面试题
newman
缓存
jstl
合并查询
趣味python
ROS
js
基础入门
类似LABVIEW
big data
实时音视频
supervisor
svn
IT难
koa
PIXIjs
哈夫曼树
预处理器
optee
数据同步
2024/4/12 10:17:58
DataX-一款稳定高效的数据同步工具-从安装、启动、配置、使用总结,看这篇让你一步到位
前言
大数据部门现阶段ETL按同步方式分为两种:
实时同步:DTS、CloudCanal离线同步:dataworks-DI节点
但CloudCanal在使用中出现了部分问题,归纳总结后主要为以下几点:
部分使用场景获取不到binlog点位停止任务&…

C#使用互斥锁lock同步线程数据
Java中的runnable方法的使用实例
https://blog.csdn.net/number1killer/article/details/79113822
Python线程指南(线程的:原理、管理、多线程、实例)
https://blog.csdn.net/number1killer/article/details/79353630

MySQL 数据同步到 Redis 缓存方案
为了减轻数据库的压力,我们一般会通过加入缓存的方式来解决,本着
先查询缓存在查询数据库的原则,那么数据库中的数据如何写入缓存则成为首要问题。本文就以redis缓存为例带着大家一起了解一下数据同步的方案。
MySQL与Redis缓存的同步的两种…

