing(重新索引)2 Dropping Entries from an Axis (按轴删除记录)3 Indexing, Selection, and Filtering(索引,选择,过滤)Selection with loc and i…
clang插件对llvm源码插桩,分析函数调用日志(1)
tick_plot__compile.ipynb 时长边界_时上链异数: 长短函数调用链列表
0. 用matplotlib找系统中字体文件大于1MB的 中文字体通常很大,这样过滤出的 通常有中文字体 结果中 看名字 ‘AR PL UMing CN’ 果然是中文字体 from matplotlib.font_manager import fontManager
import …
怎么查找女性人数的不同年龄段的人数
怎么查找女性人数的不同年龄段的人数
需求分析:
1.读取表格中的提起数据,然后获得当前日期,并通过表内的出生日期计算当前年龄,表格内出生日期:20231029
2.然后根据年龄段来求人数代码: def teacher_age_…

分享Python的十大库,这你一定得知道!
文章目录 前言关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Python学习书籍四、Python工具包项目源码合集①Python工具包②Python实战案例③Python小游戏源码五、面试资料六、Python兼职渠道 前言
Python为我们提供了非常完善的基础库&#…
pandas 笔记:shift
用于将数据系列或数据框中的数据按指定的位置移动。这对于某些时间序列分析特别有用,例如计算数据的变化量或滞后值
1 对Series/DataFrame数据进行移动
1.0 原始数据
import pandas as pd
import numpy as np
df1pd.DataFrame(np.arange(12).reshape(3,4),column…
pandas 笔记: interpolate
一个用于填充 NaN 值的工具
1 基本用法 DataFrame.interpolate(methodlinear, *, axis0, limitNone, inplaceFalse, limit_directionNone, limit_areaNone, downcast_NoDefault.no_default, **kwargs)
2 主要参数
method 多种插值技术 linear: 默认值,使用线性插…
主题模型LDA教程:LDA主题数选取:困惑度preplexing
文章目录 LDA主题数困惑度 LDA主题数
LDA作为一种无监督学习方法,类似于k-means聚类算法,需要给定超参数主题数K,但如何评价主题数的优劣并无定论,一般采取人为干预、主题困惑度preplexing和主题一致性得分coherence score&#…
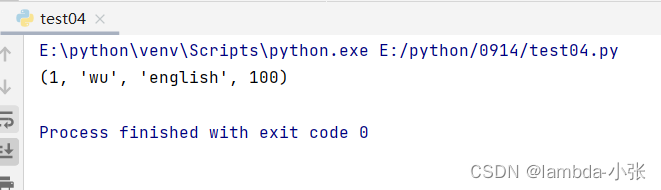
python连接mysql数据库的练习
一、导入pandas内置的sqlite3模块,连接的信息:ip地址是本机, 端口号port 是3306, 用户user是root, 密码password是123456, 数据库database是lambda-xiaozhang
import pymysql# 打开数据库连接,参数1:主机名或IP;参数…
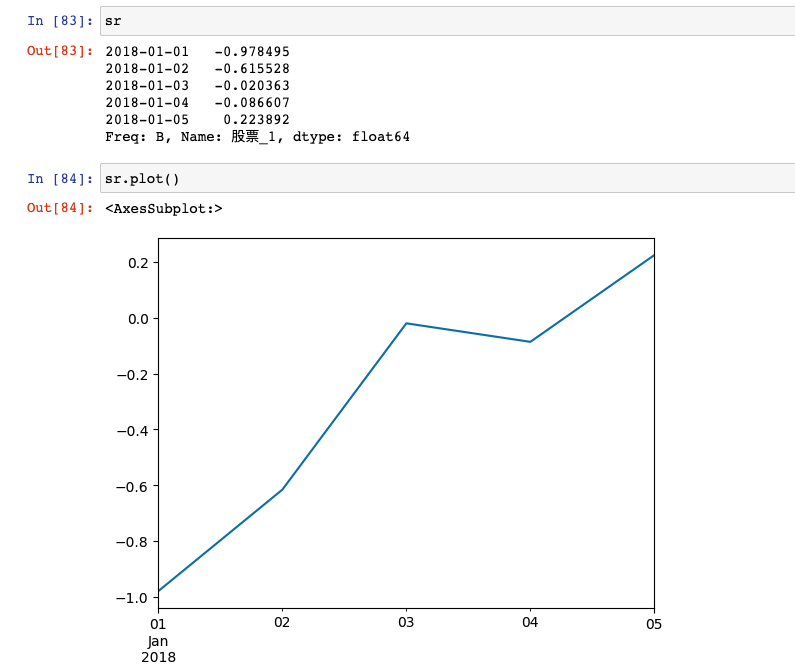
【Python】Pandas(学习笔记)
一、Pandas概述
1、Pandas介绍
2008年WesMcKinney开发出的库,专门用于数据挖掘的开源python库
以Numpy为基础,借力Numpy模块在计算方面性能高的优势
基于matplotib,能够简便的画图
独特的数据结构
import pandas as pd2、Pandas优势
便…
dask读取hdfs文件时报错connect hdfs error
问题详情:
/arrow/cpp/src/arrow/filesystem/hdfs.cc:51: Failed to disconnect hdfs client: IOError: HDFS hdfsFS::Disconnect failed, errno: 9 (Bad file descriptor)
Traceback (most recent call last):
File "/home/tdops/fucheng.pan/ray-code/read.…
Pandas处理缺省数据
背景:
SQL查询数据为空或者null的字段,如果查询字段为或者NULL需要设置为NULL 解决方案:
只处理指定字段
在 Pandas 中处理缺失数据(如 SQL 查询结果中的空字符串或 NULL 值)可以通过 fillna() 方法来实现。您可以将…
Pandas进行数据分析
dataframe添加列:df2.drop(新增加的列:,axis1,inplaceTrue) 在Pandas中,DataFrame的列是Series对象,而Series对象具有一系列字符串处理方法。要对Series中的字符串进行操作,需要使用.str属性来访问这些字符串方法。删除列中的横线…
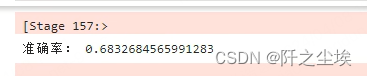
pandas,polars,pyspark的df对象常见用法对比
案例背景
最近上班需要处理的都是百万,千万级的数据,pandas的性能已经不够看了(虽然它在处理数据上是真的很好用),公司都是用的polar和pyspark,我最近也学习了一些,然后写篇文章对比一下他们的…
数据分析-Pandas分类数据的操作方法
数据分析-Pandas分类数据的操作方法
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&am…
学习Dive into Deep learning:2.2 数据预处理,pandas
为了能用深度学习来解决现实世界的问题,我们经常从预处理原始数据开始, 而不是从那些准备好的张量格式数据开始。 在Python中常用的数据分析工具中,我们通常使用pandas软件包。 像庞大的Python生态系统中的许多其他扩展包一样,pan…
【小沐学Python】Python实现Web图表功能(Lux)
文章目录 1、简介2、安装3、测试3.1 入门示例3.2 入门示例2 结语 1、简介
https://github.com/lux-org/lux 用于智能可视化发现的 Python API Lux 是一个 Python 库,通过自动化可视化和数据分析过程来促进快速简便的数据探索。通过简单地在 Jupyter 笔记本中打印出…
DataFrame.empty 与 DataFrame is None 的区别是?
请注意,empty 与 None 是不同的概念,这个要注意。不信我们试一下:
import pandas as pddf pd.DataFrame()df ! df ! Nonedf.empty df is not None # 已经被赋值,为空但不为Nonea is None参考回答:
DataFrame.empty…
pandas字符串操作:大小写转换、连接、分割、包含等
大小写转换
import pandas as pddata {text: [Hello World, Python is Great, Data Science]
}
df pd.DataFrame(data)
df.dropna(threshTrue)
c df["text"].str.capitalize()
# 0 Hello world
# 1 Python is great
# 2 Data science
# Name: te…
Python 数据分析入门教程:Numpy、Pandas、Matplotlib和Scikit-Learn详解
文章目录 Python数据分析入门教程Numpy库Pandas库Matplotlib绘图Scikit-Learn机器学习 NumPy数组与运算NumPy数组对象数组创建函数数组运算数组索引数组操作总结 总结python精品专栏推荐python基础知识(0基础入门)python爬虫知识 Python数据分析入门教程…
Java的Stream和Python的Pandas的对比
Java 中的 Stream 流和 Python 中的 Pandas 库都提供了处理数据的功能,但它们有一些关键的区别。以下是它们之间的一些对比:
Stream 和 Pandas 都提供了数据处理和转换的功能: Java Stream: Stream 是 Java 8 引入的一个概念,用于…
打印 pyspark.sql.dataframe.DataFrame 有哪些列
在 PySpark 中,要打印 pyspark.sql.dataframe.DataFrame 的列,可以使用 columns 属性。以下是一个示例代码:
from pyspark.sql import SparkSession# 创建 SparkSession
spark SparkSession.builder.getOrCreate()# 假设您的 DataFrame 名称…
Pandas数据分析开发实战博文集锦
本文为最近年来使用Pandas进行数据分析的实践笔记集锦,为了便于博主与爱好者查找相关内容,以及学习、应用过程,进行了初步简单梳理。内容包括:数据分析处理、可视化分析、数据库相关(ClickHouse、MongoDB、CSV、MySQL、…
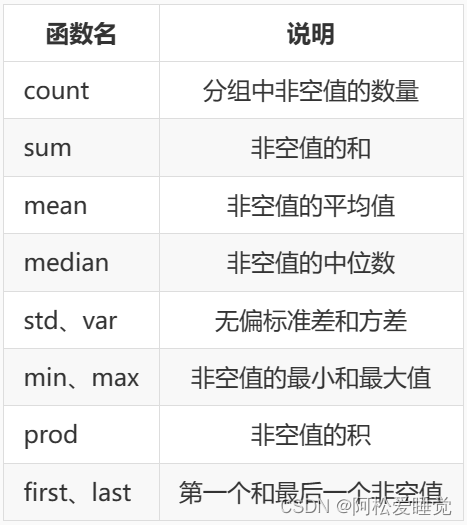
Pandas分组聚合_Python数据分析与可视化
Pandas分组聚合 分组单列和多列分组Series 系列分组通过数据类型或者字典分组获取单个分组对分组进行迭代 聚合应用单个聚合函数应用多个聚合函数自定义函数传入 agg() 中对不同的列使用不同的聚合函数 分组聚合的流程主要有三步:
分割步骤将 DataFrame 按照指定的…

Pandas与数据库交互详解
Pandas 是一个强大的数据分析库,可以与各种数据库进行交互,从而可以方便地从数据库中读取数据、分析数据,并将结果写回数据库中。以下是使用 Pandas 与数据库交互的一般步骤:
一 、数据库交互 安装必要的库:首先&…
Spring 路径与占位符
SpringMVC支持ant风格的路径
?:表示任意的单个字符
*:表示任意的0个或多个字符
\**:表示任意的一层或多层目录 注意:在使用**时,只能使用/**/xxx的方式 1.测试 ? <a th:href"{/succe…
Python的Pandas库(二)进阶使用
Python开发实用教程
DataFrame的运算
DataFrame重载了运算符,支持许多的运算
算术运算
运算方法运算说明df.add(other)对应元素的加,如果是标量,就每个元素加上标量df.radd(other)等效于otherdfdf.sub(other)对应元素相减,如果…