信息系统数据同步解决方案
实施数据同步解决方案时,重要的是确保数据同步是安全的、可靠的,并且能够适应系统变化。定期测试和监控数据同步过程,以确保其稳定运行,并随着需求的变化进行适当的调整和优化。
应用场景:信息系统A和信息系统B实现员…
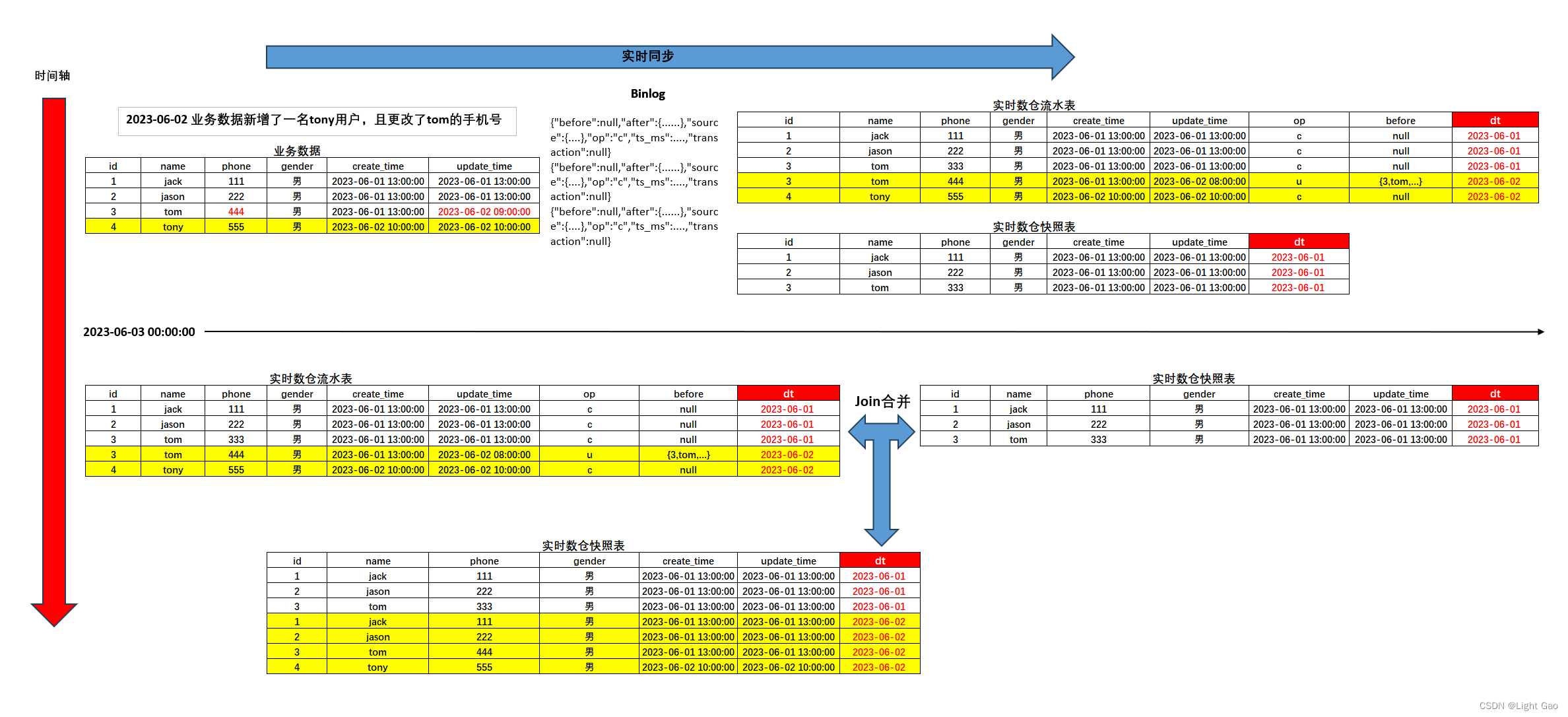
Flink实时数仓同步:快照表实战详解
一、背景
在大数据领域,初始阶段业务数据通常被存储于关系型数据库,如MySQL。然而,为满足日常分析和报表等需求,大数据平台采用多种同步方式,以适应这些业务数据的不同存储需求。这些同步存储方式包括离线仓库和实时仓…
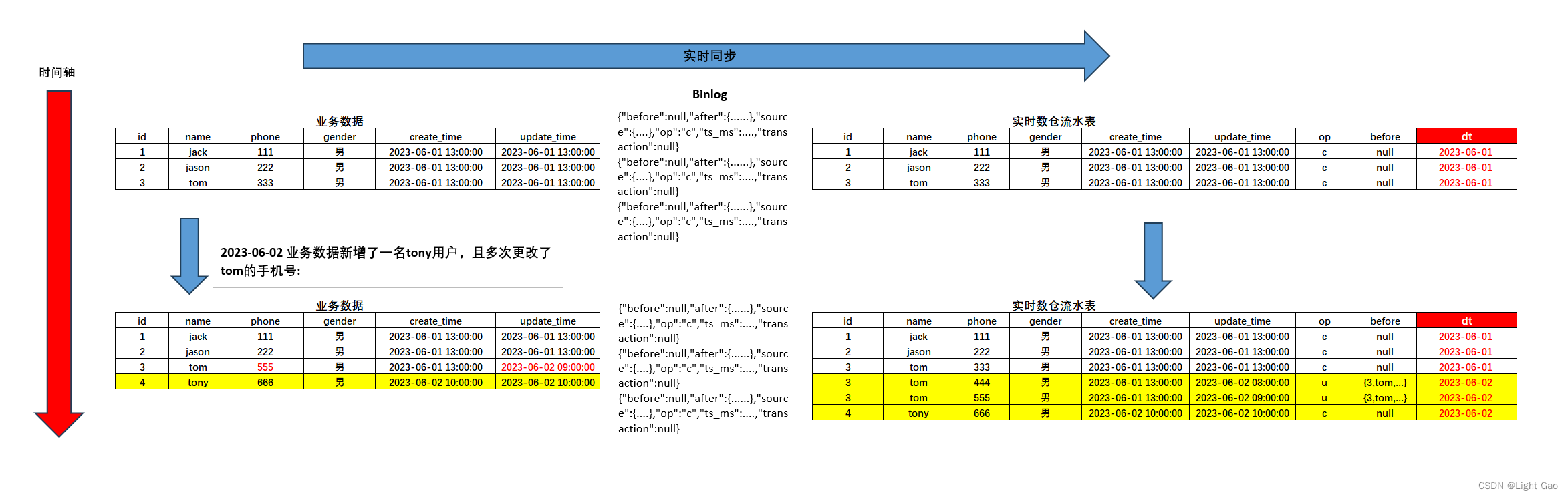
Flink实时数仓同步:流水表实战详解
一、背景
在大数据领域,初始阶段业务数据通常被存储于关系型数据库,如MySQL。然而,为满足日常分析和报表等需求,大数据平台采用多种同步方式,以适应这些业务数据的不同存储需求。这些同步存储方式包括离线仓库和实时仓…
ETL与抖音数据同步,让数据流动无阻
在当今数字化时代,数据的价值日益凸显,企业需要从各种渠道获取有关用户行为、市场趋势和竞争对手活动的数据。作为一家专注于数据集成和转换的领先平台,ETLCloud为企业提供了强大的数据同步和转换功能。而与此同时,抖音作为一款热…
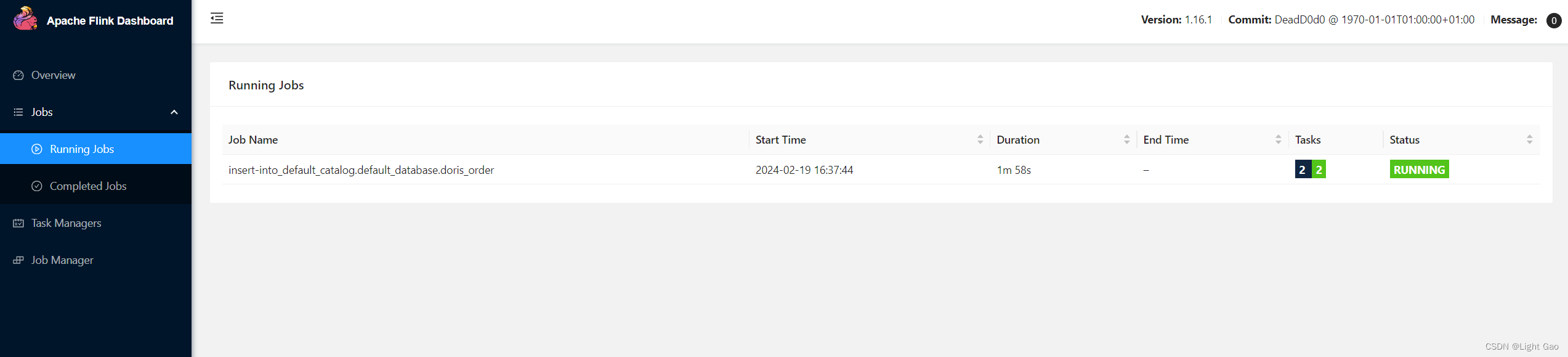
Flink实时数仓同步:切片表实战详解
一、背景
在大数据领域,初始阶段业务数据通常被存储于关系型数据库,如MySQL。然而,为满足日常分析和报表等需求,大数据平台采用多种同步方式,以适应这些业务数据的不同存储需求。
一项常见需求是,业务使用…
Spring Boot业务系统如何实现海量数据高效实时搜索
1.概述
我们都知道随着业务系统的发展和使用,数据库存储的业务数据量会越来越大,逐渐成为了业务系统的瓶颈。在阿里巴巴开发手册中也建议:单表行数超过500万行或者单表容量超过2GB才推荐进行分库分表,如果预计三年后数据量根本达…

【大数据】Kafka 入门简介
Kafka 入门简介 1.什么是 Kafka2.Kafka 的基本概念3.Kafka 分布式架构4.配置单机版 Kafka4.1 下载并解压包4.2 启动 Kafka4.3 创建 Topic4.4 向 Topic 中发送消息4.5 从 Topic 中消费消息 5.实验5.1 实验一:Python 实现生产者消费者5.2 实验二:消费组实现…
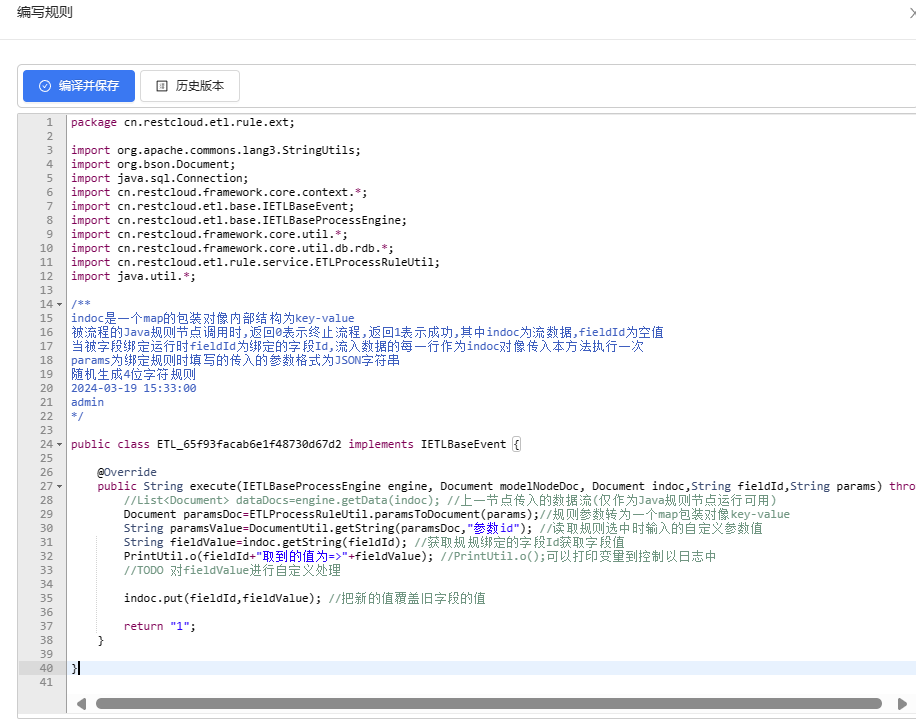
ETL中如何自定义规则
一、ETL中的规则
在使用规则之前我们先来了解一下什么是规则,ETL中规则在很多组件中都能看见,可以理解为按照事前约定好的逻辑去执行,规则可以使得数据更加的规范统一,同时也不需要去纵向的修改底层代码,只需要动态编…

DataX 概述、部署、数据同步运用示例
文章目录 什么是 DataX?DataX 设计框架DataX 核心架构DataX 部署DataX 数据同步 MySQL —> HDFSDataX 数据同步 HDFS —> MySQLDataX 优化同步 MySQL 中 NULL 值数据到 HDFS 出现错误配置文件变量传参 什么是 DataX?
DataX 是阿里巴巴集团开源的、…

DataX源码分析 Channel
系列文章目录
一、DataX详解和架构介绍 二、DataX源码分析 JobContainer 三、DataX源码分析 TaskGroupContainer 四、DataX源码分析 TaskExecutor 五、DataX源码分析 reader 六、DataX源码分析 writer 七、DataX源码分析 Channel 文章目录 系列文章目录前言MemoryChannelChann…
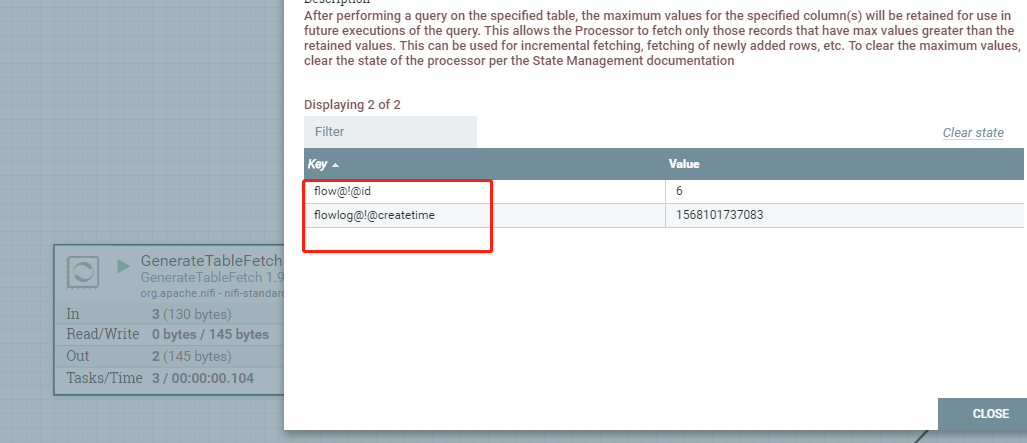
【大数据】NiFi 中的处理器(一):GenerateTableFetch
NiFi 中的处理器(一):GenerateTableFetch 1.简介2.应用场景3.示例3.1 案例一:无输入流文件,来源表含增量字段3.2 案例二:无输入流文件,不含增量字段3.3 案例三:无输入流文件…
关于达梦DMHS同步性能提升的几个参数介绍
1、事务缓存相关参数
EXEC模块在处理事务时,首先要对事务数据进行收集归类,通过事务ID把同一个事务的操作都归到一起。EXEC模块在初始化时,根据exec_sql参数指示的内存池大小来初始化内存池,收集事务操作时,都将从该内…