Pandas时间序列、时间戳对象、类型转换、时间序列提取、筛选、重采样、窗口滑动
时间序列数据是指在时间间隔不变的情况下收集的时间点数据,可以用来分析事物的长期发展趋势,并对未来进行预测。
date_range()方法及参数 pandas.date_range(startNone, endNone, periodsNone, freqNone, tzNone, normalizeFalse, nameNone, inclusive‘…
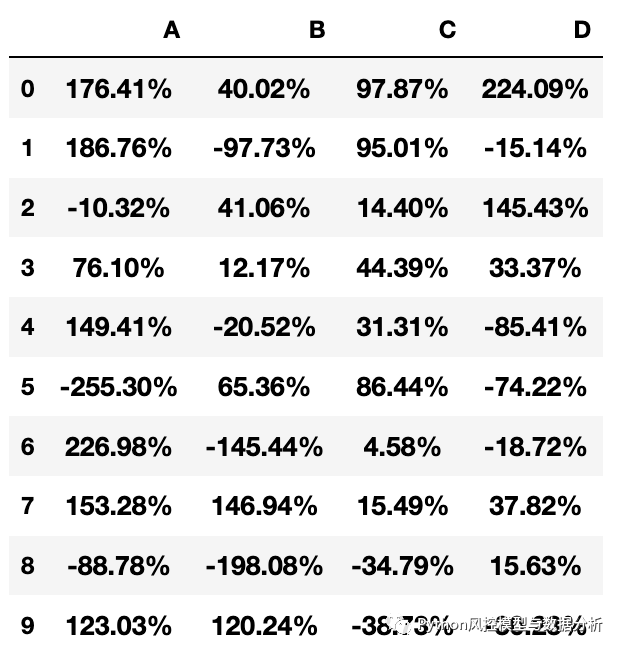
Pandas表格样式,你有table-style吗
目录
数据生成
1、高亮设置
2、百分比显示设置
3、空值显示设置
4、色阶设置
5、数据条设置
6、字体颜色、大小、对齐、加粗设置
划重点 Pandas提供了style功能,可以直接实现excel里的高亮、色阶、数据条、单元格格式设置、字体设置等等功能,简单…
[AI]Python中的Restful
在当今数字化的时代,网络应用的开发变得越来越普遍,而RESTful(Representational State Transfer)作为一种设计风格和通信协议,为构建灵活、可扩展的网络应用提供了一种优雅的方式。本文将深入介绍RESTful的概念、原则以…
数据分析实战 - 2 订单销售数据分析(pandas 进阶)
题目来源:和鲸社区的题目推荐:
刷题源链接(用于直接fork运行 https://www.heywhale.com/mw/project/6527b5560259478972ea87ed
刷题准备
请依次运行这部分的代码(下方4个代码块),完成刷题前的数据准备
…

Pandas数据集的合并与连接merge()方法_Python数据分析与可视化
数据集的合并与连接 merge()解析merge()的主要参数 merge()解析
merge()可根据一个或者多个键将不同的DataFrame连接在一起,类似于SQL数据库中的合并操作。 数据连接的类型
一对一的连接:
df1 pd.DataFrame({employee: [Bob, Jake, Lisa, Sue], grou…
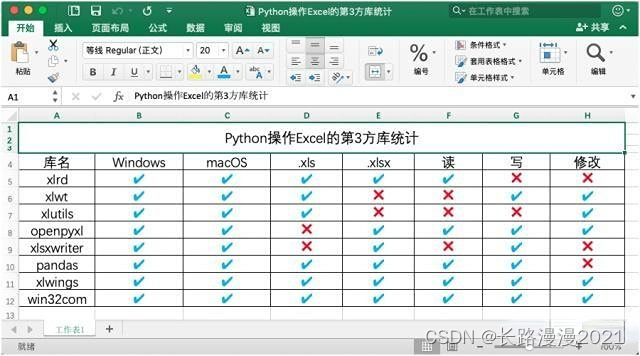
Python数据分析(四)-- 操作Excel文件
1 操作Excel文件-多种实现方式 在实际生产中,经常会用到excel来处理数据,虽然excel有强大的公式,但是很多工作也只能半自动化,配合Python使用可以自动化部分日常工作,大大提升工作效率。
openpyxl:只允许读…
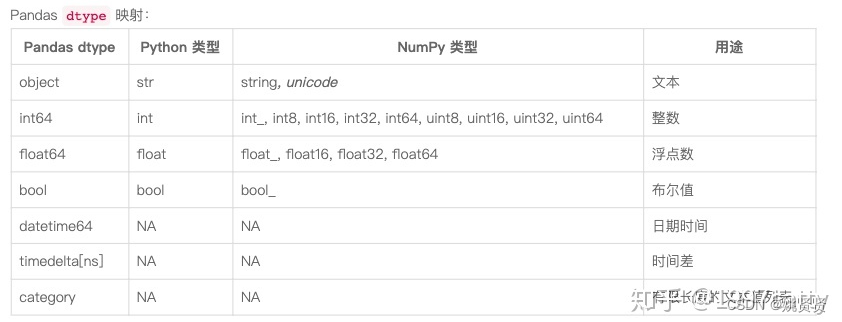
数据预处理pandas pd.json_normalize占用内存过大优化
问题描述
从ES下载数据,数据格式为json,然后由pandas进行解析,json中的嵌套字段会进行展开作为列名(由于维度初期无法预测,所以根据数据有啥列就使用啥列,这是最方便的点),变成表格,方面了后续…
pandas DataFrame转成字典
目录 dict形式list形式records形式split形式 dict形式
原数据 DateFrame.to_dict()
pd.read_excel(r"D:\Users\admin\Desktop\授信额度使用.xlsx").to_dict()list形式
DateFrame.to_dict(‘list’)
pd.read_excel(r"D:\Users\admin\Desktop\授信额度使用.x…
Python数据攻略-Pandas与机器学习数据准备
在机器学习项目中,大部分时间都花在了数据准备上。你可能听说过“数据是机器学习的燃料”的说法,这是因为高质量的数据是构建出色模型的关键。
在这篇文章中将使用Pandas库来进行数据准备。为了让内容更贴近实际将使用《三国志》游戏中的角色数据作为样本。 文章目录 数据编…

初始Pandas -> 数据缺失值处理
🐼
3.1初识pandas(显示excel前五条数据) 3.2创建Series对象 3.2.1手动设置索引 3.2.4Series的索引 3.3创建一个DataFrame对象 3.4导入外部数据 p59 1.使用read_csv 2.导入html时,需要网页一定具有table标签 3.5数据抽取 3.6数据的增加、修…
python合并excel
0 思路 注意:此代码1,2是将多个excel合并到一个excel,3是根据某个键进行合并,针对键的合并需要使用merge函数,实现excel的vlookup功能 主要使用pandas操作excel,然后写入excel表 1. pandas读取excel后数据类…
Python Pandas处理csv文件常用操作代码
常识
使用pandas.read_csv从csv文件中读取数据,对于csv中缺失的空值,读进dataframe会自动补为numpy.nan,且数据类型为float 操作
读取csv文件,存储为dataframe数据类型
df pandas.read_csv(csv_path)查看csv文件的dataframe的…
python pandas dataframe常用数据处理总结
最近一直在做数据处理相关的工作,有几点经常遇到的情况总结如下:
数据中存在为空数据如何处理
处理方式1:丢弃数据行
# 实现方式1
data data.dropna(subset[id]) # 若id列中某行数值为空,丢弃整行数据
# 实现方式2
data df[df…
Pandas-DataFtame的索引与切片(第3讲)
Pandas-DataFtame的索引与切片(第3讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ�…
货物数据处理pandas版
1求和
from openpyxl import load_workbook
import pandas as pddef print_hi(name):# Use a breakpoint in the code line below to debug your script.print(fHi, {name}) # Press CtrlF8 to toggle the breakpoint.# Press the green button in the gutter to run the scr…
【Python】—— pandas 数据分析
pandas 数据分析 相关知识了解1. 数据清理2. 探索性数据分析(EDA)3. 数据过滤和选择4. 数据分组和聚合5. 数据合并和连接6. 时间序列分析7. 统计分析 第1关:了解数据集特征第2关:DataFrame 的 CRUD第3关:利用 pandas 实…

python实现批量替换目录下多个后缀为docx文档内容
批量替换目录下多个后缀为docx文档内容
摘要: 本文将介绍如何使用Python实现批量替换目录下多个后缀为docx文档内容。通过使用Python的os和glob模块,我们可以轻松地遍历目录下的所有文件,并对每个文件进行操作。此外,我们还将使用…
使用pandas绘图,并保存,支持中文
使用pandas绘图,并保存,支持中文 支持中文标题绘图创建DataFrame绘制图形添加其他绘图细节保存图形显示图形 支持中文标题
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import matplotlib.font_manager as fm…
Pandas数据预处理python 数据分析之4——pandas 预处理在线闯关_头歌实践教学平台
Pandas数据预处理python 数据分析之4——pandas 预处理 第1关 数据读取与合并第2关 数据清洗第3关 数据转换 第1关 数据读取与合并
任务描述 本关任务:加载 csv 数据集,实现 DataFrame 合并。 编程要求 根据提示,在右侧编辑器补充代码&#…
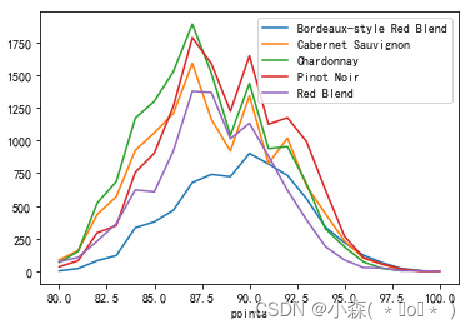
Pandas数据可视化
pandas库是Python数据分析的核心库 它不仅可以加载和转换数据,还可以做更多的事情:它还可以可视化 pandas绘图API简单易用,是pandas流行的重要原因之一
Pandas 单变量可视化
单变量可视化, 包括条形图、折线图、直方图、饼图等 …
pandas数据结构Series, DataFrame的索引方式总结
pandas数据结构Series, DataFrame的索引方式总结
1, 转换为Numpy。
pandas的目的在于方便进行列操作,如果想遍历循环,就利用values值转换为numpy。
import pandas as pd
df pd.DataFrame({a:[10,20,30],b:[c,30,40]})
print(df.values)
print(df[a].…
Python访问ElasticSearch
ElasticSearch是广受欢迎的NoSQL数据库,其分布式架构提供了极佳的数据空间的水平扩展能力,同时保障了数据的可靠性;反向索引技术使得数据检索和查询速度非常快。更多功能参见官网介绍 https://www.elastic.co/cn/elasticsearch/ 下面简单罗列…
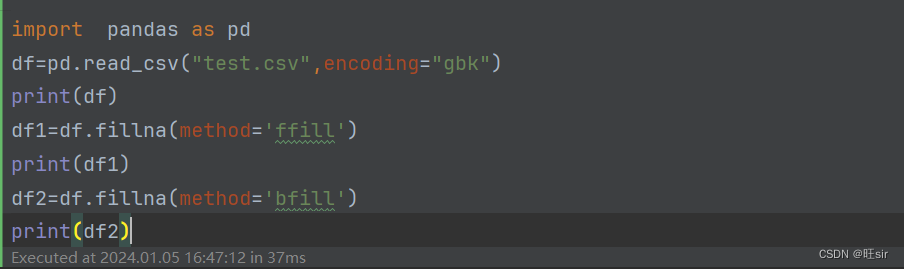
Numpy和Pandas知识点总结
1.python常见的开源库介绍
1.1numpy
一个运行速度非常快的数学库,主要用于数组计算
1.2pandas
一个强大的“分析结构化数据”的工具集,底层依赖numpy
用于数据挖掘和数据分析,同时也提供数据清洗功能
pandas主要有两种数据结构…
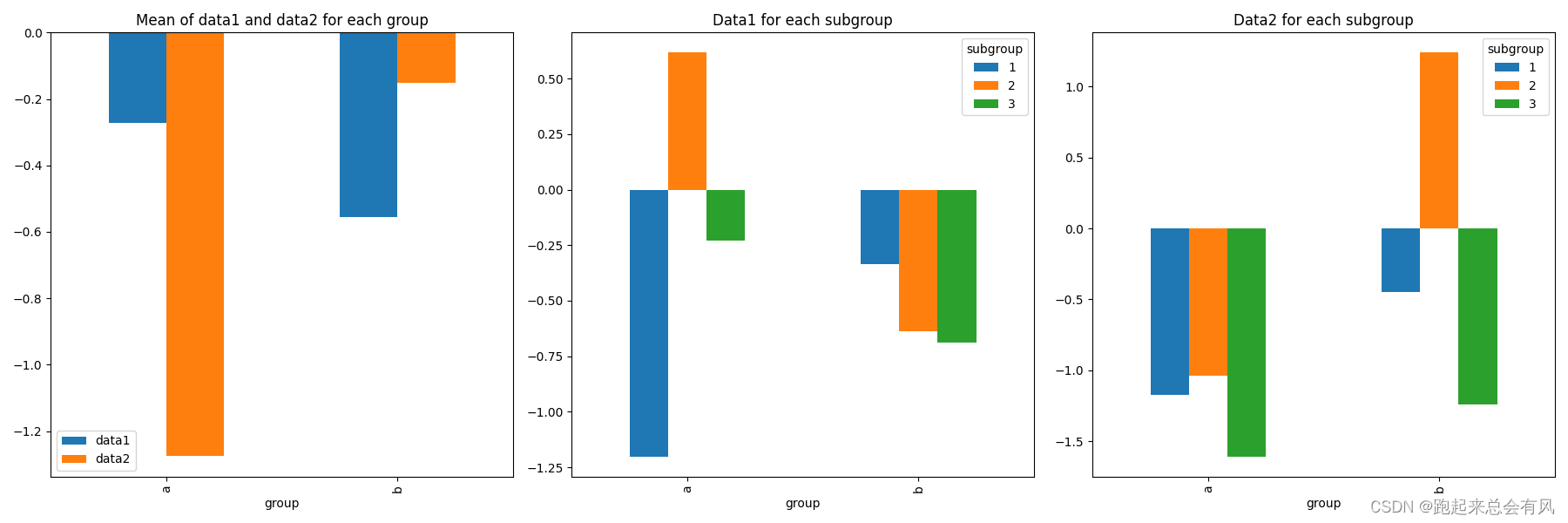
深入Pandas(二):高级数据处理技巧
文章目录 系列文章目录引言时间序列分析可视化示例 高级数据分析技术分组与聚合操作时间序列分析 高级数据操作数据合并与重塑示例:数据合并merge示例:数据合并concat示例:数据重塑 - 透视表 高级索引技巧 结论 系列文章目录
Python数据分析…
Pandas实战100例 | 案例 25: 计算相关系数
案例 25: 计算相关系数
知识点讲解
在统计分析中,了解变量之间的关系是非常重要的。相关系数是衡量变量之间线性相关程度的一种方法。Pandas 提供了 corr 方法来计算列之间的相关系数。
相关系数: 相关系数的值范围在 -1 到 1 之间。接近 1 表示正相关࿰…
Pandas实战100例 | 案例 10: 应用函数 - 使用 `apply`
案例 10: 应用函数 - 使用 apply
知识点讲解
Pandas 的 apply 函数是一个非常强大的工具,允许你对 DataFrame 中的行或列应用一个函数。这对于复杂的数据转换和计算非常有用。你可以使用 apply 来执行任意的函数,这些函数可以是自定义的,也…
Pandas实战100例 | 案例 19: 基本数学运算
案例 19: 基本数学运算
知识点讲解
Pandas 允许在 DataFrame 上直接执行基本的数学运算。这包括加法、减法、乘法和除法等。这些运算可以逐元素地应用于列或整个 DataFrame。
加法: 将两列或两个数值相加。减法: 从一列中减去另一列或一个数值。乘法: 将两列或一列和一个数值…
Pandas实战100例 | 案例 4: 数据选择和索引 - 选择特定的列和行
案例 4: 数据选择和索引 - 选择特定的列和行
知识点讲解
在 Pandas 中,选择数据是一个非常常见的操作。你可以选择特定的列或行,或者基于某些条件筛选数据。
示例代码
选择特定的列
# 选择单列
selected_column df[ColumnName]# 选择多列
selected…
29 Python的pandas模块
概述 在上一节,我们介绍了Python的numpy模块,包括:多维数组、数组索引、数组操作、数学函数、线性代数、随机数生成等内容。在这一节,我们将介绍Python的pandas模块。pandas模块是Python编程语言中用于数据处理和分析的强大模块&a…
pandas教程:Date Ranges, Frequencies, and Shifting 日期范围,频度,和位移
文章目录 11.3 Date Ranges, Frequencies, and Shifting(日期范围,频度,和位移)1 Generating Date Ranges(生成日期范围)2 Frequencies and Date Offsets(频度和日期偏移)Week of mo…
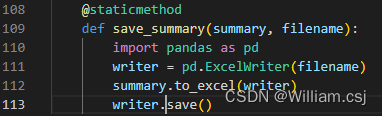
报错解决——AttributeError: ‘OpenpyxlWriter‘ object has no attribute ‘save‘
完整报错
Traceback (most recent call last):File "track_half.py", line 249, in <module>main(opt,File "track_half.py", line 153, in mainEvaluator.save_summary(summary, os.path.join(result_root, summary_{}.xlsx.format(exp_name)))Fil…

Pandas实战100例-专栏介绍
Pandas,Python数据科学的心脏,是探索和分析数据世界的强大工具。想象一下,用几行代码就能洞察庞大数据集的秘密,无论是金融市场趋势还是社交媒体动态。
通过Pandas,你可以轻松地整理、清洗、转换数据,将杂…
Pandas实战100例 | 案例 27: 数据合并 - 使用 `merge`
案例 27: 数据合并 - 使用 merge
知识点讲解
在数据处理中,经常需要将来自不同来源的数据集合并在一起。Pandas 提供了 merge 函数,它类似于 SQL 中的 JOIN 操作,可以根据一个或多个键来合并两个 DataFrame。
内连接 (inner): 只合并两个 …
Pandas实战100例 | 案例 46: 列重新排序
案例 46: 列重新排序
知识点讲解
在某些情况下,你可能需要改变 DataFrame 中列的顺序。Pandas 允许你通过指定列名的列表来重新排列列的顺序。
列重新排序: 通过指定列名的新顺序列表,可以对 DataFrame 的列进行重新排序。
示例代码
# 准备数据和示…
Pandas.DataFrame.groupby() 数据分组(数据透视、分类汇总) 详解 含代码 含测试数据集 随Pandas版本持续更新
关于Pandas版本: 本文基于 pandas2.1.2 编写。
关于本文内容更新: 随着pandas的stable版本更迭,本文持续更新,不断完善补充。
Pandas稳定版更新及变动内容整合专题: Pandas稳定版更新及变动迭持续更新。 Pandas API参…
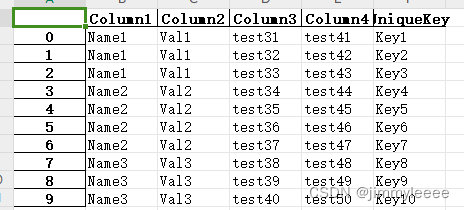
用pandas实现用前一行的excel的值填充后一行
今天接到一份数据需要分析,数据在一个excel文件里,内容大概形式如下: 后面空的格子里的值就是默认是前面的非空的值,由于数据分析的需要需要对重复的数据进行去重,去重就需要把控的cell的值补上,然后根据几…
Pandas-pd.to_numeric函数知识点总结
前言 本文是该专栏的第38篇,后面会持续分享python数据分析的干货知识,记得关注。
我们在处理数据分析项目的时候,通常会需要处理各种类型的数据,比如说“时间日期,字符串,布尔值”等等类型。有的时候,恰巧需要用Pandas将这些数据转换为数值类型,以便于后期进行统计或计…
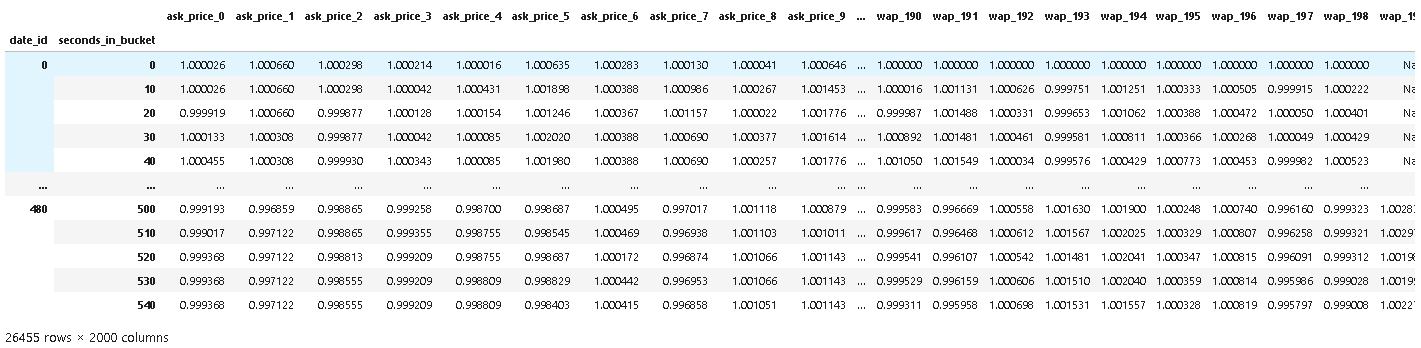
【pandas】数据透视表【pivot_table】
pivot_table
pandas的pivot_table函数是一个非常有用的工具,用于创建一个数据透视表,这是一种用于数据总结和分析的表格形式。
以下是pivot_table的基本语法:
pandas.pivot_table(data, valuesNone, indexNone, columnsNone, aggfuncmean,…