【大数据】NiFi 的基本使用
NiFi 的基本使用 1.NiFi 的安装与使用1.1 NiFi 的安装1.2 各目录及主要文件 2.NiFi 的页面使用2.1 主页面介绍2.2 面板介绍 3.NiFi 的工作方式3.1 基本方式3.2 选择处理器3.3 组件状态3.4 组件的配置3.4.1 SETTINGS(通用配置)3.4.2 SCHEDULING࿰…
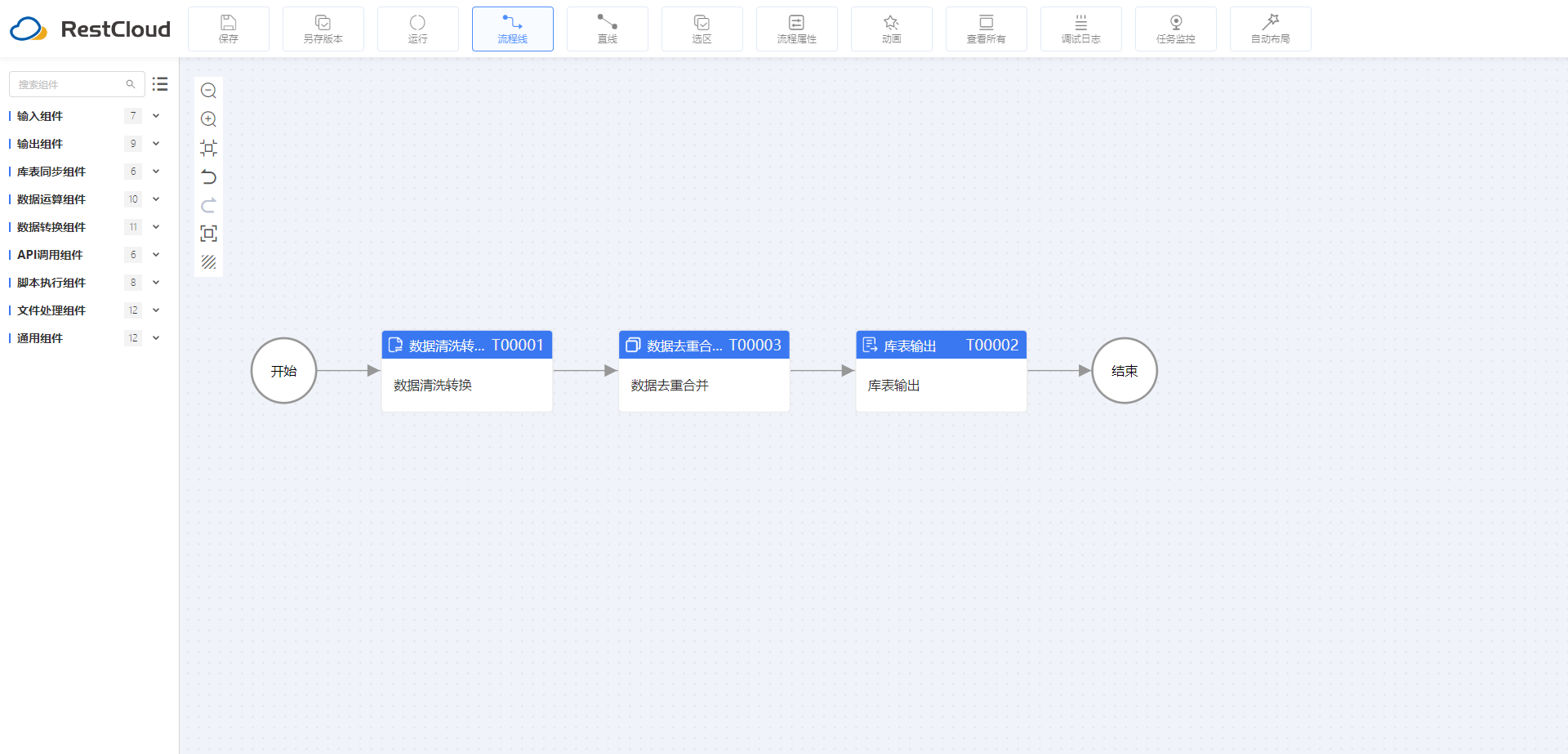
通过ETLCloud CDC构建高效数据管道解决方案
随着企业数据规模的快速增长和多样化的数据,如何高效地捕获、同步和处理数据成为了业务发展的关键。本文将介绍如何利用ETLCloud CDC技术,构建一套高效的CDC数据管道,实现实时数据同步和分析,助力企业实现数据驱动的业务发展。 一…
如何源码编译seaTunnel
如何源码编译seaTunnel
参考Set Up Develop Environment
编译前准备
下列软件需要提前安装好
GitJava ( JDK8/JDK11) 并设置JAVA_HOME 环境变量Scala (只支持 scala 2.11.12 )JetBrains IDEA .
下载源码并编译
git clone gitgithub.com:apache/seatunnel.git
cd seatunne…
一镜到底 ElasticSearch 数据迁移同步技术
简介
CloudCanal 对于 Elasticsearch 的支持经历了很多轮迭代,版本一路从 6.x,7.x 支持到 8.x 版本,也适配了其纷繁多样的 API。
因为 Elasticsearch 是一个相当流行的、实时的、并且具备一定不可替代能力的搜索引擎,所以很有必要对比下市面…
Mysql配置主从同步流程
一、设置主服务器:
1、在主数据库中打开MySQL配置文件(my.cnf或my.ini),找到并编辑以下配置项:
[mysqld]
server-id1
log-binmysql-bin
binlog-formatrow
PS:
linux服务器的MySQL配置文件要么在安装目录下&#x…

深入解析 Flink CDC 增量快照读取机制
一、Flink-CDC 1.x 痛点
Flink CDC 1.x 使用 Debezium 引擎集成来实现数据采集,支持全量加增量模式,确保数据的一致性。然而,这种集成存在一些痛点需要注意: 一致性通过加锁保证:在保证数据一致性时,Debez…