Python教程:DataFrame列数据类型的转换
Pandas提供了多种数据类型转换方法。可以使用astype()函数来转换数据类型。例如,可以将字符串类型的列转换为整数类型的列:
# Author : 小红牛
# 微信公众号:wdPython
import pandas as pd# 创建包含字符串类型列的DataFrame
df pd.DataFra…
pandas教程:Introduction to scikit-learn scikit-learn简介
文章目录 13.4 Introduction to scikit-learn(scikit-learn简介) 13.4 Introduction to scikit-learn(scikit-learn简介)
scikit-learn是一个被广泛使用的python机器学习工具包。里面包含了很多监督式学习和非监督式学习的模型&a…
[Python进阶] 数据处理:Pandas入门
10.4 Pandas
介绍: Pandas 是 Python 语言的一个扩展程序库,用于数据分析。Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。Pandas 名字衍生自术语 “panel data”(面板数据)和…
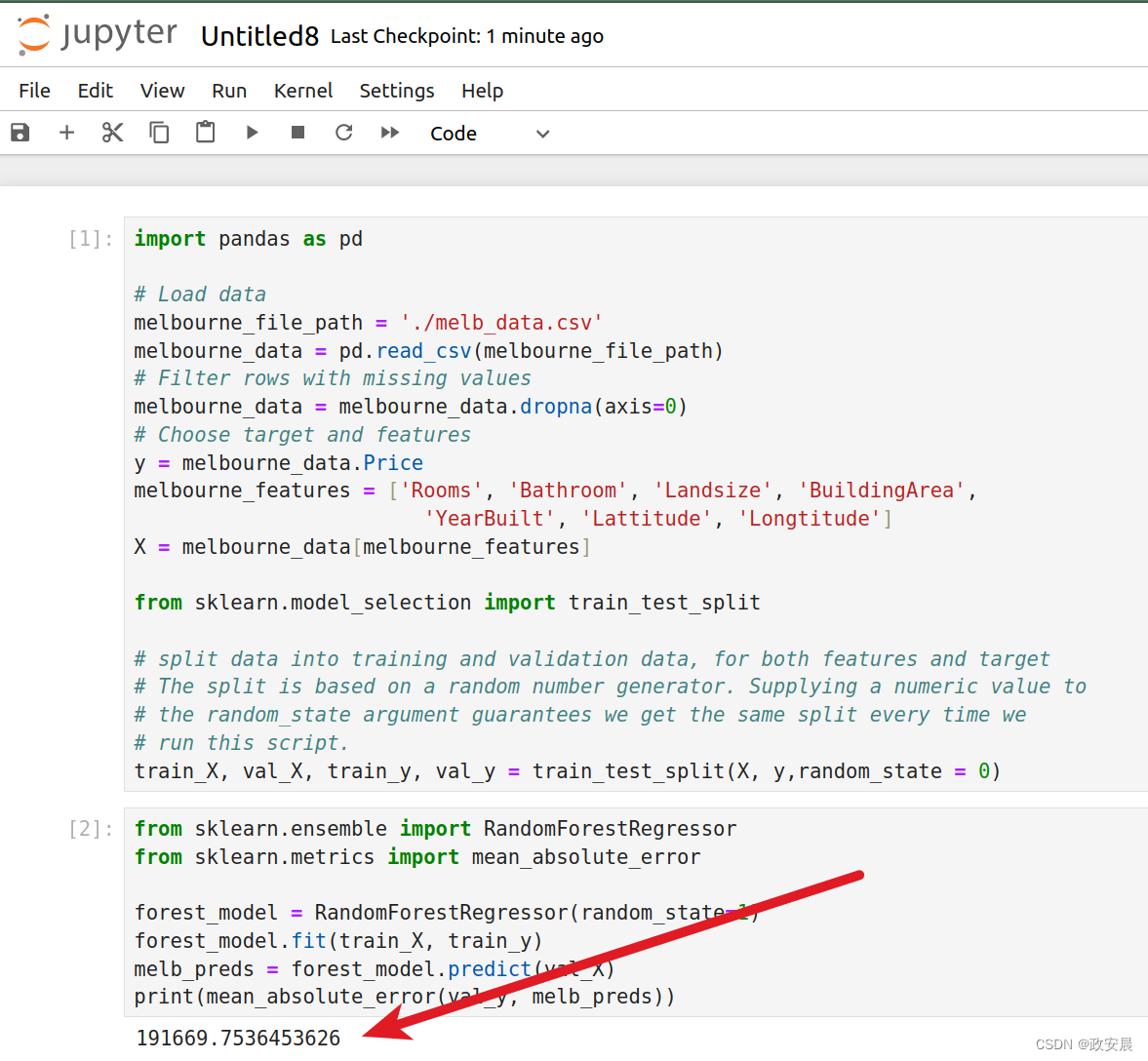
政安晨:机器学习快速入门(四){pandas与scikit-learn} {随机森林}
咱们将在这篇文章中使用更复杂的机器学习算法。 随机森林
基本定义
随机森林(Random Forest)是一种机器学习算法,属于集成学习(ensemble learning)的一种。它是通过构建多个决策树(即森林)来进行预测和分类的。
随机森林的主要特点是采用了…
数据分析Pandas专栏---第一章<数据清洗>
前言:
当我们使用爬虫从网上收集到大量的数据时,经常会面临一个重要任务:对这些数据进行清洗和整理,以便进一步分析和利用。在Python中,pandas是一个功能强大且广泛使用的数据处理库,它提供了各种灵活而高效的工具&am…
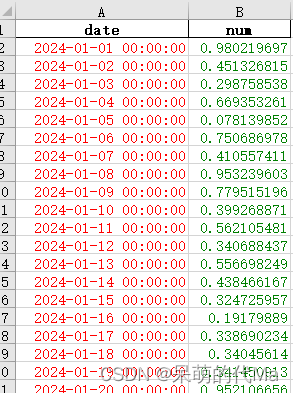
pandas保存style到excel文件中
更多pandas style用法请参考:https://pandas.liuzaoqi.com/doc/chapter8/style.html
示例程序
import numpy as np
import pandas as pd# 示例数据
dataframe pd.DataFrame({"date": pd.date_range("2024-01-01", "2024-02-01"),&…
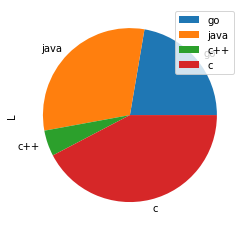
Pandas教程(非常详细)(第五部分)
接着Pandas教程(非常详细)(第四部分),继续讲述。
二十五、Pandas sample随机抽样
随机抽样,是统计学中常用的一种方法,它可以帮助我们从大量的数据中快速地构建出一组数据分析模型。在 Pandas…
如何在ModelScope社区魔搭下载所需的模型
本篇文章介绍如何在ModelScope社区下载所需的模型。
若您需要在ModelScope平台上有感兴趣的模型并希望能下载至本地,则ModelScope提供了多种下载模型的方式。
使用Library下载模型
若该模型已集成至ModelScope的Library中,则您只需要几行代码即可加载…
pythonPandas六:时间序列数据处理
Pandas对时间序列数据提供了专门的支持,包括日期索引、时间频率转换、滚动窗口统计等功能。 可以使用pd.date_range()生成日期范围,并将其作为索引创建时间序列数据。还可以使用DataFrame.resample()、DataFrame.rolling()等方法进行时间序列数据的重采…
numpy和pandas的遍历
梳理: numpy的遍历: np.ndenumerate(l1)
np.nditer pandas的遍历: pd.iterrows() 遍历行
pd.itertuples(indexFalse)遍历行 data.iteritems()遍历列
data.columns遍历列 pandas的apply、applymap()、map map() 是一个Series的函数,…
pyDAL一个python的ORM(终) pyDAL的一些性能优化
一、大批量插入数据
对于 大量数据插入时,虽然pyDAL也手册中有个方法:bulk_insert(),但是手册也说了,虽然方法上是一次可以多条数据,如果后端数据库是关系型数据库,他转换为SQL时它是一条一条的插入的&…
《Python数据分析技术栈》第06章使用 Pandas 准备数据 01 Pandas概览(Pandas at a glance)
01 Pandas概览(Pandas at a glance)
《Python数据分析技术栈》第06章使用 Pandas 准备数据 01 Pandas概览(Pandas at a glance)
Pandas概述
Wes McKinney developed the Pandas library in 2008. The name (Pandas) comes from…

Pandas ------ 向 Excel 文件中写入含有合并表头的数据
Pandas ------ 向 Excel 文件中写入含有合并表头的数据 推荐阅读引言正文 推荐阅读
Pandas ------ 向 Excel 文件中写入含有 multi-index 和 Multi-column 表头的数据
引言
这里给大家介绍一下如何向 Excel 中写入带有合并表头的数据。
正文
import pandas as pddf1 pd.D…
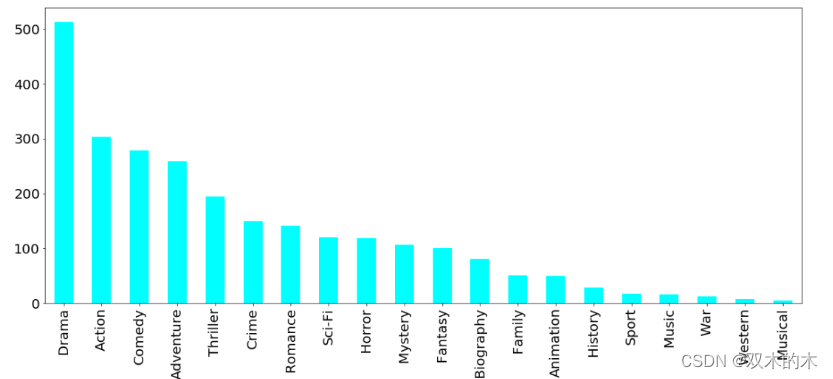
运小筹 | Python编程-系统性的学会 Pandas,看这一篇就够了!(含案例分析)
本文来源公众号“运小筹”,仅用于学术分享,侵权删,干货满满。篇幅略长,建议收藏!
原文链接:Python编程 | 系统性的学会 Pandas,看这一篇就够了! (qq.com)
1、Pandas数据结构 2008年…

Python Pandas简介及基础教程+实战示例。
文章目录 前言一、Pandas简介二、Python Pandas的使用关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Python学习书籍四、Python工具包项目源码合集①Python工具包②Python实战案例③Python小游戏源码五、面试资料六、Python兼职渠道 前言
Pan…

【Python】重磅!这本30w人都在看的Python数据分析畅销书更新了!
Python 语言极具吸引力。自从 1991 年诞生以来,Python 如今已经成为最受欢迎的解释型编程语言。 【文末送书】今天推荐一本Python领域优质数据分析书籍,这本30w人都在看的书,值得入手。 目录 作译者简介主要变动导读视频购书链接文末送书 pan…
pandas使用read_csv时报错解决
问题描述:
在使用read_csv时报错:
UnicodeDecodeError: utf-8 codec cant decode byte 0xc9 in position 9451: invalid continuation byte
或者:
UnicodeDecodeError: gb2312 codec cant decode byte 0x88 in position 68296: illegal m…
使用Python和Pandas将Excel文件中的每个Sheet保存为独立文件
import pandas as pd
import os
from pathlib import Path# 读取原始Excel文件
excel_file pd.ExcelFile(rC:\Users\wangkejun\Desktop\id.xlsx)# 获取Excel文件名(不带扩展名)
file_name Path(rC:\Users\wangkejun\Desktop\id.xlsx).stem# 创建保存文…
pandas教程:Techniques for Method Chaining 方法链接的技巧
文章目录 12.3 Techniques for Method Chaining(方法链接的技巧)1 The pipe Method(pipe方法) 12.3 Techniques for Method Chaining(方法链接的技巧)
对序列进行转换的时候,我们会发现会创建很…
利用Python和pandas库进行股票技术分析:移动平均线和MACD指标
利用Python和pandas库进行股票技术分析:移动平均线和MACD指标 介绍准备工作数据准备计算移动平均线计算MACD指标结果展示完整代码演示 介绍
在股票市场中,技术分析是一种常用的方法,它通过对股票价格和交易量等历史数据的分析,来…
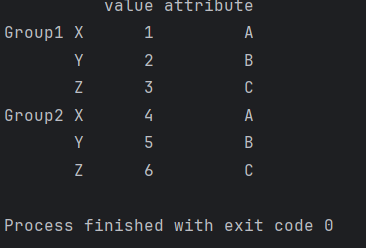
深入学习Pandas:数据连接、合并、加入、添加、重构函数的全面指南【第72篇—python:数据连接】
深入学习Pandas:数据连接、合并、加入、添加、重构函数的全面指南
Pandas是Python中最强大且广泛使用的数据处理库之一,提供了丰富的函数和工具,以便更轻松地处理和分析数据。在本文中,我们将深入探讨Pandas中一系列数据连接、合…
连续读取文件夹中若干CSV文件最后一行数据,并求出最大最小平均标准差
数据格式为: 行表头 1 2 3 … n
import osimport numpy as np
import pandas as pd# 设置存储 CSV 文件的文件夹路径
# 这里修改为你自己的文件夹路径
# folder_path your file path
folder_path ./data/testing result# 初始化一个空列表来存储所有的数据帧
dfs…