【大数据】Doris 架构
Doris 架构 Doris 的架构很简洁,只设 FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维,FE、BE 都可线性扩展。 ✅ Frontend(FE࿰…

【大数据】NiFi 中的处理器(二):PutDatabaseRecord
NiFi 中的处理器(二):PutDatabaseRecord 1.基本介绍2.属性配置3.连接关系4.应用场景 1.基本介绍
PutDatabaseRecord 处理器使用指定的 RecordReader 从传入的流文件中读取(可能是多个,说数组也成)记录。这…
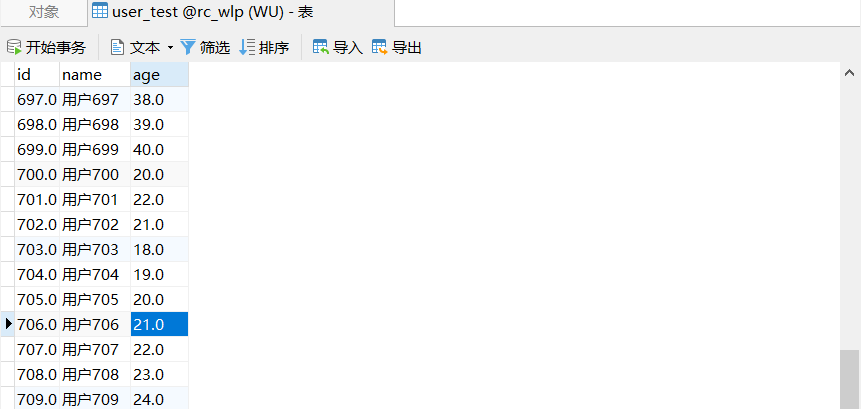
解锁ETLCloud中Kettle的用法
随着大数据时代的到来,数据的处理和管理成为各行各业不可或缺的一环。ETL(Extract-Transform-Load)工具作为数据处理的重要环节,扮演着将数据从源端抽取出来、经过转换处理,最终加载至目标端的关键角色。在众多ETL工具…
采用ODP.NET 批量进行数据同步
因开发、测试场景经常需要模拟机生产环境的数据,原同事开发了一个ado.net图形化同步工具,对非技术人员操作友好,但对技术员使用并不方便,每次同步需源库数据与目标的数据源字段进行配置,且同步大数据时慢,因…
Maxwell与canal工具对比
Maxwell和Canal是两种不同的数据同步工具,都是在数据迁移、数据同步、数据分发等领域发挥作用的工具,但是它们之间存在一些差异。
Maxwell
Maxwell是一种开源的MySQL数据库同步工具,它可以将MySQL数据库的binlog转化为JSON格式,…

【大数据】NiFi 中的重要术语
NiFi 中的重要术语 1.Flow Controller2.Processor3.Connection4.Controller Service5.Process Group6.FlowFile 那些一个个黑匣子称为 Processor,它们通过称为 Connection 的队列交换名为 FlowFile 的信息块。最后,FlowFile Controller 负责管理这些组件…

数据集成时表模型同步方法解析
01 背景介绍
数据治理的第一步,也是数据中台的一个基础功能 — 即将来自各类业务数据源的数据,同步集成至中台 ODS 层。业务数据源多种多样,单单可能涉及到的主流关系型数据库就有近十种。功能更加全面的数据中台通常还具有对接非关系型数据…
Spring Cloud学习(十一)【深入Elasticsearch 分布式搜索引擎03】
文章目录 数据聚合聚合的种类DSL实现聚合RestAPI实现聚合 自动补全拼音分词器自定义分词器自动补全查询completion suggester查询RestAPI实现自动补全 数据同步数据同步思路分析实现elasticsearch与数据库数据同步 集群搭建ES集群创建es集群集群状态监控创建索引库1)…
Maxwell 数据同步使用教程
Maxwell 数据同步使用教程
Maxwell 是一个开源的 MySQL 数据同步工具,它可以提供可靠的、实时的数据复制服务。它的特点是将 MySQL 的 binlog 解析成易于理解、易于使用的 JSON 格式,并将其发送到 Kafka 或其他消息队列,方便消费者进行数据处…
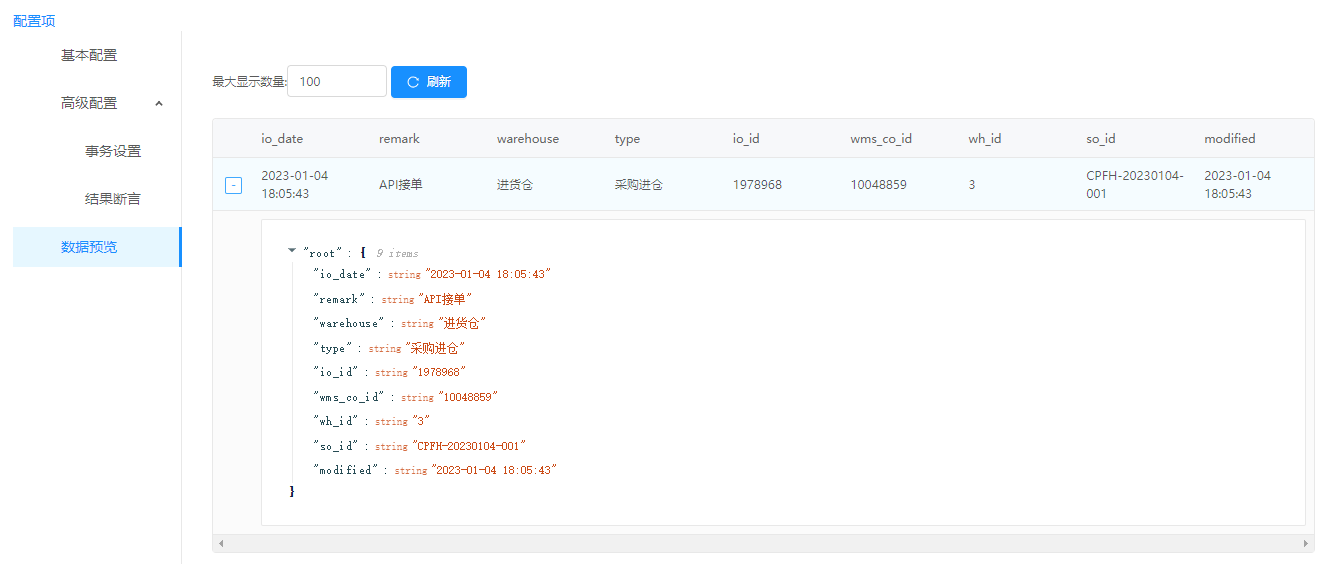
快速拉取聚水潭单据的ETL工具
聚水潭介绍
聚水潭平台则是国内较为出名的电商ERP平台,为企业提供了便捷的销售和管理服务,专注于提高交易效率,但是如何将数据快速同步到其他系统一直是很多企业的痛点。
ETLCloud数据集成平台提供了丰富的数据分析工具和算法模型ÿ…
【JOB】如何写好补充类JOB和数据迁移类JOB?
目录标题准备阶段业务场景归类需要考虑的因素框架设计业务代码代码模板补偿类job代码模板业务代码SQL语句数据迁移类job代码模板总结准备阶段
业务场景归类
补偿类job。补偿类job典型的特点是带有‘status’状态,比如:正常业务status应该从‘init’–&…
![[沉淀之华] 自研基于SpringBoot Mybaits 构建低代码数据治理脚手架分享:涵盖数据同步、数据比对、数据归档、数据恢复为一体](https://img-blog.csdnimg.cn/direct/1e579858424441d69eae59ceb64adfd3.png)
[沉淀之华] 自研基于SpringBoot Mybaits 构建低代码数据治理脚手架分享:涵盖数据同步、数据比对、数据归档、数据恢复为一体
文章目录 成果演示背景整体能力功能描述相关细节安装使用 成果演示
Github地址:数据治理脚手架 wiki:kg-ctl-core使用文档 背景
为什么要做这个? 一个老生常谈且不得不谈问题:随着业务日益发展,如果不做数据迁移&…
渔业安全生产综合管理指挥系统-航迹数据优化方案
文章目录 引言I 轨迹数据模型II 轨迹信息索引III 数据同步方案3.1 多服务器多表同步3.2 增量数据同步3.3 执行IV 配置ESV 团队建设5.1 前端(web GIS)5.2 后端(Java)see also引言
背景: 目前系统查询轨迹数据比较慢的原因是没有进行读写分离,轨迹数据的查询和写入都是SQL…
基于Logstash的动态表同步方案
文章目录 引言I 动态表的同步1.1 利用数据库函数进行动态表名拼接1.2 利用shell脚步进行动态日期表名拼接1.3 方案小结II 增量同步2.1 tracking_column 增量指标字段名2.2 使用多个字段来生成document ID2.3 doc_as_upsertIII 同步多数据表see also术语引言

【大数据】CDC 技术:变化数据捕获
CDC 技术:变化数据捕获 1.什么是 CDC ?2.批处理 vs CDC3.四种 CDC 的实现方法3.1 表元信息 Table metadata3.2 表求差 Table differences3.3 数据库触发器 Trigger-based CDC3.4 数据库事务日志 Log-based CDC 4.Oracle CDC 详解4.1 Oracle CDC 机制4.1.…

多渠道数据采集的方法介绍
多渠道数据采集是指通过多种渠道收集与消费者相关的数据,包括线上线下数据、不同平台数据等。多渠道数据采集对于企业来说非常重要,可以帮助企业更好地了解消费者需求和行为,优化营销策略,提高销售效果和客户满意度。本文将为您介…
数据库数据同步策略一
一、场景 近来遇到一个MySQL同步数据的问题,需要在测试环境同步60多万的数据到生产环境,要求生产的数据不受影响。生产环境存在数据时,需保留生产的数据或者同步中测试环境存在的数据与生产的数据整合为一条唯一的数据。涉及两张表࿱…

强大的多平台数据同步工具:SyncMate for Mac
SyncMate for Mac是一个简单易用的应用程序,它可以让你在Mac、iOS设备、Android设备和其他外部存储设备之间同步数据。无论你是要同步联系人、日历、音乐、视频、照片还是其他文件,SyncMate都能够轻松帮你完成。
这个应用程序不仅可以实现设备之间的同步…

【大数据】美团 DB 数据同步到数据仓库的架构与实践
美团 DB 数据同步到数据仓库的架构与实践 1.背景2.整体架构3.Binlog 实时采集4.离线还原 MySQL 数据5.Kafka2Hive6.对 Camus 的二次开发7.Checkdone 的检测逻辑8.Merge9.Merge 流程举例10.实践一:分库分表的支持11.实践二:删除事件的支持12.总结与展望 1…