Pandas教程12:常用的pd.set_option方法,显示所有行和列+不换行显示等等...
---------------pandas数据分析集合--------------- Python教程71:学习Pandas中一维数组Series Python教程74:Pandas中DataFrame数据创建方法及缺失值与重复值处理 Pandas数据化分析,DataFrame行列索引数据的选取,增加,…
pyhanlp安装和使用教程
文章目录 pyhanlp介绍 pyhanlp介绍
HanLP 是一个由中国开发者何晗(hankcs)于 2014 年开发的自然语言处理库,自发布之后,HanLP 不断更新迭代,进行了许多新功能和性能的优化,Github 上 Star 数量已超过 3w,其在主流自然…
数据分析Pandas专栏---第四章<Pandas几个处理元素的函数>
前言:
在处理series和Dataframe对象中的元素的时候,经常会用到一些逻辑运算函数; 那么这些逻辑运算怎么用?有哪些? 我认为这六个都比较重要!!!
正文:
1.apply
apply函数可以用于Series或DataFrame对象,用于将自定义函数应用于每个元素或每一列/行。
对于Ser…
Python Pandas DataFrame:筛选和删除含特定值的行与列
Python Pandas DataFrame:挑选和删除含特定值的行与列 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程 👈 希望得…

Python爬虫进阶:爬取在线电视剧信息与高级检索
简介: 本文将向你展示如何使用Python创建一个能够爬取在线电视剧信息的爬虫,并介绍如何实现更高级的检索功能。我们将使用requests和BeautifulSoup库来爬取数据,并使用pandas库来处理和存储检索结果。 目录
一、爬取在线电视剧信息 …
【Python编程+数据清洗+Pandas库+数据分析】
数据分析的第一步往往是数据清洗,这个过程关键在于理解、整理和清洗原始数据,为进一步分析做好准备。Python 语言通过Pandas库提供了一系列高效的数据清洗工具。接下来,该文章将通过一个简单的案例演示如何利用 Pandas 进行数据清洗ÿ…
Seaborn学习网站:解锁数据可视化的无限可能!
介绍:Seaborn是一个基于Python的高级数据可视化库,它建立在Matplotlib之上,并与Pandas数据结构紧密集成,为用户提供了一种更加方便的方式来创建具有吸引力和信息丰富的统计图形。 Seaborn的特点包括: 高级APIÿ…
数据分析Pandas专栏---第十章<Pandas数据筛选和过滤(2)>
前言:
继续上一篇数据分析Pandas专栏---第九章<Pandas数据筛选和过滤(1)>-CSDN博客 正文: 复杂条件筛选和过滤技巧
A. 使用逻辑运算符进行复杂条件筛选
1. 如何使用逻辑运算符(例如与、或、非等)进行复杂条件筛选
在Pandas中&…

【玩转pandas系列】pandas数据结构—DataFrame
文章目录 前言一、DataFrame创建1.1 字典创建1.2 NumPy二维数组创建 二、DataFrame切片2.1 行切片2.2 列切片2.3 行列切片 三、DataFrame运算3.1 DataFrame和标量的运算3.2 DataFrame之间的运算3.3 Series和DataFrame之间的运算 四、DataFrame多层次索引4.1 多层次索引构造1.隐…
Python进阶学习:axis=0和axis=1的区别和用法
Python进阶学习:axis0和axis1的区别和用法 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和…
Python进阶学习:Pandas--将一种的数据类型转换为另一种类型(astype())
Python进阶学习:Pandas–将一种的数据类型转换为另一种类型(astype()) 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程&…
数据分析Pandas专栏---第八章<Pandas时间值的处理>
前言:
时间是数据处理中不可或缺的因素,几乎所有数据都会伴随着时间的演变而产生。在数据分析和建模过程中,正确处理时间是至关重要的。在这样的背景下,Pandas提供了强大的工具和函数,使我们能够轻松处理时间序列数据。
无论是金…

数据分析-Pandas数据的探查蜂窝图
数据分析-Pandas数据的探查蜂窝图
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&…

Pandas DataFrame 基本操作实例100个
Pandas
是一个基于NumPy的数据分析模块,最初由AQR Capital Management于2008年4月开发,并于2009年底开源。Pandas的名称来源于“Panel Data”(面板数据)和“Python数据分析”(data analysis)。这个库现在由…
数据分析Pandas专栏---第十一章<Pandas数据聚合与分组(1)>
前言:
数据聚合和分组操作是数据处理过程中不可或缺的一部分。它们允许我们根据特定的条件对数据进行分组,并对每个组进行聚合计算。这对于统计分析、汇总数据以及生成报告和可视化非常有用。无论是市场营销数据分析、销售业绩评估还是金融数据建模,数据…

探索网络世界:IP代理与爬虫技术的全景解析
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …

什么是IP代理和爬虫技术?
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …
【Python】进阶学习:pandas--rename()用法详解
【Python】进阶学习:pandas-- rename()用法详解 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的…

数据分析-Pandas数据探查初步柱状图
数据分析-Pandas数据探查初步柱状图
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&am…
Codeforces Round 170 (Div. 1)A. Learning Languages并查集
如果两个人会的语言中有共同语言那么他们之间就可以交流,并且如果a和b可以交流,b和c可以交流,那么a和c也可以交流,具有传递性,就容易联想到并查集,我们将人和语言看成元素,一个人会几种语言的话…
精通Python第15篇—数据之流:Pyecharts桑基图的多维视角与绘制艺术
文章目录 数据之流:Pyecharts桑基图的多维视角与绘制艺术桑基图简介安装 Pyecharts简单桑基图的绘制自定义桑基图的炫酷效果高级样式定制 多组数据桑基图的展示动态桑基图的绘制结合真实数据的桑基图案例导出和分享进阶应用:桑基图与其他图表的组合总结 …
数据分析-Pandas数据y轴双坐标设置
数据分析-Pandas数据y轴双坐标设置
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&…
数据分析中需要用的的python知识(包括Numpy、Pandas、Matplotlib)
由于python的基础知识比较琐碎,这一块我打算以知识导图的形式呈现 软件:幕布 参考内容:菜菜菊花酱数据分析 python基础知识:https://www.mubu.com/doc/5uLBgn5LNTI numpy:https://www.mubu.com/doc/SgpdGGHMvI Pandas&…

数据分析-Pandas数据分组箱线图
数据分析-Pandas数据分组箱线图
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&#x…
数据分析-Pandas数据画箱线图
数据分析-Pandas数据画箱线图
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表ÿ…
数据分析Pandas专栏---第十三章<Pandas训练题(初)>
前言: 写这篇是为了弄一个富有挑战性的Pandas练习题库,涵盖了许多常见和实用的数据处理问题。通过解决这些练习,能够深入了解Pandas提供的关键功能,掌握有效处理数据的技巧和方法。 练习题库涵盖了选择特定列并创建新DataFrame、对DataFrame进…

数据分析-Pandas画分布密度图
数据分析-Pandas画分布密度图
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表ÿ…
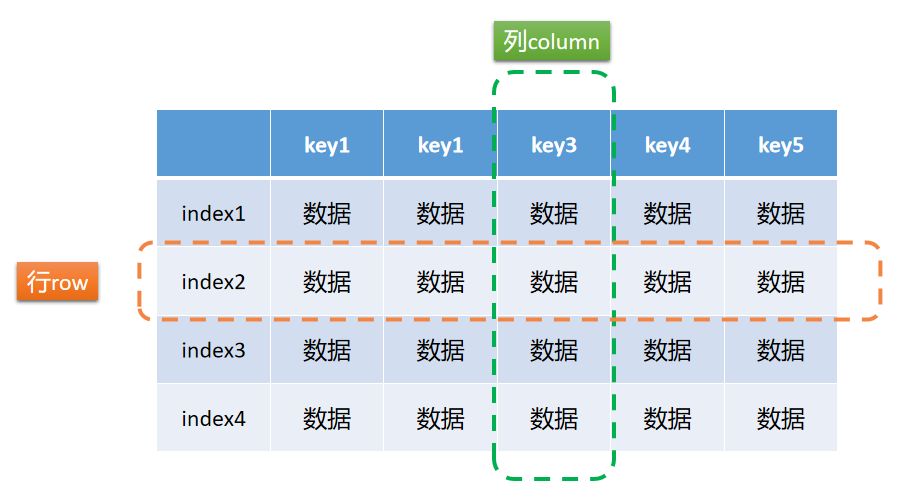
三.pandas基础
目录
一:认识pandas
1.1 pandas的优势
1.2 下载安装
二:Series数据结构(一维)
2.1 创建Series
创建series对象(一维)
ndarray创建Series对象
“显式索引”的方法定义索引标签
dict创建Series对象(通过字典创建)
标量创建Series对象
2.2 访问S…

第五篇【传奇开心果系列】Python的自动化办公库技术点案例示例:深度解读Pandas在教育数据和研究数据处理领域的应用
传奇开心果博文系列 系列博文目录Python的自动化办公库技术点案例示例系列 博文目录果果老师推荐🔥🔥🔥🌹🌹🌹果子哥个人微信:lxm1093220242前言一、Pandas 在教育和学术研究中的常见应用介绍二…
Pandas教程:DataFrame删除重复的行数据
---------------pandas数据分析集合--------------- Python教程71:学习Pandas中一维数组Series Python教程74:Pandas中DataFrame数据创建方法及缺失值与重复值处理 Pandas数据化分析,DataFrame行列索引数据的选取,增加,…
Pandas实战100例 | 案例 36: 时间序列重采样
案例 36: 时间序列重采样
知识点讲解
时间序列重采样是处理时间序列数据的一种常用方法。它允许你按照不同的时间频率对数据进行重新采样和聚合。在 Pandas 中,这可以通过 resample 方法轻松完成。
时间序列重采样: 使用 resample 方法可以根据不同的时间频率&am…
pandas plot函数:数据可视化的快捷通道
一般来说,我们先用pandas分析数据,然后用matplotlib之类的可视化库来显示分析结果。而pandas库中有一个强大的工具--plot函数,可以使数据可视化变得简单而高效。 1. plot 函数简介 plot函数是pandas中用于数据可视化的一个重要工具࿰…
2.Python数据分析—数据分析入门知识图谱索引(知识体系上篇)
2.Python数据分析—数据分析入门知识图谱&索引 一个人简介二数据分析的重要性和用途Python在数据分析中的角色 三Python数据分析基础Python简介和安装指南Python基本语法和数据结构Python中的数学运算 四数据分析工具和库概览NumPy:高效的多维数组操作Pandas&am…
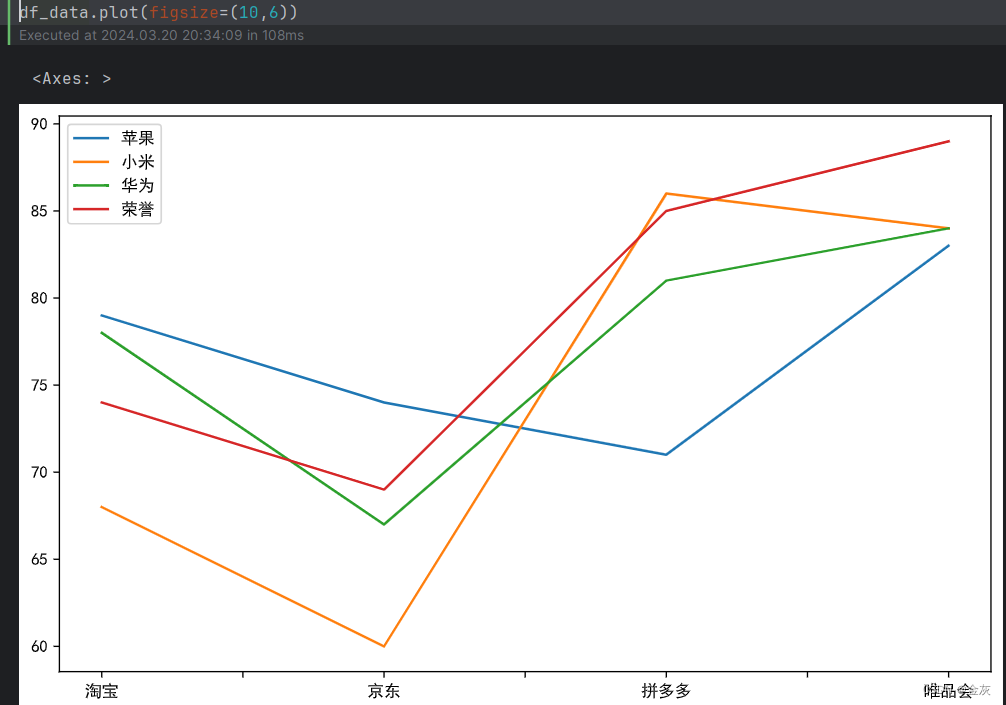
九.pandas绘图基础
目录
九.pandas绘图基础
1-柱状图
--参数stackedTrue堆积
--参数figsize(宽,高)
--自定义横坐标
--设置字体&显示负号
2.箱型图
3. 折线图 九.pandas绘图基础 Pandas的DataFrame和Series,在matplotlib基础上封装了一个简易的绘图函数, 使得我们在数据处…
【Pandas】(3)索引操作方法
Pandas 中的索引主要有两种形式:轴标签(行标签)和列名。
索引类型
Pandas 提供了多种索引类型,包括: Index:最常见的索引类型,用于索引 DataFrame 的行。Int64Index:整数索引,存储整数。Float64Index:浮点数索引,存储浮点数。DateTimeIndex:用于存储日期时间。Pe…
pandas无法读取/保存xls格式的excel的解决办法
文章目录 一、读取报错* 问题1* 解决办法1二、保存报错* 问题1* 解决办法1* 问题2* 解决办法2一、读取报错
* 问题1
使用 pandas 读取 .xls 后缀的 excel 报错:
Traceback (most recent call last):File "D:\PycharmProjects\tools\my_project\start.py", line 1…
数据分析-Pandas类别的排序和顺序
数据分析-Pandas类别的排序和顺序
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表&…
01-Pandas的方法介绍
以下所有代码都是从完整代码中取的某一行,作为使用示例。 import pandas as pd 使用merge 组合两个表 pd.merge(person, address, on personId, how left)[[firstName, lastName, city, state]]其中person,address为表名,两个表均为datafram…
数据分析-Pandas分类数据的比较如何避坑
数据分析-Pandas分类数据的比较如何避坑
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据表…
【Pandas】(4)基本操作
选择数据
获取列
单列获取
要获取 DataFrame 的单个列,你可以使用列名以两种不同的方式: 使用点(.)操作符,这种方式更像是访问对象的属性。使用方括号([])和列名,这种方式更像是从字典中获取值。假设我们有以下 DataFrame:
import pandas as pddata = {Name: [Ali…
Pandas教程17:关于json数据转化成DataFrame数据,消除警告提示的方法。
---------------pandas数据分析集合--------------- Python教程71:学习Pandas中一维数组Series Python教程74:Pandas中DataFrame数据创建方法及缺失值与重复值处理 Pandas数据化分析,DataFrame行列索引数据的选取,增加,…