【大数据】Kafka 数据存储
Kafka 数据存储 1.文件目录2.日志分段3.日志索引3.1 偏移量索引3.2 时间戳索引 4.日志清理4.1 日志删除4.1.1 基于时间4.1.2 基于日志大小4.1.3 基于日志起始偏移量 4.2 日志压缩 1.文件目录
Kafka 中的消息是存储在磁盘上的,一个分区副本对应一个 日志(…
ArkTS@State 数组无法触发重绘【Bug已解决-鸿蒙开发】
文章目录 项目场景:问题描述:原因分析:解决方案:此Bug解决方案总结文章涉及知识点@State装饰器使用规则说明项目场景:
ArkTS 中使用 @State 注解的数组无法正确触发重绘的问题。尽管能够捕获到值的变更,但页面却没有相应的变化。 本人遇到了这个bug,在结合了他人相同情…
MySQL同步ES的几种方案
MySQL数据同步ES的几种方案 1. 同步双写 与业务耦合深,且业务响应时间长
2. 异步双写 这时可以使用类似MQ这样的中间件,业务主写时向MQ发送一条信息,再由一个聚合服务区消费,最终同步到ES
3. 定时任务 不好配置时间,…
DataX数据同步(全量)
1. DataX简介
1.1 DataX概述 DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。 源码地址:https://github.com/alibaba/Dat…
sqoop传递数据实践
应用场景:
1将原有关系数据库的数据传递到大数据平台如hive、hbase。
2将大数据平台的数据传递到关系数据库中。
简单应用:表对表的同步。
复杂应用:在同步时可以通过query-sql来指定所要传递的数据。
所有红字“注意”都是坑࿰…
游戏数据传输帧同步中,自定义浮点(float)、二维向量(vector2)、三维向量(vecter3)、四元数(Quaternion)的数据类型的实现
由于帧同步需要各客户端的浮点数不能出现误差,所以需要使用经过处理过的浮点数。 不只是浮点数本身,所有基于浮点数实现的数据类型都要经过处理,包括Vector2、Vector3、Quaternion等等
由csharp代码实现,直接拖入unity可直接使用…

从 MySQL 到 DolphinDB,Debezium + Kafka 数据同步实战
Debezium 是一个开源的分布式平台,用于实时捕获和发布数据库更改事件。它可以将关系型数据库(如 MySQL、PostgreSQL、Oracle 等)的变更事件转化为可观察的流数据,以供其他应用程序实时消费和处理。本文中我们将采用 Debezium 与 K…

【大数据】常见的数据抽取方法
常见的数据抽取方法 1.基于查询式的数据抽取1.1 触发器方式(又称快照式)1.2 增量字段方式1.3 时间戳方式1.4 全表删除插入方式 2.基于日志的数据抽取 数据抽取 是指从源数据源系统抽取需要的数据。实际应用中,数据源较多采用的是关系数据库。…
apache seatunnel web 安装部署
下载文件
apache-seatunnel-2.3.3-bin.tar.gz apache-seatunnel-web-1.0.0-bin.tar.gz download_datasource.sh
准备工作 解压文件tar -zxvf apache-seatunnel-2.3.3-bin.tar.gz
tar -zxvf apache-seatunnel-web-1.0
鸿蒙开发:UIAbility组件与UI的数据同步-使用EventHub进行数据通信【鸿蒙专栏-21】
文章目录 ArkTS应用模型中UIAbility组件与UI的数据同步使用EventHub进行数据通信使用globalThis进行数据同步1. UIAbility和Page之间使用globalThis2. UIAbility和UIAbility之间使用globalThis3. 使用globalThis的注意事项4. 使用globalThis的注意事项同名对象覆盖导致问题的场…
Bash openldap同步AD组织数据
将AD的ou同步到openldap(可支持全量同步和增量同步)
整体思路如下:
从ad导出所有的数据,然后进行参数替换以及处理,处理后的文件称为A;从openldap导出所有的数据,然后进行参数替换以及处理&am…