027—pandas 不同分类每天指定取值的比例
前言
本例我们将进行分组计算,分组后得到一个堆叠数据,并对堆叠数据解除堆叠,最后再按要求格式化为百分数样式。 此类操作会经常发生在业务数据透视场景下,一般都会有 Excel 来操作完成,今天我们使用 Python 的 panda…
解决pandas.errors.ParserError....Expected 2 fields in line 2系列问题【python报错】
问题描述
报错代码是 df pd.read_csv(./datasets/assist0910/train1.csv, headerNone)详细报错信息当时忘记截屏了,关键报错信息如下:
pandas.errors.ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 305解决方法
首…
【数据分析】Pandas内容补充(Lambda、applymap、merge...)
Pandas内容补充
1.lambda函数
①f lambda x:x ** 2
f lambda( x:x ** 2)
print(f(100)) # 10000②f lambda x:fun1(x)
def fun1(x):return str(x) "hahla"
f lambda x:fun1(x)
print(f(100)) # 100hahla③f (lambda x,y:x y)(32,23)
f (lambda x,y:x y…
Python 数据分析模块pandas 如何创建DataFrame
以下用两种方式分别创建DataFrame。
import pandas as pd#原始数据存储在列表中
names [Alice,Deric,Amanda,Petter]
ages [34,24,33,35]
incomes [50000,65000,46000,69000]# 使用字典创建 DataFrame
data {names:names,ages:ages,incomes:incomes}
df1 pd.DataFrame(da…
Pandas DataFrame 写入 Excel 的三种场景及方法
一、引言
本文主要介绍如何将 pandas 的 DataFrame 数据写入 Excel 文件中,涉及三个不同的应用场景:
单个工作表写入:将单个 DataFrame 写入 Excel 表中;多个工作表写入:将多个 DataFrame 写入到同一个 Excel 表中的…
Data.olllo:轻松解锁邮政编码数据!
引言: 在数据处理的路上,解析邮政编码可能会让您头疼不已。然而,有了Data.olllo的“超级抽取”功能,这一切都变得轻而易举!
功能介绍: Data.olllo的“超级抽取”功能为您提供了快速、简便的解决方案&#…
Pandas库常用方法、函数集合
Pandas是Python数据分析处理的核心第三方库,它使用二维数组形式,类似Excel表格,并封装了很多实用的函数方法,让你可以轻松地对数据集进行各种操作。
这里列举下Pandas中常用的函数和方法,方便大家查询使用。
读取 写…
Pandas操作MultiIndex合并行列的Excel,写入读取以及写入多余行及Index列处理,插入行,修改某个单元格的值
Pandas操作MultiIndex合并行列的excel,写入读取以及写入多余行及Index列处理 1. 效果图及问题2. 源码参考 今天是谁写Pandas的 复合索引MultiIndex,写的糊糊涂涂,晕晕乎乎。 是我呀…
记录下,现在终于灵台清明了。 明天在记录下直…
flask_restful规范返回值
使用方法 导入 flask_restful.marshal_with 装饰器 定义一个字典变量来指定需要返回的标准化字段,以及该字段的数据类型 在请求方法中,返回自定义对象的时候, flask_restful 会自动的读 取对象模型上的所有属性。 组装成一个符合标准化参…
数据挖掘与分析学习笔记
一、Numpy
NumPy(Numerical Python)是一种开源的Python库,专注于数值计算和处理多维数组。它是Python数据科学和机器学习生态系统的基础工具包之一,因为它高效地实现了向量化计算,并提供了对大型多维数组和矩阵的支持…
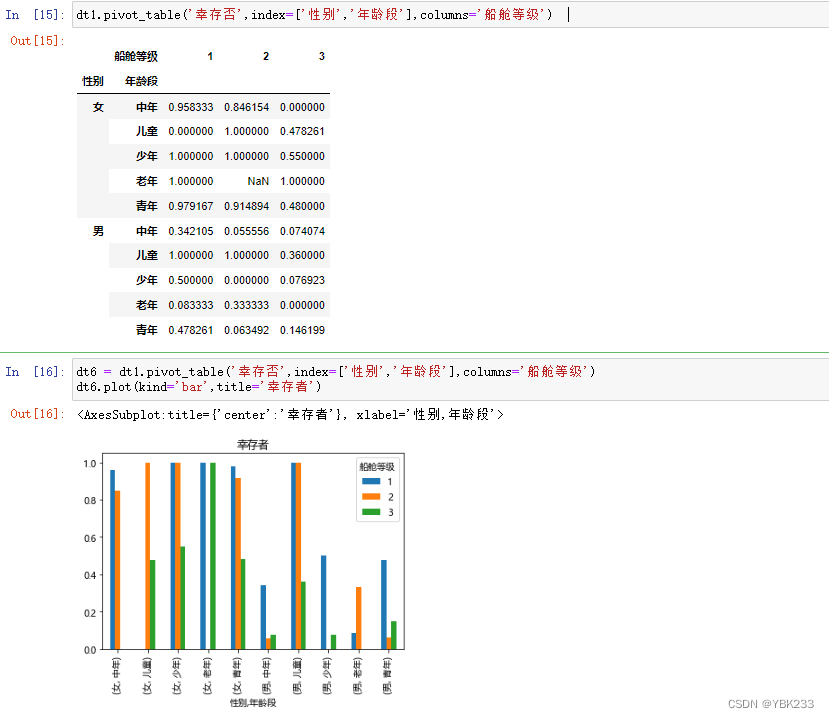
Python基础之pandas:字符串操作与透视表
文章目录 一、字符串操作备注:如果想要全部行都能输出,可输入如下代码 1、字符检索2、字符转换3、字符类型判断4、字符调整5、字符对齐与填充6、字符检索7、字符切割8、字符整理 二、透视表1、pd.pivot_table2、多级透视表 一、字符串操作
备注…
Spark重温笔记(五):SparkSQL进阶操作——迭代计算,开窗函数,结合多种数据源,UDF自定义函数
Spark学习笔记 前言:今天是温习 Spark 的第 5 天啦!主要梳理了 SparkSQL 的进阶操作,包括spark结合hive做离线数仓,以及结合mysql,dataframe,以及最为核心的迭代计算逻辑-udf函数等,以及演示了几…

数据分析和机器学习库Pandas的使用
Pandas 库是一个免费、开源的第三方 Python 库,是 Python 数据分析和机器学习的工具之一。Pandas 提供了两种数据结构,分别是 Series(一维数组结构)与 DataFrame(二维数组结构),极大地增强的了 …
解决pandas使用to_sql,传入sqlalchemy的create_engine后无法保存数据的问题
解决方法
调用连接后需要手动提交,将原有程序:
from sqlalchemy import create_engineengine create_engine("xxxxx")
_db_conn engine.connect()
dataframe.to_sql("数据表", if_exists"append", con_db_conn, index…
webp格式的图像变身成.png格式
~ $ cd /storage/emulated/0/代码设计/壁纸
.../代码设计/壁纸 $ find . -maxdepth 1 -type f -iname "*.webp" -exec convert {} {}.png \;
convert: unable to read image data ./7f8807782f9c3943b85509973412a959.webp error/constitute.c/ReadImage/991.
conve…
pandas中mode() 函数的应用
mode() 函数用于计算 DataFrame 或 Series 中数值型数据的众数。众数是指数据集中出现频率最高的值。它可以对整个 DataFrame 或 Series 进行计算众数,也可以沿着指定的轴(行或列)进行计算众数。
下面是一个示例,说明如何使用 mo…
【2024-完整版】python爬虫 批量查询自己所有CSDN文章的质量分:附整个实现流程
【2024】批量查询CSDN文章质量分 写在最前面一、分析获取步骤二、获取文章列表1. 前期准备2. 获取文章的接口3. 接口测试(更新重点) 三、查询质量分1. 前期准备2. 获取文章的接口3. 接口测试 四、python代码实现1. 分步实现2. 批量获取文章信息3. 从exce…

CentOSPython使用openpyxl、pandas读取excel报错
一、openpyxl报错
由于本人在centos7下使用python的openpyxl报错,所以决定使用强大的pandas。 pandas是一个快速、强大、灵活且易于使用的开源数据操作和分析工具,建立在Python语言之上。
pandas是一个广泛使用的数据分析库,它提供了高效的数据结构和数据分析工具。pandas…
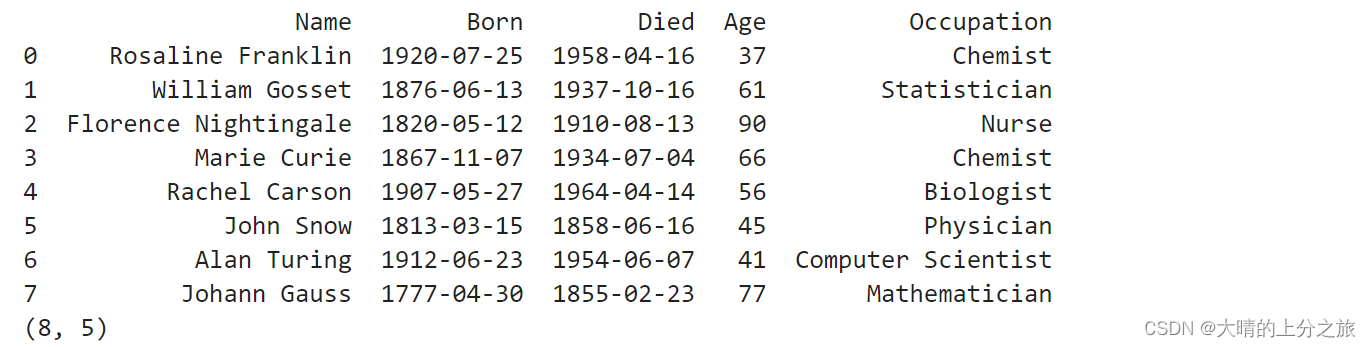
python 08Pandas
1.基础概念 2.基本操作
(1)加载数据集
import pandas as pd #引入pandas包
打开csv文件
df pd.read_csv(./data/gapminder.tsv,sep\t) #\t制表符,即tab,缩进四个字符 \n表示回车换行
print(type(df))
print(df.head()) #…
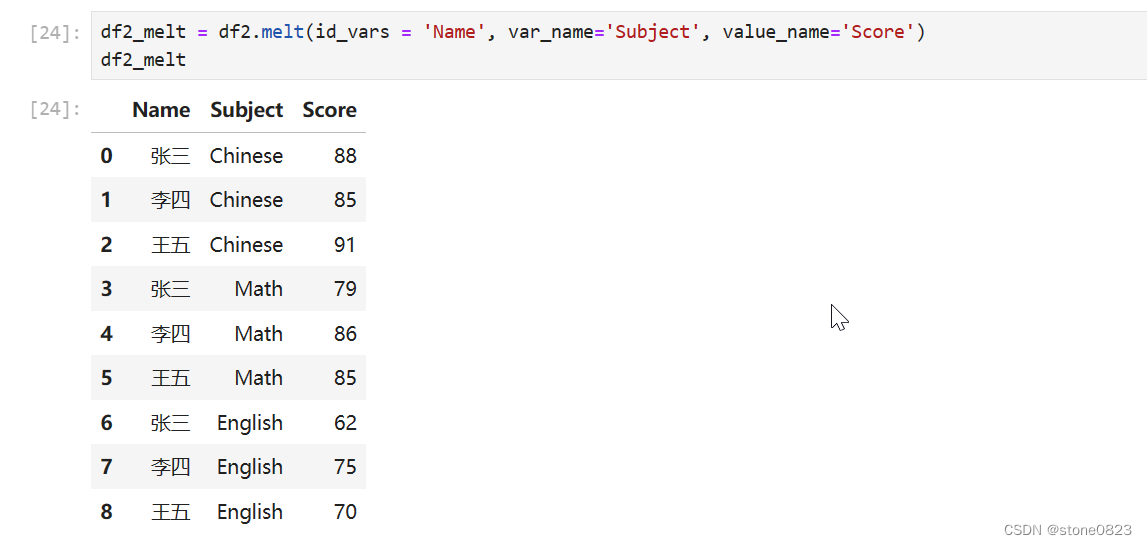
pandas 数据透视和逆透视
本篇介绍 pandas 数据重塑的几个有用变换。假设我们有学生语数外考试的成绩数据,大家常见的是这种格式: 如果数据放在数据库中,下面的格式比较符合数据库范式: 现在,任务来了。要实现由图一向图二的变换,传…

数据分析-Pandas如何观测数据的中心趋势度
数据分析-Pandas如何观测数据的中心趋势度
数据分析和处理中,难免会遇到各种数据,那么数据呈现怎样的规律呢?不管金融数据,风控数据,营销数据等等,莫不如此。如何通过图示展示数据的规律?
数据…
【四 (5)数据可视化之 Pyecharts常用图表及代码实现 】
目录 文章导航一、介绍[✨ 特性]二、安装Pyecharts三、主题风格四、占比类图表1、饼图2、环形图3、玫瑰图4、玫瑰图-多图5、堆叠条形图6、百分比堆叠条形图 五、比较排序类1、条形图2、雷达图3、词云图4、漏斗图 六、趋势类图表1、折线图2、堆叠折线图3、面积图4、堆叠面积图 七…

python-pandas基础学习
可参考: pandas:http://pandas.pydata.org/docs/user_guide/10min.html
一、基础知识 DataFrame 方法,可以将一组数据(ndarray、series, map, list, dict 等类型)转化为表格型数据 import pandas as pd
data {name: …
【EXCEL自动化07】用pandas库实现vlookup函数功能
🔥学好办公自动化,帮你节省更多宝贵的时间 🔥这个专栏收录python办公自动化的实操案例,利用python实现高效的办公自动化 🔥实现excel,word,文件批处理等自动化操作 使用pandas库来实现Excel中VLOOKUP函数的功能。
需要安装pandas库。有时直接下载会失败,会提示先安…
pandas去重、删除重复数据之duplicated()
pandas去重、删除重复数据之duplicated 1.pandas中重复索引问题2.pandas删除重复数据行3.drop_duplicates()函数的语法4.案例:pandas数据处理——取出重复数据 1.pandas中重复索引问题
df df[~df.index.duplicated()]2.pandas删除重复数据行
# 首先导入常用的两个…

031—pandas 读取解析实验室数据至DataFrame
前言
某个科研实验室在进行一项物理实现,实验仪器会输出一个 txt 文本的数据,研究人员需要从这个文本中将数据结构化才能进行进行统计分析。 在为个解析和分析过程中,他们选择了 Python 的 pandas 库来完成这些操作。我们今天来完成这这个 t…
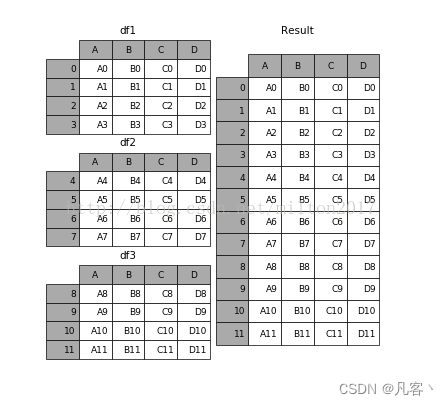
pandas用法-详解教程
pandas用法-详解教程 一、生成数据表二、数据表信息查看三、数据表清洗四、数据预处理五、数据提取六、数据筛选七、数据汇总八、数据统计九、数据输出 一、生成数据表
1、首先导入pandas库,一般都会用到numpy库,所以我们先导入备用:
impor…
Pandas追加写入文件的时候写入到了第一行
# 原代码
def find_money(file_path, account, b_account, money, type_word, time):file pd.read_excel(file_path)with open(money.csv, a, newline, encodingutf-8) as f:for i in file.index:省略中间的代码if 省略中间的代码:file.loc[[i]].to_csv(f,indexFalse)find_sam…
pyDAL一个python的ORM(补充1) pyDAL与pandas
pandas是当前最流行的python数据分析处理的工具,dataframe是pandas最常用的数据对象,生成dataframe通常的方法通常为:
1、文件读取
使用read()方法,读取各种csv、excel、html、json等文件;
2、连接数据库࿰…
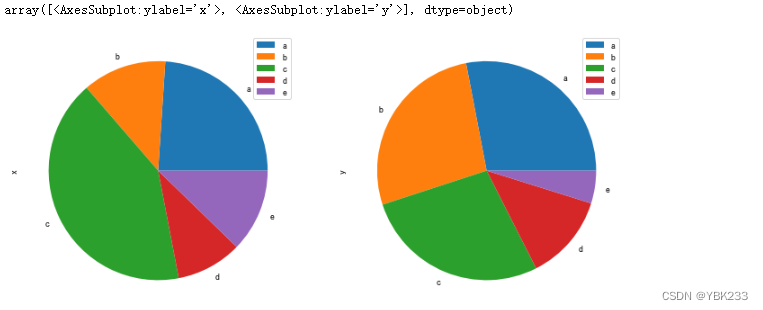
Python可视化之pandas
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1.解决坐标轴刻度负号乱码2.解决中文乱码问题3.折线图Series.plot()&DataFrame.plot()4.条形图5.箱线图6.区域面积图(堆积折线图)7.散点…

项目实战 | 使用python分析Excel销售数据(用groupby)
项目实战 | 使用python分析Excel销售数据 本文目录:
零、00时光宝盒
一、提出问题
二、理解数据
2.1、安装python读取excel文件的库
2.2、查看excel表的字段名和前几行记录
2.3、查看excel表结构
2.4、查看索引
2.5、查看每一列的列表头内容
2.6、查看每一…
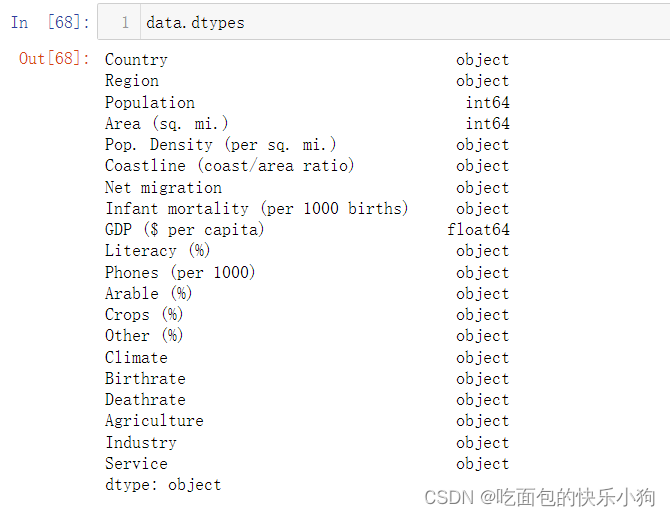
Pandas学习笔记——第二弹
在用正则表达式对数据进行filtering的时候,出现字符串和整数变量不匹配的问题,例如: 给3加上引号就好了:3 但是为什么10000不需要加引号,而3需要呢?这是因为他们的变量类型不一样的,于是总结一下…
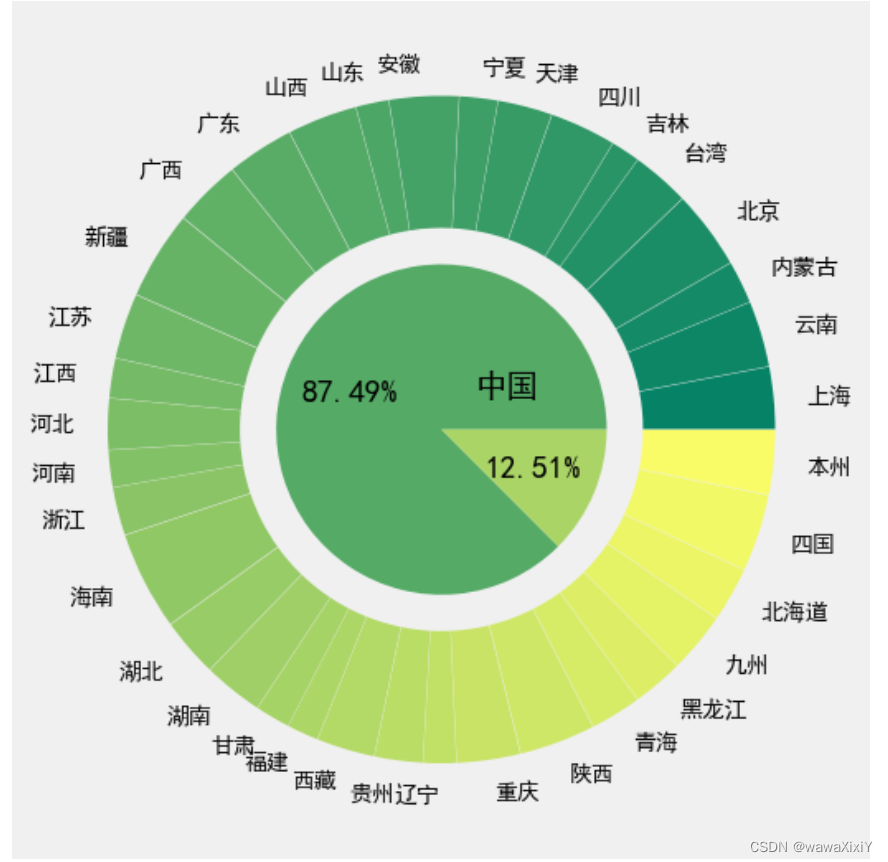
pandas(day6 图表)
一. 计算效率
1. 测量代码运行时间 %%time %%timeit
单纯计算 代码块执行的时长
%%time
_sum(np.arange(6))
CPU times: total: 0 ns
Wall time: 1.66 ms用于多次运行代码块并计算平均执行时间
%%timeit
_sum(np.arange(6))738 ns 10.7 ns per loop (mean std. dev. of 7…