【ETL工具】Datax-ETL-SqlServerToHDFS
🦄 个人主页——🎐个人主页 🎐✨🍁 🪁🍁🪁🍁🪁🍁🪁🍁 感谢点赞和关注 ,每天进步一点点!加油!&…
【大数据 - Doris 实践】数据表的基本使用(五):ROLLUP
数据表的基本使用(五):ROLLUP 1.基本概念2.Aggregate 和 Uniq 模型中的 ROLLUP2.1 获得每个用户的总消费2.2 获得不同城市,不同年龄段用户的总消费、最长和最短页面驻留时间 3.Duplicate 模型中的 ROLLUP3.1 前缀索引3.2 ROLLUP 调…
Debezium 数据同步
这个中间件可以对接不同的数据源,目前支持主流database,比如mysql,oracle,postgresql等等,还在调研实践中,与flink结合的比较完美,后期大概率会往这个方向推导
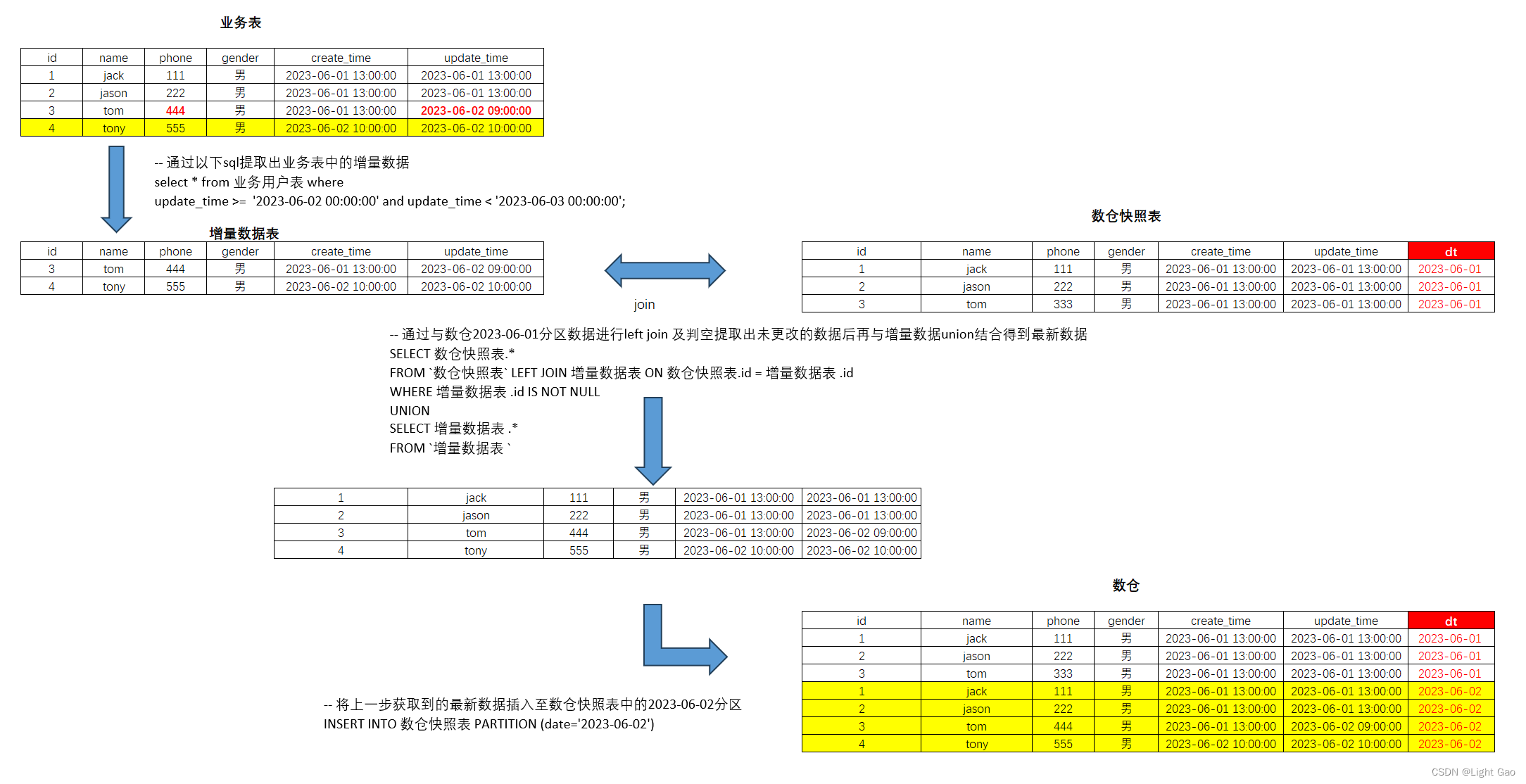
数仓日常维护:剖析每日增量同步的内部机制
数仓日常维护:剖析每日增量同步的内部机制
一、前言
在现代企业中,离线仓库扮演着不可或缺的角色。它充当着一个数据的中心枢纽,存储和管理着海量的信息。作为企业数据分析、业务决策和预测的基石,离线仓库的重要性不言而喻。
…


花 200 元测试 1300 个实时数据同步任务
背景
对于将数据作为重要生产资料的公司来说,超大规模的数据迁移同步系统( 1k、5k、10k 条同步任务)是刚需。
本文以此为出发点,介绍近期 CloudCanal 所做的一个容量测试:在单个 CloudCanal 集群上创建 1300 实时任务,验证系统是…
![datax插件加载失败(插件[ftpreader,hdfswriter]加载失败)](https://img-blog.csdnimg.cn/direct/7ec8a79bc7024d20be141fa411aabd90.png)
datax插件加载失败(插件[ftpreader,hdfswriter]加载失败)
WARN ConfigParser - 插件[ftpreader,hdfswriter]加载失败,1s后重试… Exception:Code:[Framework-12], Description:[DataX插件初始化错误, 该问题通常是由于DataX安装错误引起,请联系您的运维解决 .]. - 插件加载失败,存在重复插件:/usr/lib/datax/plu…

FlinkCDC系列:通过skipped.operations参数选择性处理新增、更新、删除数据
在flinkCDC源数据配置,通过debezium.skipped.operations参数控制,配置需要过滤的 oplog 操作。操作包括 c 表示插入,u 表示更新,d 表示删除。默认情况下,不跳过任何操作,以逗号分隔。配置多个操作ÿ…
【大数据 - Doris 实践】数据表的基本使用(四):动态分区
数据表的基本使用(四):动态分区 1.原理2.使用方式3.动态分区规则参数3.1 主要参数3.2 创建历史分区的参数3.3 创建历史分区规则3.4 创建历史分区举例3.5 注意事项 4.示例4.1 创建动态分区表4.2 查看动态分区表调度情况4.3 查看表的分区4.4 插…
手把手教您如何在群晖中搭建洛雪音乐同步服务
文章目录 为什么要搭建同步服务器群晖搭建服务器在软件中使用PC端使用移动端使用为什么要搭建同步服务器 您都看搭建服务器了,那至于洛雪音乐是什么就不用我来说了吧!关于为什么要打架同步服务器可以直接参考官方文档说明,这里我就不再赘述了!群晖搭建服务器 这里直接跳过一…

【大数据】NiFi 中的 Controller Service
NiFi 中的 Controller Service 1.Service 简介1.1 Controller Service 的配置1.1.1 SETTING 基础属性1.1.2 PROPERTIES 使用属性1.1.3 COMMENT 页签 1.2 Service 的使用范围 2.全局参数配置3.DBCPConnectionPool 的使用样例4.在 ExcuseGroovyScript 组件中使用 Service 1.Servi…

【大数据】Apache NiFi 数据同步流程实践
Apache NiFi 数据同步流程实践 1.环境2.Apache NIFI 部署2.1 获取安装包2.2 部署 Apache NIFI 3.NIFI 在手,跟我走!3.1 准备表结构和数据3.2 新建一个 Process Group3.3 新建一个 GenerateTableFetch 组件3.4 配置 GenerateTableFetch 组件3.5 配置 DBCP…