重新温习广软puthon爬虫技术。
下面是我不断试错的一个过程,好多知识点全忘记了,只能不断调实例,不断优化,重构,实现自己的需求。下面是我的运行截图。还是导包的问题。 个人感觉关键的还是这几部,被划了下划线的,存在问题&a…
pandas (day4)
一. 找到各个城市中销售额 第二 的订单
1.1 获取数据
# 先将三个excel 进行融合 一个excel 里面有三个 sheet
data pd.read_excel("./teacher/电商数据.xlsx",sheet_name["订单信息","订单详情","地区信息"])
df pd.merge(pd.me…

【深耕 Python】Data Science with Python 数据科学(8)pandas数据结构:Series和DataFrame
写在前面
关于数据科学环境的建立,可以参考我的博客:
【深耕 Python】Data Science with Python 数据科学(1)环境搭建
往期数据科学博文:
【深耕 Python】Data Science with Python 数据科学(2…
pandas(day5)
一. 检测重复值
1.1 检测
data pd.read_csv("./teacher/订单数据.csv")检测行与行之前是否有重复值
data.drop_duplicates()检测 列是否有重复值出现, keep first 从前往后判定 , last是从后往前判定data.drop_duplicates(subset["产…
Python使用pandas库,其中的DataFrame可以看作是一个二维的、大小可变的、有潜在异构类型列的表格型数据结构
Python的pandas库是一个非常强大的数据处理工具,其中的DataFrame对象更是其核心组件。DataFrame可以看作是一个二维的、大小可变的、有潜在异构类型列的表格型数据结构。你可以把它想象成一个Excel表格,有行有列,可以存储各种类型的数据。
下…
七.pandas处理第三方数据
目录
七.pandas处理第三方数据
1.Pandas读取文件
1.1 csv文件操作
1.1.1 CSV文件读取
自定义索引(inde_col)
查看每一列的dtype
更改文件标头名(列的标签)
跳过指定的行数
1.1.2 CSV文件写入
1.2 Excel文件操作
1.2.1 Excel文件读取
1.2.2 Excel文件写入
1.3 SQL操…
深入理解 Pandas 中的 groupby 函数
groupby 函数是 pandas 库中 DataFrame 和 Series 对象的一个方法,它允许你对这些对象中的数据进行分组和聚合。下面是 groupby 函数的一些常用语法和用法。
对于 DataFrame 对象,groupby 函数的语法如下:
DataFrame.groupby(byNone, axis0…
Python基础知识+WebAPI
一. series 变 dataFrame
代码:
print("Before reset_index:")print(results)results results.reset_index()results.columns [date, data_value]print("\nAfter reset_index and rename columns:")print(results) Before reset_index: dat…

用讲故事的方式学Pandas的数据结构之Series
在一个遥远的数据王国中,有一个被称为Pandas的魔法图书馆,它拥有处理数据的强大力量。图书馆里有三位伟大的守护者,人们称他们为“数据处理三剑客”:Numpy,Pandas,和Matplotlib。今天,我们将聚焦…
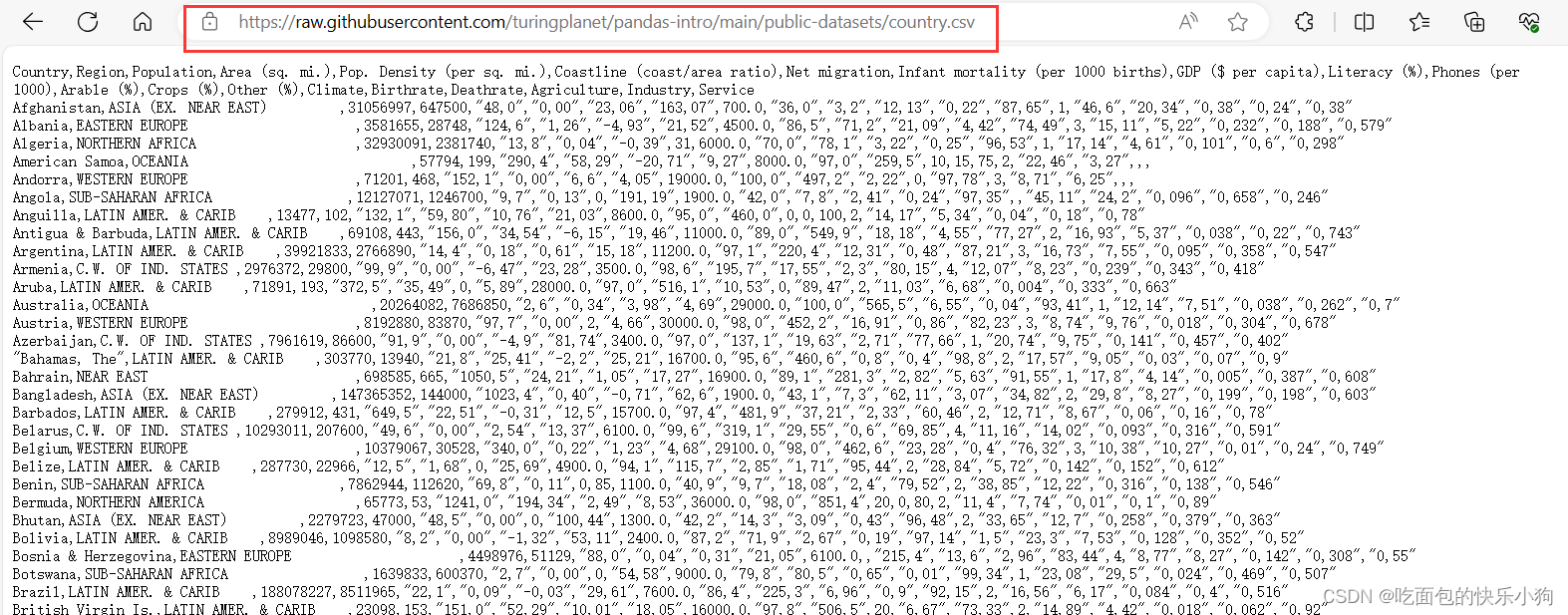
Pandas学习笔记——第一弹
问题:
URLError: <urlopen error [WinError 10061] 由于目标计算机积极拒绝,无法连接。>ParserError: Error tokenizing data. C error: Expected 1 fields in line 41, saw 16今天开始学习Pandas啦!
跟着一个博主的视频熟练Pandas的…
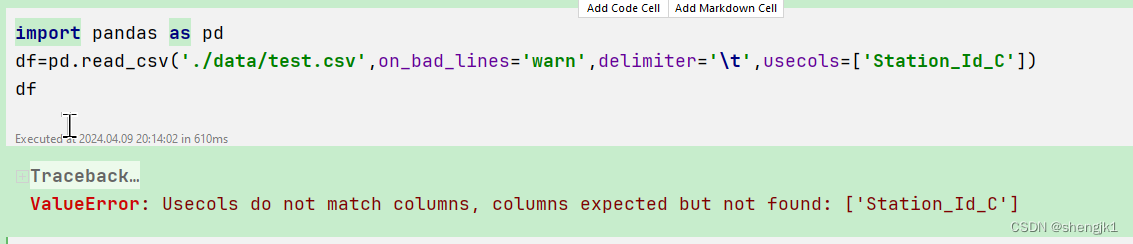
关于pandas 无法读取 csv 文件数据的解决方式
你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益:
了解大厂经验拥有和大厂相匹配的技术等
希望看什么,评论或者私信告诉我! 文章目录 …

Python数学建模-2.5Pandas库介绍
2.5.1Pandas基本操作
Pandas是一个强大的Python数据分析库,它提供了快速、灵活且富有表现力的数据结构,设计初衷是为了处理关系型或标记型数据。Pandas的基本操作涵盖了数据的读取、处理、筛选、排序、分组、合并以及可视化等多个方面。
以下是一些Pan…
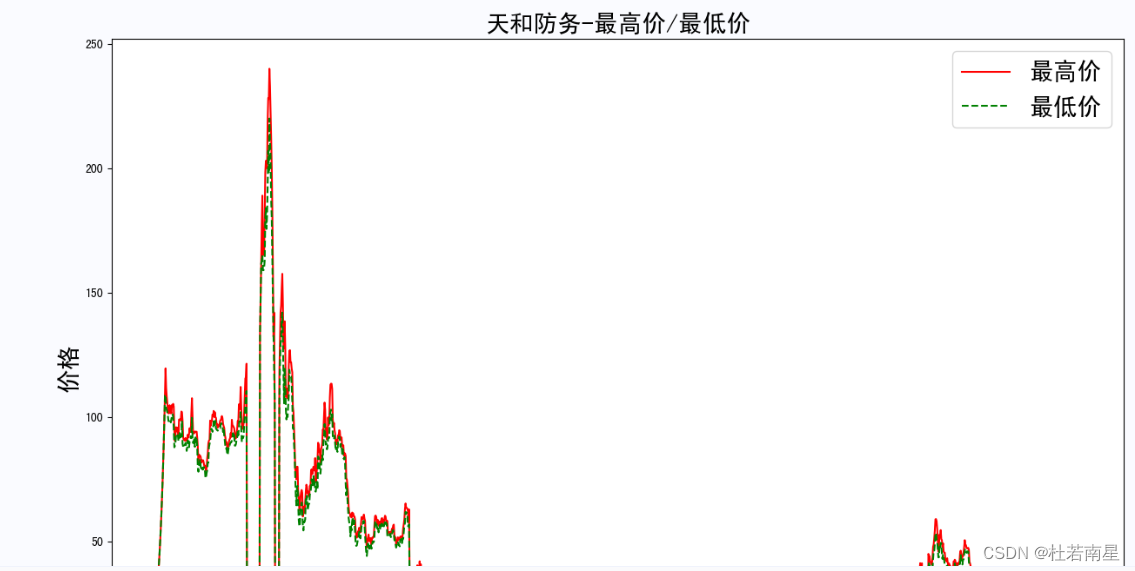
百度松果菁英班——机器学习实践六:股票行情爬取与分析
飞桨AI Studio星河社区-人工智能学习与实训社区
这篇文章好像有点大,所以上边网页点进去是看不到的,进入环境之后就能看了
🥪必要包的下载导入
!pip install fake_useragent
!pip install bs4
!cp /home/aistudio/simhei.ttf /opt/conda/e…